
Adam-mini:革新优化器技术的新突破
在深度学习领域,优化器的选择对模型训练的效率和性能至关重要。近期,一种名为Adam-mini的新型优化器引起了研究人员的广泛关注。这个由张宇顺等人开发的优化器,承诺在保持或超越AdamW性能的同时,大幅减少内存占用。让我们深入了解这项创新技术的细节。
Adam-mini的核心思想
Adam-mini的核心思想是通过减少Adam算法中的学习率资源来降低内存占用。具体来说,它主要通过以下两个步骤实现:
- 参数分块:根据Hessian结构相关的原则,将模型参数carefully划分为不同的块。
- 块级学习率分配:为每个参数块分配一个单一但有效的学习率。
通过这种方法,Adam-mini声称可以安全地移除超过90%的学习率资源,同时不会影响模型的性能。

使用Adam-mini
要使用Adam-mini,首先需要安装PyTorch(版本>=1.8.0)。然后,可以通过以下方式来使用这个优化器:
from adam_mini import Adam_mini
optimizer = Adam_mini(
named_parameters = model.named_parameters(),
lr = lr,
betas = (beta1,beta2),
eps = eps,
weight_decay = weight_decay,
dim = model_config.dim,
n_heads = model_config.n_heads,
n_kv_heads = model_config.n_kv_heads,
)
值得注意的是,对于学习率(lr)、weight_decay、beta1、beta2和eps等超参数,开发者建议使用与AdamW相同的值。
Adam-mini的广泛应用
Adam-mini的实现支持多种流行的分布式框架和代码库,包括:
- DDP分布式框架
- FSDP分布式框架
- DeepSpeed
- Huggingface Trainer
- Torchtitan
- LLaMA-Factory
这种广泛的兼容性使得Adam-mini可以轻松集成到各种深度学习项目中。
实际应用案例
为了展示Adam-mini的实际效果,开发者提供了几个具体的应用案例:
-
GPT2预训练:使用NanoGPT代码库在DDP框架下预训练GPT2系列模型(125M-1.5B)。
-
Llama3-8B预训练:使用Torchtitan代码库在FSDP框架下预训练Llama3-8B模型。
-
Llama2-7B监督微调和RLHF:使用ReMax代码库在DeepSpeed框架下对Llama2-7B进行监督微调和RLHF训练。
这些案例不仅展示了Adam-mini在不同规模和类型的模型上的适用性,也证明了其在各种训练任务中的优越性能。
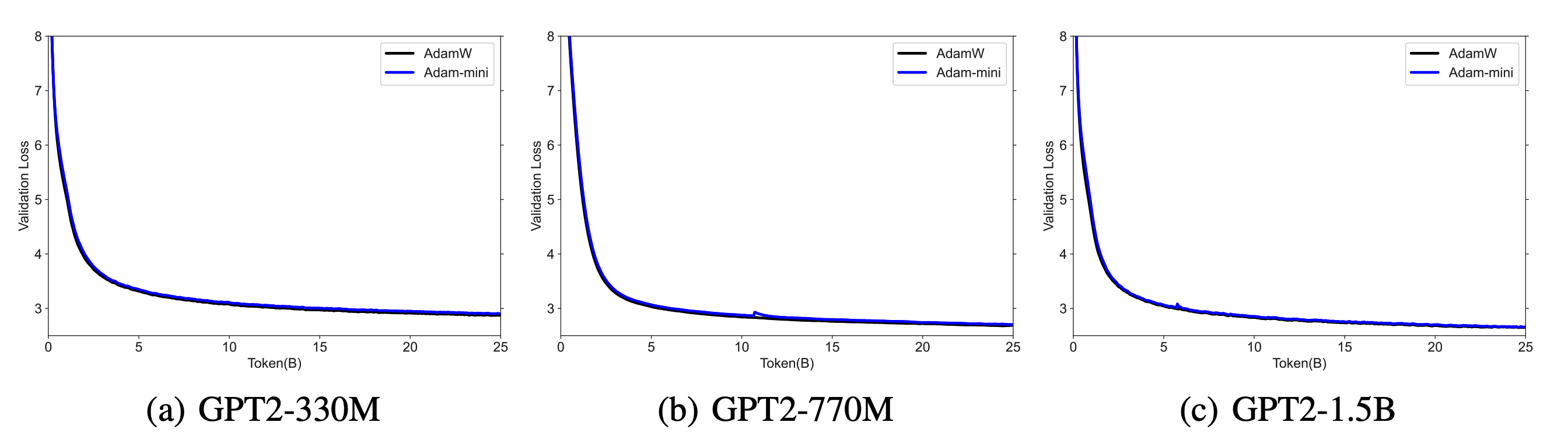
Adam-mini的优势与挑战
Adam-mini的主要优势在于其显著的内存节省。通过减少45%到50%的内存占用,它为大规模模型训练和资源受限设备上的应用开辟了新的可能性。这种内存效率不仅可以加速训练过程,还可以允许研究人员在有限的硬件资源下训练更大的模型。
然而,Adam-mini也面临一些挑战:
-
在复杂优化问题上的表现:对于某些复杂或条件不佳的优化问题,单一的全局学习率可能不如标准Adam中的个别学习率有效。
-
超参数敏感性:Adam-mini的性能可能对初始学习率和动量衰减率等超参数的选择比较敏感,这可能需要更细致的调优过程。
-
与其他内存效率技术的比较:虽然Adam-mini展现出了令人印象深刻的性能,但还需要与其他内存效率优化算法(如MicroAdam或HIFT)进行更全面的比较。
未来展望
Adam-mini的出现为深度学习优化器领域带来了新的思路。随着技术的不断发展,我们可以期待:
-
更广泛的应用:随着更多研究人员和工程师采用Adam-mini,我们可能会看到它在更多领域和任务中的应用。
-
进一步的优化:开发者团队正在持续改进Adam-mini,解决一些现有的限制,如在FSDP框架下保存检查点的问题。
-
与其他技术的结合:Adam-mini可能会与其他内存优化技术结合,进一步提高大规模模型训练的效率。
结论
Adam-mini代表了优化器技术的一个重要进步。通过巧妙地减少学习率资源,它成功地在保持性能的同时大幅降低了内存占用。这不仅为大规模模型训练提供了新的可能性,也为在资源受限环境下进行深度学习研究开辟了新的道路。
随着深度学习模型不断增大,像Adam-mini这样的创新优化器将在推动人工智能技术的发展中发挥越来越重要的作用。研究人员和工程师们可以期待看到Adam-mini在未来带来更多令人兴奋的应用和突破。
对于那些正在寻求提高训练效率或在有限资源下训练大型模型的人来说,Adam-mini无疑是一个值得尝试的强大工具。随着它的持续发展和完善,我们可以预期它将在深度学习社区中获得更广泛的采用和认可。









