AGIEval:评估人工智能通用能力的新基准
在人工智能快速发展的今天,如何评估AI模型的通用智能水平一直是学术界和产业界关注的焦点。近期,微软亚洲研究院的研究人员提出了一个名为AGIEval的全新基准测试,旨在以人类为中心的方式,全面评估大型语言模型等基础模型的通用能力。这一基准测试的出现,为我们提供了一个更加贴近真实场景的AI能力评估工具。
AGIEval的独特之处
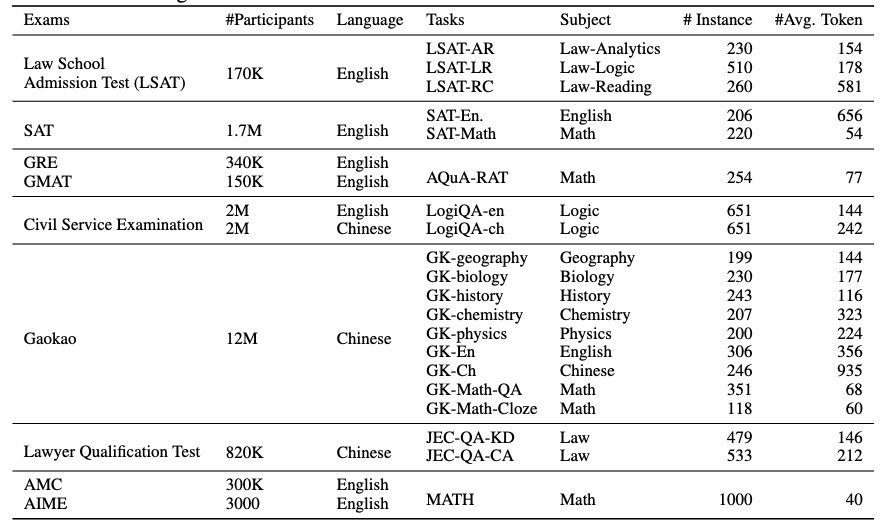
AGIEval与传统的人工智能评估基准有着本质的不同。它不是基于人工构建的数据集,而是直接采用了20项面向普通人的官方考试和资格认证题目,包括:
- 大学入学考试(如中国高考和美国SAT)
- 法学院入学考试(如LSAT)
- 数学竞赛题目
- 律师资格考试
- 国家公务员考试
这些考试都是经过精心设计的,用于评估人类在理解、知识、推理和计算等多个方面的综合能力。通过使用这些真实的人类考试作为评估标准,AGIEval为我们提供了一个更加贴近人类认知和问题解决能力的AI评估视角。
AGIEval的构成与特点
AGIEval包含20个子任务,其中18个是多选题(MCQ)任务,2个是完形填空任务(高考数学填空题和MATH)。这些任务涵盖了广泛的知识领域和能力维度:
- 语言能力:包括中英文的阅读理解和语言表达
- 数学能力:从基础数学到高等数学,涉及计算、推理和问题解决
- 逻辑推理:通过法律推理等任务测试逻辑分析能力
- 专业知识:涵盖物理、化学、生物等学科知识
- 综合分析:如公务员考试中的政策分析题目
AGIEval的一大特点是其双语性质,同时包含中文和英文的任务,这使得它能够更全面地评估AI模型的跨语言能力。
基准测试结果与分析
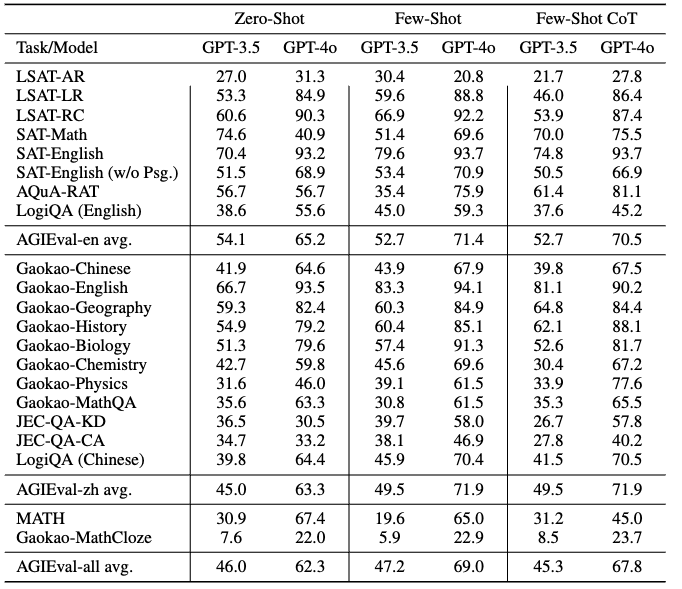
研究团队使用AGIEval对多个最先进的基础模型进行了评估,包括GPT-4、ChatGPT(GPT-3.5-Turbo)等。测试结果令人印象深刻:
- GPT-4在SAT、LSAT和数学竞赛中的表现超过了平均人类水平
- 在SAT数学测试中,GPT-4达到了95%的准确率
- 在中国高考英语测试中,GPT-4的准确率高达92.5%
这些结果展示了当代基础模型的卓越性能,同时也揭示了它们在某些领域的局限性:
- 复杂推理任务:在需要多步骤、深入分析的问题上,AI模型的表现仍有提升空间。
- 专业领域知识:在一些特定的专业知识领域,AI模型的表现不如在通用知识领域出色。
AGIEval的意义与影响
-
更贴近人类标准的评估 AGIEval通过采用真实的人类考试作为评估标准,为AI模型的能力评估提供了一个更加贴近人类认知的视角。这有助于我们更准确地理解AI与人类能力之间的差距。
-
全面的能力评估 AGIEval涵盖了多个知识领域和能力维度,能够全面评估AI模型的综合能力,而不仅仅局限于某一特定领域。
-
为AI发展提供方向 通过详细分析AI模型在不同任务中的表现,AGIEval帮助研究人员识别出当前AI技术的优势和不足,为未来的研究和开发指明方向。
-
推动AI向AGI迈进 AGIEval的设计理念和评估方法,为我们思考和衡量通用人工智能(AGI)的进展提供了新的视角和工具。
AGIEval的未来展望
随着AI技术的不断进步,AGIEval这样的评估基准也将持续演进。未来可能的发展方向包括:
- 扩展任务类型:增加更多样化的任务,如创造性写作、跨学科问题解决等。
- 动态更新:定期更新题库,以适应不断变化的知识体系和社会需求。
- 交互式评估:引入需要多轮对话或复杂推理的交互式任务。
- 伦理和价值观评估:加入评估AI模型对伦理问题理解和处理的任务。
结语
AGIEval的提出和应用,标志着AI评估领域的一个重要进展。它不仅为我们提供了一个更加全面、客观的AI能力评估工具,也为整个AI社区提供了宝贵的研究资源。随着更多研究者和开发者使用AGIEval,我们有望获得更多关于AI模型能力的深入洞察,推动AI技术向着更加通用、智能的方向发展。
AGIEval的开源性质也鼓励了社区的参与和贡献。研究者们可以基于AGIEval进行进一步的研究,如探索AI模型在不同任务间的知识迁移能力,或者分析模型在处理跨语言任务时的表现差异。这种开放合作的模式,将有助于加速AI技术的进步,最终推动我们朝着实现真正的通用人工智能迈进。