
AI已经出现在大众的视野中好久了,你告诉我AI会写文章、会作图甚至会算数我都不会太过于震惊。
但是让我万万没想到的是,AI居然能像人一样刷短视频了!还能理解短视频的内容甚至能捕捉到视频中的笑点。
短视频我们并不陌生,但是AI想要理解短视频可不是一件简单的事情,首先要做到理解图像内容、文本内容和音频内容,还要将这些内容进行串联。
近期在ICML 2024上发表的论文《video- salmon: Speech-Enhanced Audio-Visual Large Language Models》就是首个集齐视频中所有音视频元素(自然图像、文字、语音、音频事件、音乐)的大模型。
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

项目简介
video- salmon的核心是一个多分辨率因果 (MRC) Q-Former结构,该结构将时间同步的视听输入特征与三种不同时间尺度的文本表示空间对齐,满足依赖不同视频元素的任务要求。
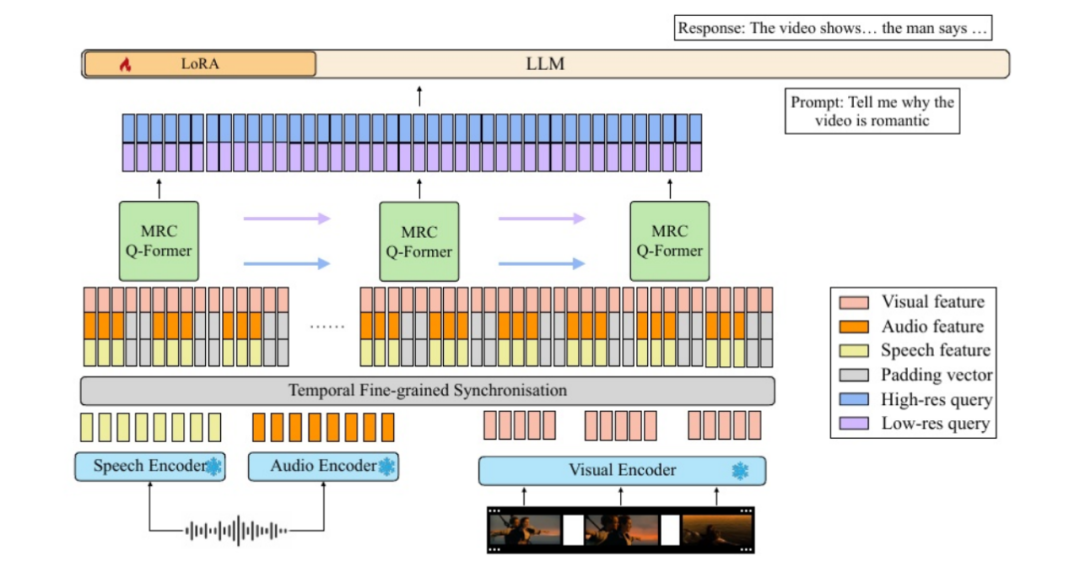
为了加强连续视频帧之间事件的时间因果关系,在MRC Q-Former中包含了一个具有特殊因果掩模的因果自注意结构。
此外,为了避免视频中的特定帧或单一模态占主导地位,video- salmon使用提出的多样性损失和新的不成对视听混合策略进行训练。
那具体效果如何呢,让我们来看看官方给出的实例。

首先将声音的描述与图片内容不符的视频上传给video- salmon,然后对它进行提问,它能够准确地告诉我们这个声音描述与图像内容的是不相符的。
然后就是给出经典的影视视频,看video- salmon能否理解视频的正确含义。
第一个是**《泰坦尼克号》杰克和露丝站在甲板上相拥的片段,问video- salmon**为什么觉得这个片段浪漫。

video- salmon回答说视频中男人把女人拥在怀里,两人一起看着日落。背景音乐是一首歌,增添了浪漫的气氛。
女人说「我在飞」和「杰克」,这表明他们很幸福,享受这一刻。船和日落的背景创造了一个美丽宁静的环境,增强了视频的浪漫感觉。
男女的肢体语言和面部表情也传达了他们对彼此的爱和深情。总的来说,这段视频完美地展现了两人之间浪漫而亲密的时刻。
第二个片段是**《疯狂动物城》中闪电开车的搞笑场景。将这个视频上传给video- salmon,然后问它树懒说了什么话**,为什么这段视频搞笑。

video- salmon回答说树懒在视频结尾时说了**“Nick”**。
而树懒之所以搞笑,是因为它是一种动作缓慢的动物,在视频中表现得非常懒散,做事情花了很长时间。
这与其他动物(如兔子和狐狸)的活跃和充满活力形成了鲜明对比,使树懒显得尤为突出,增加了幽默感。
此外,视频中树懒的慢动作和表情也增加了它的喜剧效果。
总结
通过上述给出的例子我们可以看到,video- salmon还是能比较不错地将视频中的音频、文本和图像进行结合,也能较好的回答有关视频的内容。
但是我们也能很明显地看出video- salmon的回答并不太符合正常人说话的习惯和风格。
而且video- salmon在回答时是无法联网查询视频的上下文内容的,这也造成了video- salmon在回答时的局限。
如**《疯狂动物城》片段的搞笑有很大一部分原因并不是与活泼形成了对比,而是因为树懒的名字叫闪电但是做事说话却很慢**。
期待以后能做到自动查找上下文并结合回答,那将会实现真正意义上的像人一样的刷短视频。
而且如果这种技术实现进一步的升级,能够实现长视频的识别,那我们以后就可以将时间较长的网课上传给AI,让它来告诉我们网课讲了什么,可能会更加节省我们的时间。
论文链接:
https://openreview.net/pdf?id=nYsh5GFIqX
关注「向量光年」公众号,获取更多AI资讯。








