
Alertmanager简介
在当今复杂的IT环境中,及时发现并响应系统异常至关重要。Alertmanager作为Prometheus生态系统中的核心组件,承担着告警管理的重任。它不仅能够高效处理来自Prometheus服务器的告警信息,还能灵活地将这些告警分发给正确的接收者。本文将深入探讨Alertmanager的功能特性、工作原理以及在实际应用中的最佳实践。
Alertmanager的核心功能
告警接收与处理
Alertmanager的主要职责是接收来自Prometheus服务器或其他兼容系统发送的告警。这些告警通常包含了详细的元数据,如告警名称、严重程度、触发时间等信息。Alertmanager接收到这些告警后,会根据预先配置的规则进行处理。
告警分组
在大规模系统中,单个问题可能会触发多个相关的告警。Alertmanager通过分组功能,将这些相关的告警聚合在一起,以减少通知的数量,避免"告警风暴"。例如,当一台服务器宕机时,可能会同时触发CPU、内存、磁盘等多个告警,Alertmanager可以将这些告警归为一组,统一发送通知。
告警去重
为了避免重复通知,Alertmanager实现了智能的去重机制。当同一个告警在短时间内多次触发时,Alertmanager会识别并合并这些重复的告警,只发送一次通知,从而减少接收者的干扰。
告警路由
Alertmanager支持复杂的路由规则,可以根据告警的标签、严重程度等属性,将告警发送给不同的接收者或团队。这种灵活的路由机制确保了正确的人能够及时收到相关的告警信息。
多样化的通知方式
Alertmanager支持多种通知渠道,包括但不限于:
- 电子邮件
- Slack
- PagerDuty
- 自定义WebHooks
这种多样性使得团队可以根据自身需求选择最合适的通知方式,提高告警响应的效率。
静默和抑制机制
Alertmanager提供了静默(Silences)和抑制(Inhibitions)两种机制来控制告警的发送:
- 静默:允许用户在指定的时间段内暂停特定告警的通知,适用于计划内的维护或已知问题的处理。
- 抑制:当某个关键告警触发时,可以自动抑制其他相关的次要告警,以减少不必要的干扰。
Alertmanager的工作原理
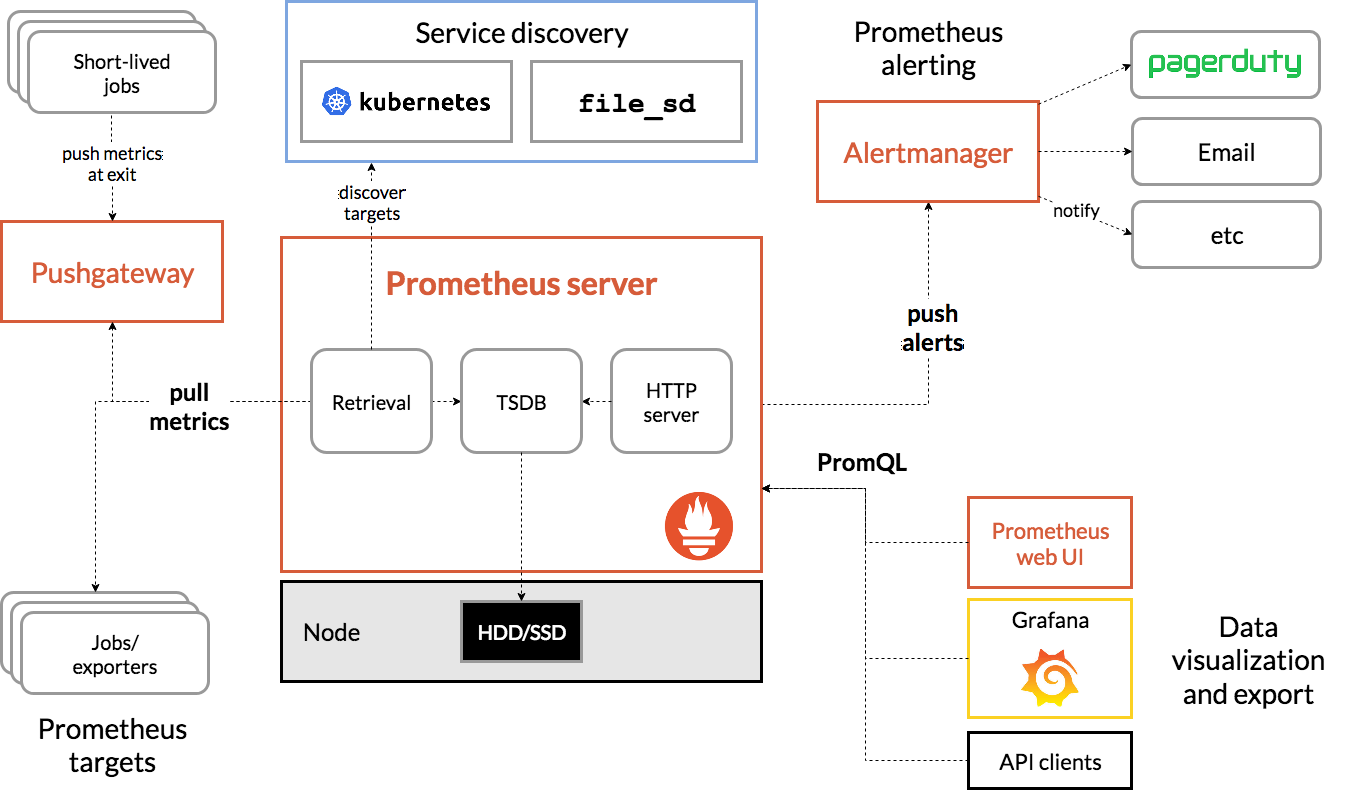
Alertmanager的工作流程可以概括为以下几个步骤:
-
接收告警:Alertmanager通过HTTP API接收来自Prometheus服务器的告警。
-
分组处理:根据配置的分组规则,将相关的告警聚合在一起。
-
去重:识别并合并重复的告警。
-
路由:根据配置的路由规则,确定每个告警的接收者。
-
静默和抑制:应用静默和抑制规则,决定是否发送告警。
-
通知发送:通过配置的通知渠道发送告警信息。
-
重试机制:对于发送失败的通知,Alertmanager会按照预定义的间隔进行重试。
Alertmanager的配置与使用
配置文件
Alertmanager使用YAML格式的配置文件。主要的配置项包括:
- 全局设置(如SMTP服务器配置)
- 路由规则
- 接收者定义
- 抑制规则
- 静默设置
以下是一个简单的配置示例:
global:
smtp_smarthost: 'localhost:25'
smtp_from: 'alertmanager@example.org'
route:
group_by: ['cluster', 'alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
receiver: 'team-emails'
receivers:
- name: 'team-emails'
email_configs:
- to: 'team@example.org'
部署和集成
Alertmanager可以作为独立服务运行,也可以与Prometheus服务器一起部署。在Kubernetes环境中,通常使用Prometheus Operator来管理Alertmanager的部署和配置。
Web界面
Alertmanager提供了一个Web界面,允许用户查看当前的告警状态、管理静默规则,以及测试路由配置。这个界面直观易用,是运维人员管理告警的重要工具。

Alertmanager的最佳实践
-
合理设置分组规则:根据系统架构和业务逻辑,设计合适的分组规则,避免告警信息过于分散或过度聚合。
-
利用标签进行精细路由:充分利用Prometheus的标签系统,为告警添加有意义的标签,以便进行更精确的路由。
-
设置合理的通知间隔:避免过于频繁的通知,同时确保重要告警能够及时送达。
-
实施告警分级:根据告警的严重程度设置不同的通知策略,例如critical级别的告警可以触发电话或短信通知。
-
定期review和优化:定期检查告警配置,移除过时的规则,优化不合理的设置。
-
集成ChatOps工具:将Alertmanager与Slack或Microsoft Teams等协作工具集成,提高团队的响应效率。
-
实现高可用部署:在生产环境中,考虑部署多个Alertmanager实例,以确保告警系统的可靠性。
Alertmanager的未来发展
随着云原生技术的不断发展,Alertmanager也在持续演进。未来的发展方向可能包括:
- 更智能的告警聚合和关联分析
- 与机器学习技术结合,实现预测性告警
- 更丰富的可视化和交互功能
- 更好的跨平台和多云环境支持
结语
Alertmanager作为Prometheus生态系统中的重要组件,为现代化监控系统提供了强大而灵活的告警管理能力。通过合理配置和使用Alertmanager,运维团队可以大大提高故障响应的效率,减少系统宕机时间,最终提升服务的可靠性和用户满意度。
随着更多组织采用云原生架构和微服务,Alertmanager的重要性将进一步凸显。掌握Alertmanager的使用技巧,将成为每个DevOps工程师的必备技能。
🔔 如果您正在构建或优化监控告警系统,不妨深入探索Alertmanager的功能,相信它将为您的系统运维带来显著的改善。
更多信息和详细文档,请访问Alertmanager官方文档。
Happy alerting! 🚀









