
AlignBench简介
AlignBench是清华大学开发的第一个多维度全面评估中文大语言模型(LLM)对齐水平的评测基准。它旨在解决现有评测基准无法准确反映模型在真实场景中表现的问题,为中文LLM的对齐评估提供了一个全面、多维度的解决方案。
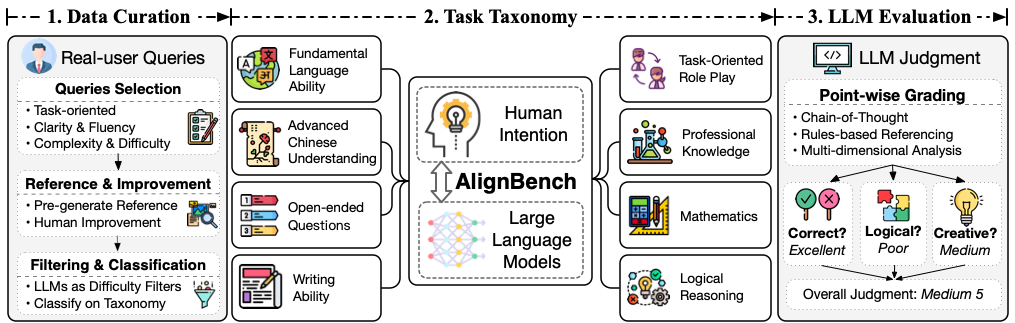
主要特点
- 人机协作的数据构建流程,保证评测数据的动态更新
- 多维度、规则校准的LLM-as-Judge评估方法
- 结合思维链(Chain-of-Thought)生成多维度分析和综合评分
- 涵盖8个主要能力类别,共683个高质量评测数据
数据集信息
AlignBench的评测数据主要来自ChatGLM在线服务中的真实用户问题,涵盖以下8个类别:
- 基本能力
- 中文理解
- 综合问答
- 写作能力
- 逻辑推理
- 数学能力
- 角色扮演
- 专业知识
每个样本包含用户指令、高质量参考答案和对应类别。数据以JSON格式存储在data/data_release.jsonl文件中。
评估方法
AlignBench采用GPT-4作为评测模型,从多个维度分析并打分模型回复,评分范围1-10分。主要评估方法包括:
- 单点打分
- 思维链(Chain-of-Thought)分析
- 规则校准
- 多维度分析

如何使用
使用AlignBench评测模型的主要步骤:
- 获取待评测模型的生成结果
- 调用评价模型获取分析和打分
- 计算最终结果
详细使用说明请参考GitHub仓库中的指南。
相关资源
总结
AlignBench为中文大语言模型的对齐评估提供了一个全面的解决方案。通过多维度的评测数据和方法,它能够更准确地反映模型在实际应用中的表现。研究人员和开发者可以利用AlignBench来改进中文LLM的对齐性能,推动相关技术的发展。










