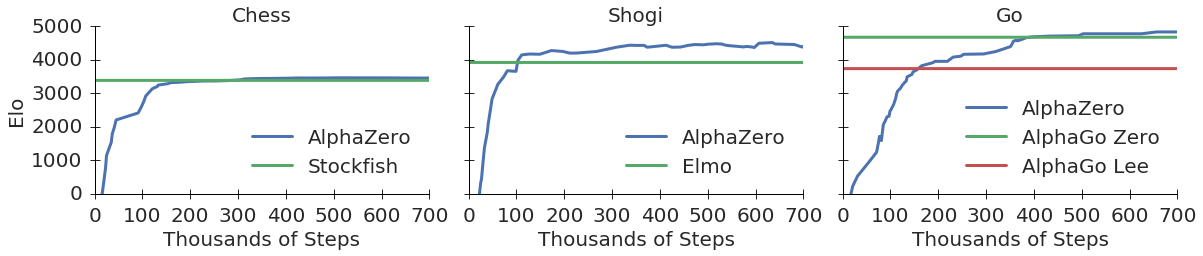
AlphaZero:一种通用的自学习AI框架
AlphaZero是由DeepMind公司开发的一种突破性的人工智能算法,它能够在没有任何人类知识输入的情况下,仅通过自我对弈就掌握复杂的棋类游戏。本文将详细介绍AlphaZero的核心原理、实现方法以及如何将其应用于各种游戏。
AlphaZero的核心原理
AlphaZero的核心思想是将深度学习与蒙特卡洛树搜索(MCTS)相结合,通过不断的自我对弈来提升棋力。其主要组成部分包括:
-
神经网络:用于评估棋局局面并给出行动概率。
-
蒙特卡洛树搜索:用于在对弈过程中选择最佳着法。
-
自我对弈:通过大量的自我对弈来生成训练数据。
-
策略迭代:不断更新神经网络,提升棋力。
AlphaZero的实现步骤
-
初始化神经网络:随机初始化一个神经网络,用于评估局面和给出行动概率。
-
自我对弈:使用当前的神经网络和MCTS进行大量的自我对弈,生成训练数据。
-
训练神经网络:使用自我对弈生成的数据来训练神经网络,提升其评估能力。
-
评估新网络:将新训练的网络与旧网络进行对弈,如果新网络表现更好,则替换旧网络。
-
重复步骤2-4,不断提升棋力。
AlphaZero的应用
AlphaZero最初是为围棋设计的,但其通用性使得它可以应用于多种棋类游戏。目前已经成功应用于:
- 国际象棋
- 将棋
- 黑白棋(反转棋)
- 五子棋
- 井字棋
- 四子棋

开源实现
为了让更多人能够理解和使用AlphaZero算法,GitHub上有一个名为alpha-zero-general的开源项目。该项目提供了一个清晰、通用的AlphaZero实现,可以很容易地应用于不同的游戏。
主要特点包括:
- 支持多种深度学习框架:PyTorch, Keras, TensorFlow
- 游戏无关的核心逻辑
- 包含多个游戏的实现:黑白棋、五子棋、井字棋、四子棋等
- 详细的教程和文档
如何使用alpha-zero-general
- 克隆仓库:
git clone https://github.com/suragnair/alpha-zero-general.git
- 安装依赖:
pip install -r requirements.txt
- 选择一个游戏进行训练,例如黑白棋:
python main.py
- 训练完成后,可以与训练好的模型对弈:
python pit.py
AlphaZero的优势
-
无需人类知识:完全通过自我对弈学习,避免了人类偏见。
-
通用性强:可以应用于多种不同的游戏。
-
学习效率高:通过策略迭代快速提升棋力。
-
创新性强:能够发现人类未知的新策略。
未来展望
AlphaZero的成功为人工智能的发展开辟了新的方向。未来,这种自学习算法可能会应用于更多领域,如:
- 机器人控制
- 自动驾驶
- 蛋白质折叠预测
- 新药研发
总之,AlphaZero代表了一种全新的AI范式,它展示了机器通过自我学习达到超人水平的潜力。随着技术的不断发展,我们有理由相信,这种自学习AI将在更多领域发挥重要作用,推动人工智能的进步。