
AniPortrait:音频驱动下的逼真人像动画合成
在数字内容创作领域,如何生成高质量、逼真的人像动画一直是一个极具挑战性的课题。近日,腾讯游戏智绘团队提出了一种名为AniPortrait的创新框架,为该领域带来了突破性进展。AniPortrait能够根据音频和参考肖像图像生成高质量的逼真人像动画,为内容创作者提供了强大的新工具。
AniPortrait的核心创新
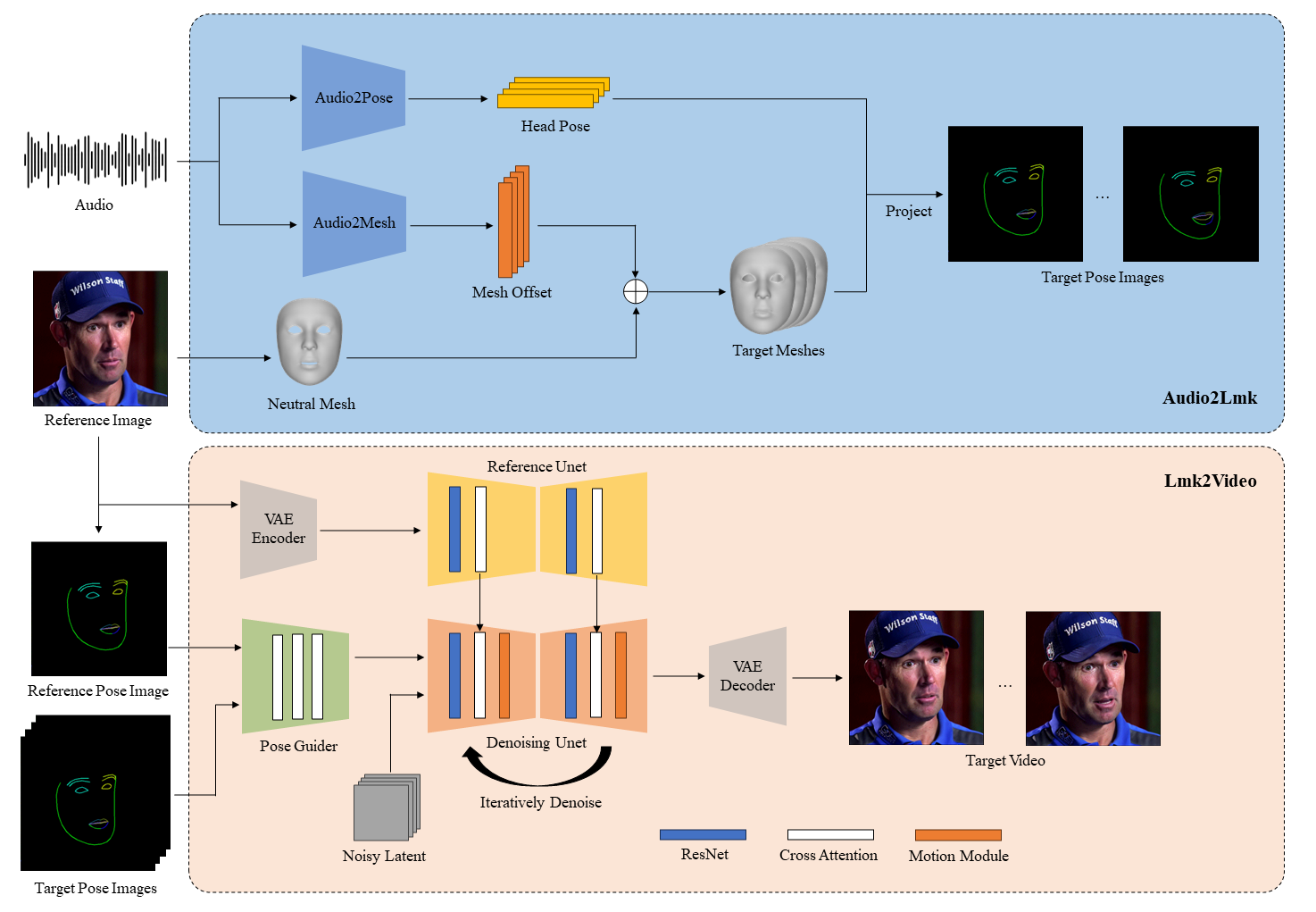
AniPortrait最大的创新在于其独特的两阶段处理流程:
-
音频特征提取与映射:首先从音频中提取3D中间表示,并将其投影为2D面部关键点序列。
-
高质量动画生成:然后利用强大的扩散模型和运动模块,将关键点序列转化为照片级真实、时序连贯的人像动画。
这种设计使AniPortrait能够捕捉音频中的丰富信息,并将其自然地映射到人像的表情和动作中,从而生成高度逼真的动画效果。
AniPortrait的主要特点
通过对AniPortrait的深入分析,我们可以总结出其几个突出的特点:
-
高度逼真性:AniPortrait生成的人像动画在面部细节、表情变化等方面都达到了极高的真实感,堪比真人视频效果。
-
灵活的驱动方式:除了音频驱动外,AniPortrait还支持视频驱动的人脸重演(face reenactment)功能,为创作者提供了更多可能性。
-
优秀的姿态多样性:生成的动画在头部姿态等方面展现出丰富的变化,避免了僵硬单调的效果。
-
出色的视觉质量:无论是静态画面还是动态效果,AniPortrait都能保持稳定的高品质输出。
-
强大的控制能力:创作者可以通过调整各种参数来精确控制生成效果,如头部姿态、表情强度等。
这些特点使AniPortrait在实际应用中具有很强的实用性和灵活性。
AniPortrait的应用前景
AniPortrait为多个领域带来了激动人心的应用前景:
-
数字人物创作:可用于快速生成高质量的数字人物动画,大大提高创作效率。
-
视频制作:为视频制作者提供了便捷的人物动画生成工具,特别适用于配音、旁白等场景。
-
虚拟主播:可用于构建更自然、富有表现力的AI虚拟主播系统。
-
游戏开发:为游戏中的NPC角色赋予更丰富的面部表情和动作。
-
教育培训:可用于制作富有吸引力的教育视频,提升学习体验。
-
虚拟现实(VR):为VR应用中的虚拟人物带来更逼真的面部动画效果。
随着技术的进一步完善,AniPortrait在更多领域的应用也将逐步展开。
AniPortrait的实现细节
要充分发挥AniPortrait的潜力,了解其实现细节和使用方法非常重要。以下是一些关键信息:
-
环境配置:
- 推荐Python版本 ≥ 3.10
- CUDA版本 = 11.7
- 通过
pip install -r requirements.txt安装依赖
-
预训练模型: AniPortrait依赖多个预训练模型,需要下载并放置在
./pretrained_weights目录下,包括:- AniPortrait自身的模型权重
- StableDiffusion V1.5
- sd-vae-ft-mse
- image_encoder
- wav2vec2-base-960h
-
推理命令: AniPortrait支持多种推理模式,如:
- 自驱动模式:
python -m scripts.pose2vid --config ./configs/prompts/animation.yaml -W 512 -H 512 -acc - 人脸重演模式:
python -m scripts.vid2vid --config ./configs/prompts/animation_facereenac.yaml -W 512 -H 512 -acc - 音频驱动模式:
python -m scripts.audio2vid --config ./configs/prompts/animation_audio.yaml -W 512 -H 512 -acc
- 自驱动模式:
-
训练过程: AniPortrait的训练分为两个阶段:
- Stage1:
accelerate launch train_stage_1.py --config ./configs/train/stage1.yaml - Stage2:
accelerate launch train_stage_2.py --config ./configs/train/stage2.yaml
- Stage1:
通过熟悉这些细节,开发者可以更好地利用AniPortrait,甚至对其进行进一步的优化和定制。
AniPortrait的技术亮点
深入分析AniPortrait的技术实现,我们可以发现几个值得关注的亮点:
-
音频特征提取:采用先进的音频处理技术,能够有效捕捉语音中的情感和语调信息。
-
3D到2D的映射:创新性地将3D音频特征映射到2D面部关键点,为后续动画生成奠定基础。
-
扩散模型的应用:利用强大的扩散模型来生成高质量图像,确保了输出的逼真度。
-
运动模块的设计:专门设计的运动模块保证了生成动画的时序连贯性和自然流畅性。
-
多模态融合:成功实现了音频、图像和视频等多种模态的有效融合。
这些技术亮点共同构成了AniPortrait的核心竞争力,使其在音频驱动的人像动画合成领域脱颖而出。
AniPortrait的未来发展
作为一项前沿技术,AniPortrait仍有巨大的发展空间:
-
性能优化:进一步提高生成速度,支持实时或近实时的动画生成。
-
多人物支持:扩展到支持多个人物同时出现在画面中的场景。
-
更细致的控制:提供更多精细化的控制参数,如单独控制眼睛、嘴巴等部位的动作。
-
风格迁移:集成风格迁移功能,允许用户自定义动画的艺术风格。
-
3D支持:从2D扩展到3D人像动画的生成,为VR/AR应用提供支持。
-
情感智能:增强对音频中情感的理解和表达,生成更富有感染力的动画。
随着这些方向的探索和突破,AniPortrait将为数字内容创作带来更多可能性。
结语
AniPortrait作为一种革命性的音频驱动人像动画合成技术,展现了AI在创意领域的巨大潜力。它不仅为内容创作者提供了强大的新工具,也为数字娱乐、教育等多个行业带来了新的机遇。随着技术的不断完善和应用场景的拓展,AniPortrait必将在推动数字内容创作的发展中发挥越来越重要的作用。
我们期待看到更多基于AniPortrait的创新应用,以及它在推动人机交互、虚拟现实等领域进步中的贡献。对于开发者和研究者来说,深入研究AniPortrait的技术原理,参与其开源社区的建设,将是一个既有挑战性又充满机遇的方向。
最后,我们要感谢腾讯游戏智绘团队以及所有为AniPortrait做出贡献的研究者和开发者。正是因为有了他们的开创性工作和开放分享精神,我们才能看到如此激动人心的技术进步。让我们共同期待AniPortrait在未来带来更多令人惊叹的创新和应用!









