
AOT-GAN:高分辨率图像修复的新突破
在计算机视觉领域,图像修复(Image Inpainting)一直是一个充满挑战性的任务。它的目标是根据图像中未被遮挡的区域内容,以语义一致的方式恢复被损坏或缺失的部分。虽然已有的方法取得了一些令人鼓舞的结果,但对于高分辨率图像(如512x512)中大面积缺失区域的修复仍然面临很大困难。近日,来自微软亚洲研究院和中山大学的研究团队提出了一种名为AOT-GAN的新方法,在高分辨率图像修复任务上取得了重大突破。
AOT-GAN的核心创新
AOT-GAN(Aggregated cOntextual-Transformation GAN)的主要创新点在于:
-
增强上下文推理能力:在生成器中引入了AOT Block(聚合上下文变换模块)。这些AOT Block能够聚合不同感受野的上下文变换,从而捕获到远距离的信息上下文和丰富的局部模式,大大增强了对缺失内容的推理能力。
-
改进纹理合成:在判别器中采用了SoftGAN技术。通过一个定制的掩码预测任务来训练判别器,使其能够更好地区分真实和合成图像块的细节外观。这反过来又促使生成器生成更加真实的纹理。
这两项创新使得AOT-GAN能够同时解决高分辨率图像修复中的两大难题:推断大面积缺失内容和合成精细纹理。
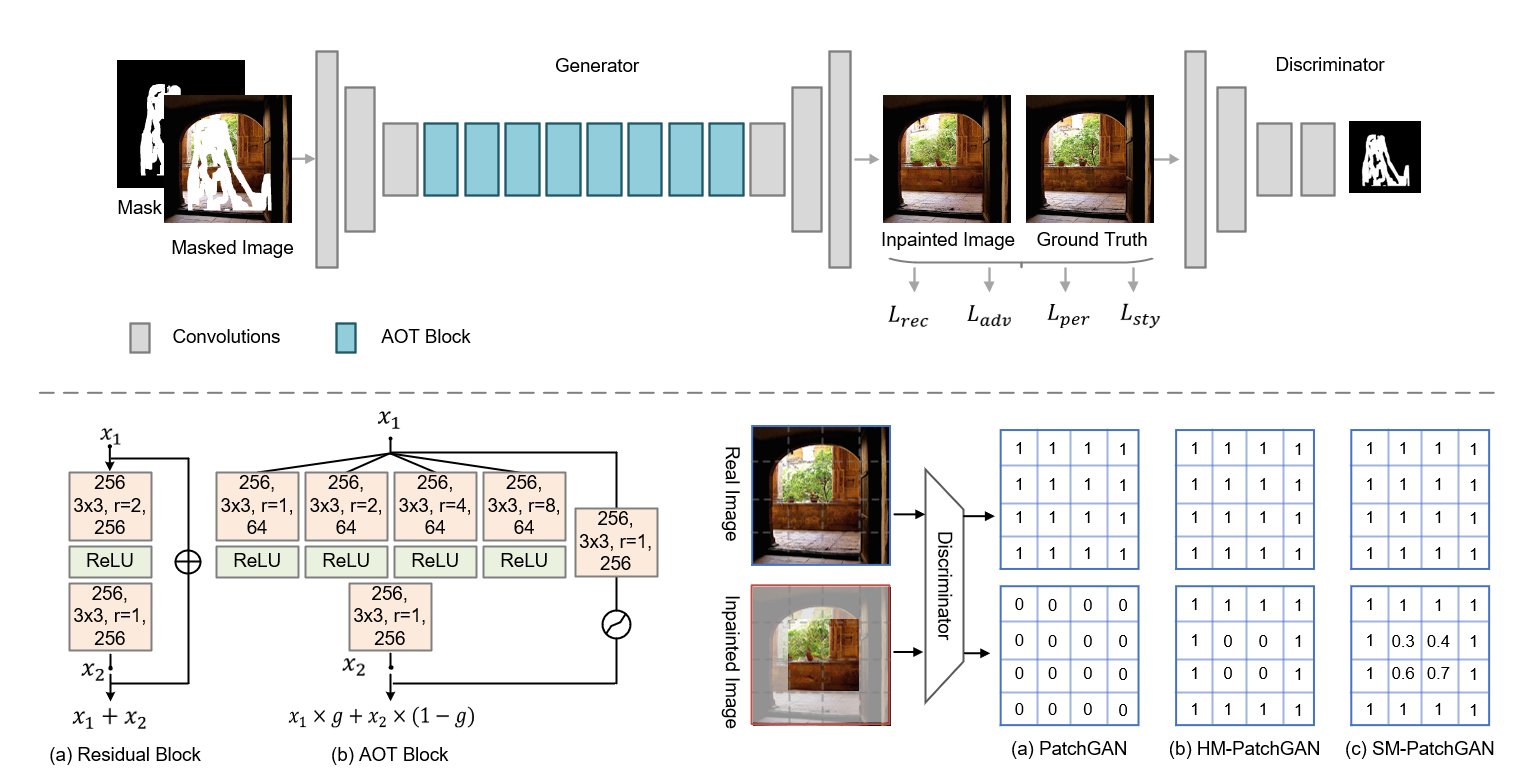
卓越的修复效果
AOT-GAN在多个基准数据集上展现出了优异的性能。尤其是在最具挑战性的Places2数据集(包含180万张高分辨率图像,涵盖365个复杂场景)上,AOT-GAN在FID指标上相对于现有最佳方法实现了38.60%的相对提升,这是一个非常显著的进步。
以下是AOT-GAN在人脸和物体修复上的一些示例结果:

可以看到,AOT-GAN能够很好地修复人脸和物体的缺失部分,生成的内容既符合语义一致性,又保持了精细的纹理细节。
实际应用
除了在基准数据集上的出色表现,AOT-GAN在实际应用中也展现出了巨大的潜力。研究人员对AOT-GAN进行了多项实际应用测试,包括:
- logo移除: 能够自然地移除图像中的logo,并用周围的背景内容无缝填充。
- 人脸编辑: 可以修改人脸的某些部分,如改变发型、移除眼镜等。
- 物体移除: 能够从复杂场景中移除指定物体,并合理填充背景。
这些应用展示了AOT-GAN在现实世界中的实用价值。以下是一个logo移除的动态演示:
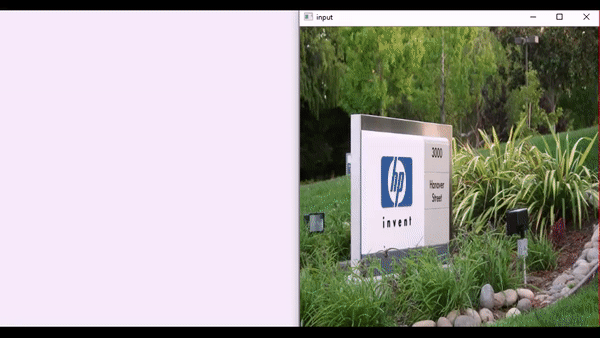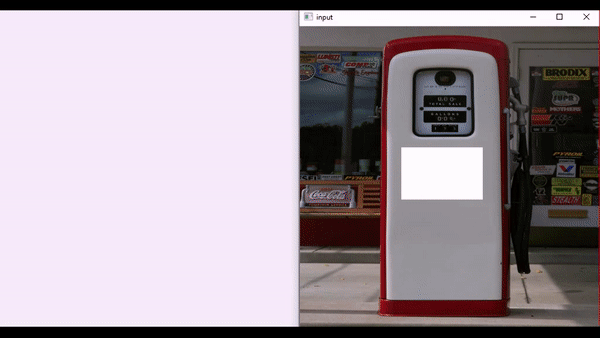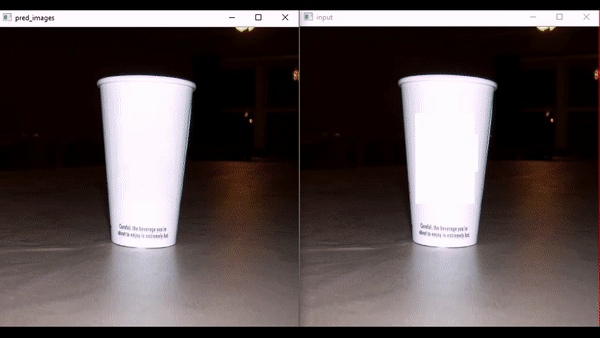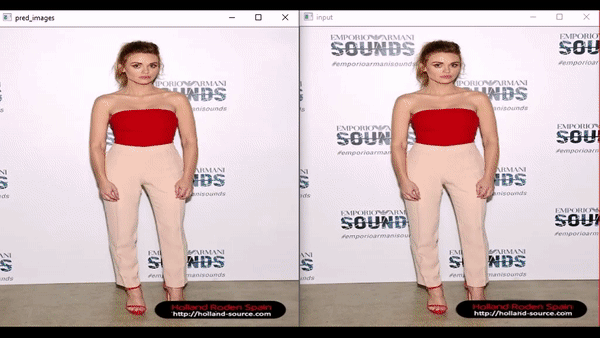
开源与复现
为了促进该领域的研究进展,研究团队已经将AOT-GAN的代码和预训练模型完全开源。感兴趣的读者可以通过以下步骤尝试复现AOT-GAN的结果:
- 克隆GitHub仓库:
git clone git@github.com:researchmm/AOT-GAN-for-Inpainting.git
cd AOT-GAN-for-Inpainting/
- 创建并激活conda环境:
conda env create -f environment.yml
conda activate inpainting
-
下载预训练模型:
将下载的模型文件夹放在
experiments/目录下。 -
运行演示程序:
cd src
python demo.py --dir_image [图像文件夹路径] --pre_train [预训练模型路径] --painter [bbox|freeform]
通过这些步骤,研究者和开发者可以快速上手AOT-GAN,并将其应用到自己的项目中。
未来展望
虽然AOT-GAN在高分辨率图像修复任务上取得了显著进展,但图像修复领域仍有很多值得探索的方向:
- 更高分辨率的支持: 目前AOT-GAN在4K分辨率图像上的表现还有待验证,如何进一步提升模型在超高分辨率图像上的性能是一个重要研究方向。
- 实时处理: 优化模型结构和推理过程,实现视频流的实时修复。
- 多模态融合: 结合文本、音频等其他模态信息,实现更智能的图像修复。
- 个性化定制: 开发能够根据用户偏好或特定场景需求进行定制化修复的模型。
- 可解释性研究: 深入分析模型的决策过程,提高修复结果的可解释性和可控性。
随着深度学习和计算机视觉技术的不断发展,我们有理由相信,未来的图像修复技术将在准确性、效率和适用性等方面取得更大的突破,为更广泛的应用场景提供强大支持。
结语
AOT-GAN为高分辨率图像修复任务提供了一种新的解决方案,其创新的聚合上下文变换和软判别器技术显著提升了修复效果。这项研究不仅推动了学术界的进展,也为实际应用提供了有力工具。随着开源代码和预训练模型的发布,我们期待看到更多基于AOT-GAN的创新应用和改进方案涌现。
对于有志于深入研究图像修复技术的读者,AOT-GAN无疑是一个很好的起点。通过深入理解其原理、复现其结果,并在此基础上进行创新,相信会有更多令人兴奋的突破出现。让我们共同期待图像修复技术的美好未来!










