Apache Beam简介
Apache Beam是一个开源的统一编程模型,用于定义批处理和流处理数据并行处理管道。它由Google内部的数据处理项目演变而来,最初被称为"Dataflow模型"。Beam提供了一套统一的概念和API,使开发人员能够用相同的代码处理批量数据和实时流数据,而无需关心底层执行环境的差异。
Beam的核心理念是将数据处理抽象为一系列转换(Transforms)操作,这些操作作用于分布式数据集合(PCollections)上。通过这种方式,Beam实现了数据处理逻辑与执行环境的解耦,使同一套代码可以运行在不同的分布式处理系统上。

Beam的主要概念
Beam编程模型中的几个关键概念包括:
-
PCollection: 表示数据集合,可以是有界的(批处理)或无界的(流处理)。
-
PTransform: 表示数据转换操作,将输入PCollection转换为输出PCollection。
-
Pipeline: 管理PTransform和PCollection组成的有向无环图,代表整个数据处理流程。
-
PipelineRunner: 指定Pipeline在哪里以及如何执行。
通过这些抽象概念,Beam实现了批处理和流处理的统一编程模型。
Beam的SDK支持
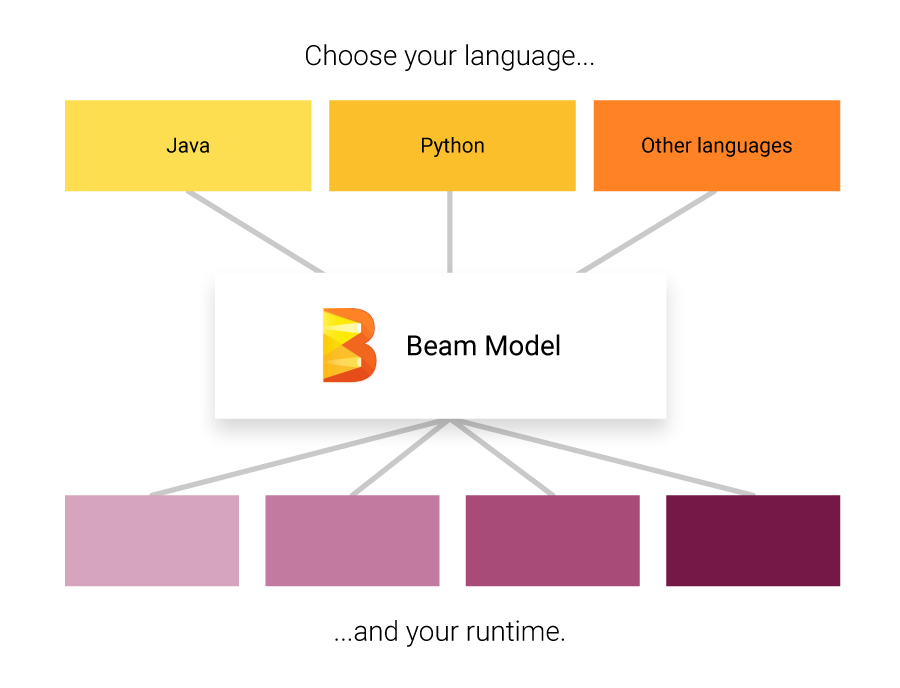
Beam支持多种编程语言的SDK,目前主要包括:
- Java SDK
- Python SDK
- Go SDK
这些SDK允许开发人员使用熟悉的编程语言来构建Beam管道。每个SDK都提供了相应语言的API,但都遵循相同的Beam模型概念。
Beam的Runner支持
Beam管道可以在多个分布式处理后端上执行,这些执行环境被称为Runner。目前支持的主要Runner包括:
- Direct Runner: 在本地机器上执行,主要用于开发和测试。
- Apache Flink Runner: 在Apache Flink集群上执行。
- Apache Spark Runner: 在Apache Spark集群上执行。
- Google Cloud Dataflow Runner: 在Google Cloud Dataflow服务上执行。
- Hazelcast Jet Runner: 在Hazelcast Jet集群上执行。
这种设计使得同一个Beam管道可以灵活地部署到不同的执行环境中,而无需修改代码。
Beam的主要特性
-
统一的批处理和流处理模型 Beam提供了一套统一的API来处理批量数据和流数据,大大简化了开发工作。
-
多语言支持
支持Java、Python和Go等多种编程语言的SDK。 -
多Runner支持 同一套代码可以运行在Apache Flink、Apache Spark、Google Cloud Dataflow等多个分布式处理系统上。
-
强大的窗口(Windowing)机制 提供了灵活的数据窗口划分策略,适用于各种复杂的时间相关计算场景。
-
触发器(Trigger)机制 允许用户精细控制何时输出计算结果,平衡了延迟和完整性。
-
丰富的转换操作 内置了大量常用的数据转换操作,如Map、GroupByKey、Combine等。
-
灵活的I/O连接器 支持从多种数据源读取数据并写入多种目标存储。
Beam的应用场景
Apache Beam适用于多种大数据处理场景,包括但不限于:
-
ETL和数据处理
用于构建复杂的数据提取、转换和加载(ETL)管道。 -
流式数据分析 实时处理和分析持续产生的数据流,如日志分析、传感器数据处理等。
-
批量数据分析 处理大规模历史数据集,进行复杂的数据分析和挖掘。
-
机器学习管道 构建端到端的机器学习工作流,包括数据预处理、模型训练和预测。
-
事件驱动应用 构建响应实时事件的应用系统,如实时推荐、欺诈检测等。
使用Beam的步骤
要开始使用Apache Beam,通常需要遵循以下步骤:
-
选择SDK: 根据你熟悉的编程语言,选择相应的Beam SDK。
-
安装SDK: 使用包管理器安装Beam SDK,如Java的Maven、Python的pip等。
-
创建Pipeline: 使用SDK API创建一个Pipeline对象,这是所有数据处理逻辑的容器。
-
应用转换: 使用各种PTransform操作来定义数据处理逻辑。
-
指定I/O: 使用Beam的I/O连接器来读取输入数据和写出结果。
-
运行Pipeline: 选择一个Runner并执行Pipeline。
以下是一个简单的Python示例,展示了如何使用Beam处理文本数据:
import apache_beam as beam
with beam.Pipeline() as pipeline:
lines = pipeline | beam.io.ReadFromText('input.txt')
counts = (
lines
| 'Split' >> beam.FlatMap(lambda x: x.split())
| 'PairWithOne' >> beam.Map(lambda x: (x, 1))
| 'GroupAndSum' >> beam.CombinePerKey(sum)
)
counts | beam.io.WriteToText('output.txt')
这个例子读取文本文件,计算单词出现次数,并将结果写入输出文件。
Beam的社区和生态系统
Apache Beam拥有一个活跃的开源社区,不断推动项目的发展和改进。社区提供了丰富的资源来帮助用户学习和使用Beam:
-
官方文档: 提供了全面的使用指南、API参考和最佳实践。
-
示例代码: GitHub仓库中包含了大量示例,涵盖各种常见用例。
-
邮件列表: 用户可以订阅开发者和用户邮件列表,参与讨论。
-
JIRA: 用于跟踪问题和新功能请求。
-
贡献指南: 鼓励社区成员参与项目开发和改进。
此外,Beam还与其他Apache项目和大数据生态系统紧密集成,如Apache Flink、Apache Spark、Apache Kafka等,进一步扩展了其应用范围。
Beam的未来发展
作为一个快速发展的开源项目,Apache Beam正在朝着以下方向发展:
-
增强流处理能力: 不断改进对复杂流处理场景的支持。
-
扩展SDK支持: 计划增加对更多编程语言的支持。
-
改进性能: 持续优化各Runner的执行效率。
-
增强机器学习支持: 提供更多与机器学习和AI集成的功能。
-
简化用户体验: 开发更多工具和可视化界面,降低使用门槛。
结论
Apache Beam作为一个强大而灵活的统一数据处理框架,正在成为大数据和流处理领域的重要工具。它的统一编程模型、多语言支持和跨平台执行能力,使其能够满足各种复杂的数据处理需求。无论是处理批量数据还是实时流数据,Beam都提供了一致的开发体验和丰富的功能。
随着大数据和实时处理需求的不断增长,Apache Beam的重要性也在不断提升。对于希望构建可扩展、可移植的数据处理应用的开发者和组织来说,Beam无疑是一个值得深入学习和使用的强大工具。











