
autolabel简介
autolabel是由Refuel AI开发的开源Python库,旨在利用大语言模型(LLM)对文本数据集进行快速、高质量的标注。它支持多种NLP任务,如分类、命名实体识别、问答等,可以使用OpenAI、Anthropic等商业LLM或开源LLM进行标注。

通过autolabel,数据科学家和机器学习工程师可以将数据标注速度提高25-100倍,同时保持人工标注级别的质量。这大大缩短了机器学习项目的周期,让团队可以更快地迭代和改进模型。
主要功能
autolabel提供了以下核心功能:
- 支持多种NLP任务的数据标注,包括分类、命名实体识别、实体匹配、问答等。
- 可使用OpenAI、Anthropic、Google等商业LLM,也支持通过HuggingFace使用开源模型。
- 提供few-shot学习、思维链等提示技术,提高标注质量。
- 内置标签置信度估计和解释功能。
- 缓存和状态管理,降低成本并加快实验速度。
快速开始
要开始使用autolabel,只需几个简单步骤:
- 安装库:
pip install refuel-autolabel
-
创建配置文件,指定标注任务、使用的LLM等信息。
-
初始化标注agent并传入配置:
from autolabel import LabelingAgent, AutolabelDataset
agent = LabelingAgent(config='config.json')
- 预览prompt并运行标注:
ds = AutolabelDataset('dataset.csv', config=config)
agent.plan(ds)
更详细的使用教程可以参考官方文档。
学习资源
- GitHub仓库 - 项目源码和详细说明
- 官方文档 - 完整的API文档和使用指南
- 技术报告 - autolabel的性能基准测试
- Discord社区 - 与开发者和其他用户交流
- Colab notebook - 交互式体验autolabel
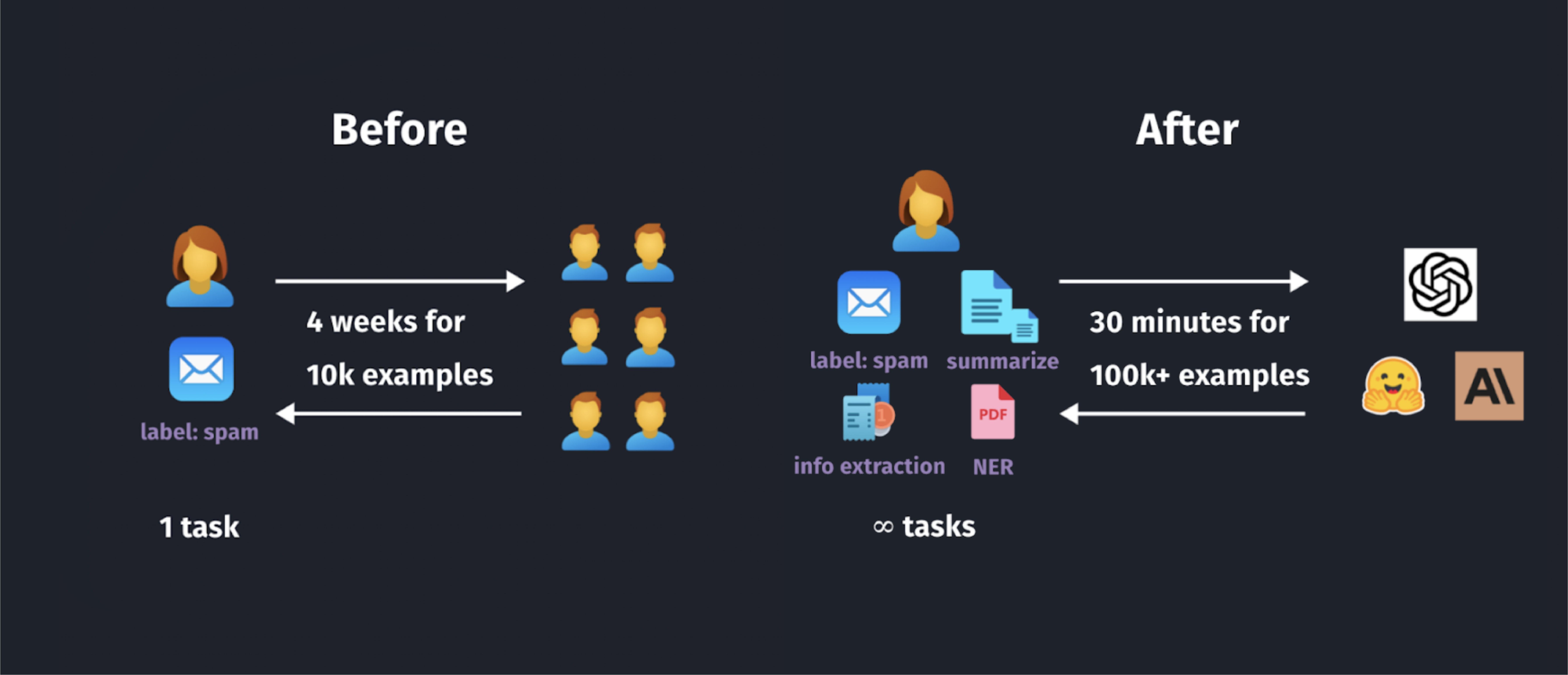
未来规划
autolabel团队正在积极开发新功能,包括:
- 支持更多LLM提供商和模型
- 增加更多标注任务类型,如蕴含关系、摘要等
- 改进LLM输出的鲁棒性
- 实现新的提示技术,如思维树等
- 提供多模型和多提示的实验工作流
欢迎查看公开路线图了解更多计划,也欢迎通过GitHub issues提出建议或反馈问题。
autolabel为NLP数据处理带来了革命性的提升,值得所有从事机器学习和数据科学工作的开发者尝试。无论是学术研究还是工业应用,它都能显著提高数据准备的效率,让我们能更快地构建出高质量的机器学习模型。









