
Awesome-Code-LLM: 代码大语言模型研究的前沿进展
在人工智能和自然语言处理领域,代码大语言模型(Code LLM)正成为一个备受关注的研究热点。随着技术的快速发展,这些模型在代码生成、理解和分析方面展现出惊人的能力,为软件开发和程序设计带来革命性的变革。本文将深入探讨Awesome-Code-LLM项目,这是一个精心策划的代码大语言模型研究资源列表,旨在为研究人员和开发者提供最新、最全面的相关信息。
项目概述
Awesome-Code-LLM项目由huybery在GitHub上发起和维护,是一个开源的资源汇总平台。该项目的主要目标是收集和整理代码大语言模型研究领域的最新进展、重要论文、开源模型和相关数据集等资源。通过这个项目,研究人员可以快速了解该领域的发展动态,开发者则能够找到适合自己需求的模型和工具。
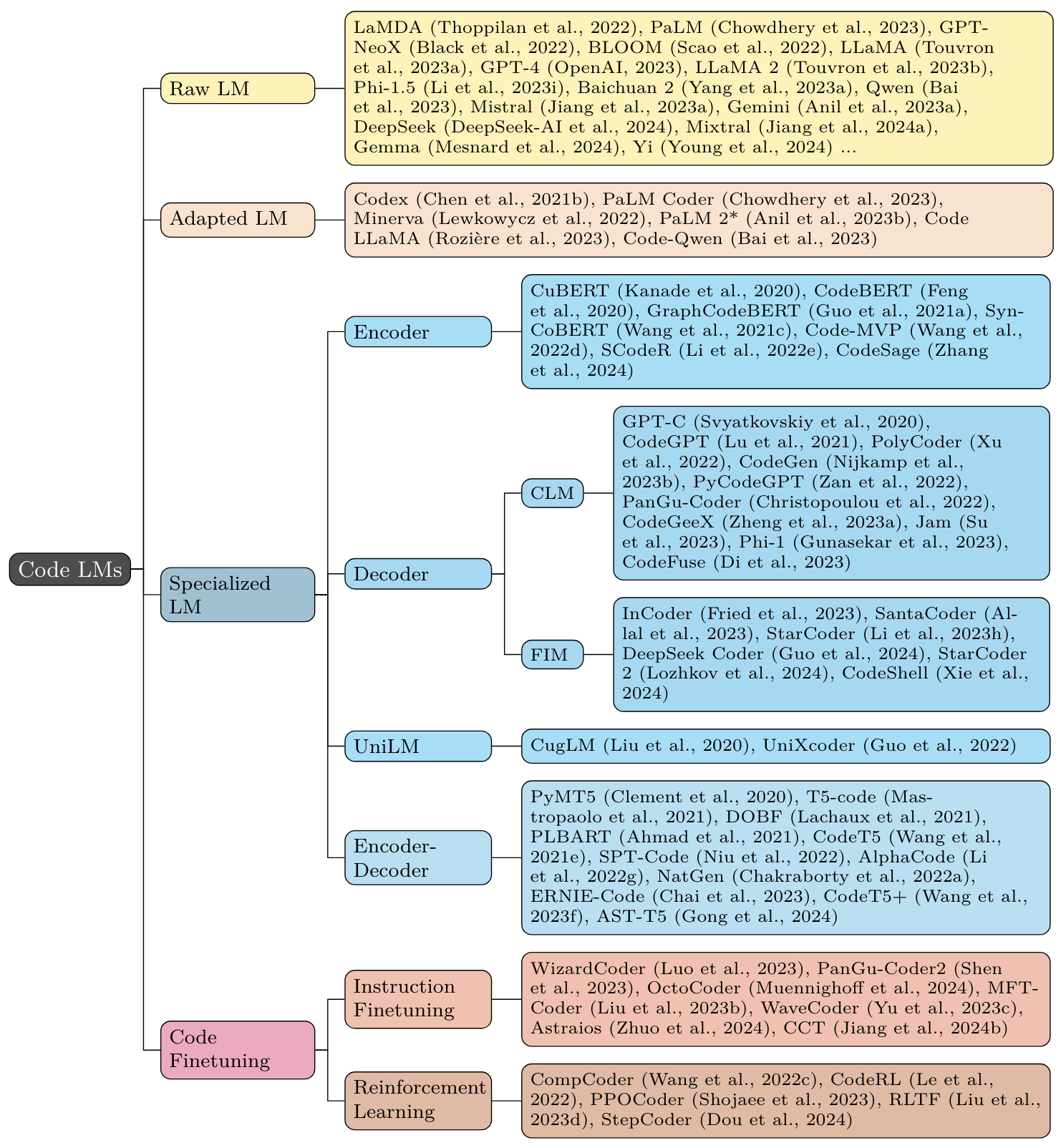
主要内容
Awesome-Code-LLM项目涵盖了代码大语言模型研究的多个方面,主要包括以下几个部分:
1. 综述论文
项目收录了多篇高质量的综述论文,这些论文从不同角度对代码大语言模型的研究现状进行了全面的总结和分析。例如:
- "Large Language Models Meet NL2Code: A Survey" (ACL 2023)
- "A Survey on Pretrained Language Models for Neural Code Intelligence"
- "Large Language Models for Software Engineering: A Systematic Literature Review"
这些综述为研究人员提供了宝贵的参考资料,有助于快速把握该领域的研究脉络和发展趋势。
2. 模型分类
项目将代码大语言模型分为几个主要类别:
-
通用大语言模型(Off-the-Shelf LLM): 如GPT-4、LLaMA 2等,虽非专门为代码设计,但在编程任务中也表现出色。
-
适应代码的现有LLM(Existing LLM Adapted to Code): 如Codex(基于GPT-3)、Code LLaMA(基于LLaMA 2)等,这些模型在通用LLM的基础上进行了代码相关的进一步预训练。
-
专门针对代码的预训练模型(General Pretraining on Code): 这类模型从头开始训练,专门针对代码理解和生成进行优化。根据模型结构又可分为:
- Encoder模型: 如CodeBERT、GraphCodeBERT等
- Decoder模型: 如CodeGPT、StarCoder等
- Encoder-Decoder模型: 如PLBART、CodeT5等
3. 下游任务
项目还收集了大量针对特定下游任务的方法和模型,涵盖了软件开发生命周期的各个阶段:
- 编程: 代码生成、代码翻译、代码摘要、程序修复等
- 测试与部署: 测试生成、漏洞检测、编译器优化等
- DevOps: 提交信息生成、代码审查、日志分析等
- 需求工程: 软件建模、需求分析等
4. AI生成代码分析
随着AI生成代码的普及,对其质量和特性的分析也成为一个重要研究方向。项目收集了多篇相关论文,涉及:
- 安全性和漏洞
- 正确性
- 幻觉现象
- 效率
- 鲁棒性
- 可解释性
- AI生成代码检测
5. 数据集
高质量的数据集是训练和评估代码大语言模型的关键。项目收录了多个重要的代码相关数据集,包括:
- 预训练数据集: 如The Stack、CodeParrot等
- 基准测试数据集: 如HumanEval、MBPP等
最新进展
Awesome-Code-LLM项目保持着高频率的更新,不断收录该领域的最新研究成果。例如,最近添加的一些重要工作包括:
- DOMAINEVAL: 一个自动构建的多领域代码生成基准测试
- CRUXEval-X: 一个多语言代码推理、理解和执行的基准测试
- SQL-GEN: 通过合成数据和模型合并来解决文本到SQL转换中的方言差异问题
- 基于搜索的LLM代码优化方法
- 结合静态分析和LLM的可解释崩溃故障定位方法
这些最新研究反映了代码大语言模型在应用广度和技术深度上的持续拓展。
项目价值与影响
Awesome-Code-LLM项目为代码大语言模型研究领域提供了一个全面、及时和高质量的资源汇总平台,其价值主要体现在以下几个方面:
-
研究导航: 为新入门的研究人员提供了清晰的研究脉络和方向指引。
-
资源共享: 汇集了大量开源模型、数据集和工具,促进了研究社区的资源共享。
-
趋势把握: 通过定期更新,帮助研究者及时了解该领域的最新进展和热点方向。
-
跨学科融合: 将自然语言处理和软件工程的研究视角有机结合,促进了学科间的交叉融合。
-
产业应用推动: 为企业和开发者提供了丰富的模型选择和应用参考,加速了相关技术的产业化落地。
未来展望
随着代码大语言模型技术的不断发展,我们可以预见该领域在未来将呈现以下几个发展趋势:
-
模型规模和性能的持续提升: 更大规模、更高效的模型将不断涌现,进一步提高代码生成和理解的质量。
-
多模态融合: 代码LLM将与其他模态(如图像、音频)进行更深入的融合,实现更全面的程序理解和生成。
-
特定领域优化: 针对特定编程语言、框架或应用领域的专用模型将得到更多关注。
-
安全性和可靠性研究: 随着AI生成代码的普及,如何保证其安全性和可靠性将成为重要研究方向。
-
人机协作模式创新: 探索代码LLM与人类程序员的最佳协作模式,将成为提高软件开发效率的关键。
-
伦理和监管: 随着技术的发展,相关的伦理问题和监管政策也将得到更多关注。
结语
Awesome-Code-LLM项目为我们呈现了代码大语言模型研究领域的全景图,不仅反映了该领域的蓬勃发展,也预示着人工智能在软件开发中将发挥越来越重要的作用。无论是研究人员、开发者还是企业决策者,都可以从这个项目中获得宝贵的洞见和资源。随着技术的不断进步,我们有理由相信,代码大语言模型将为软件开发带来更多革命性的变革,推动整个行业向更高效、更智能的方向发展。
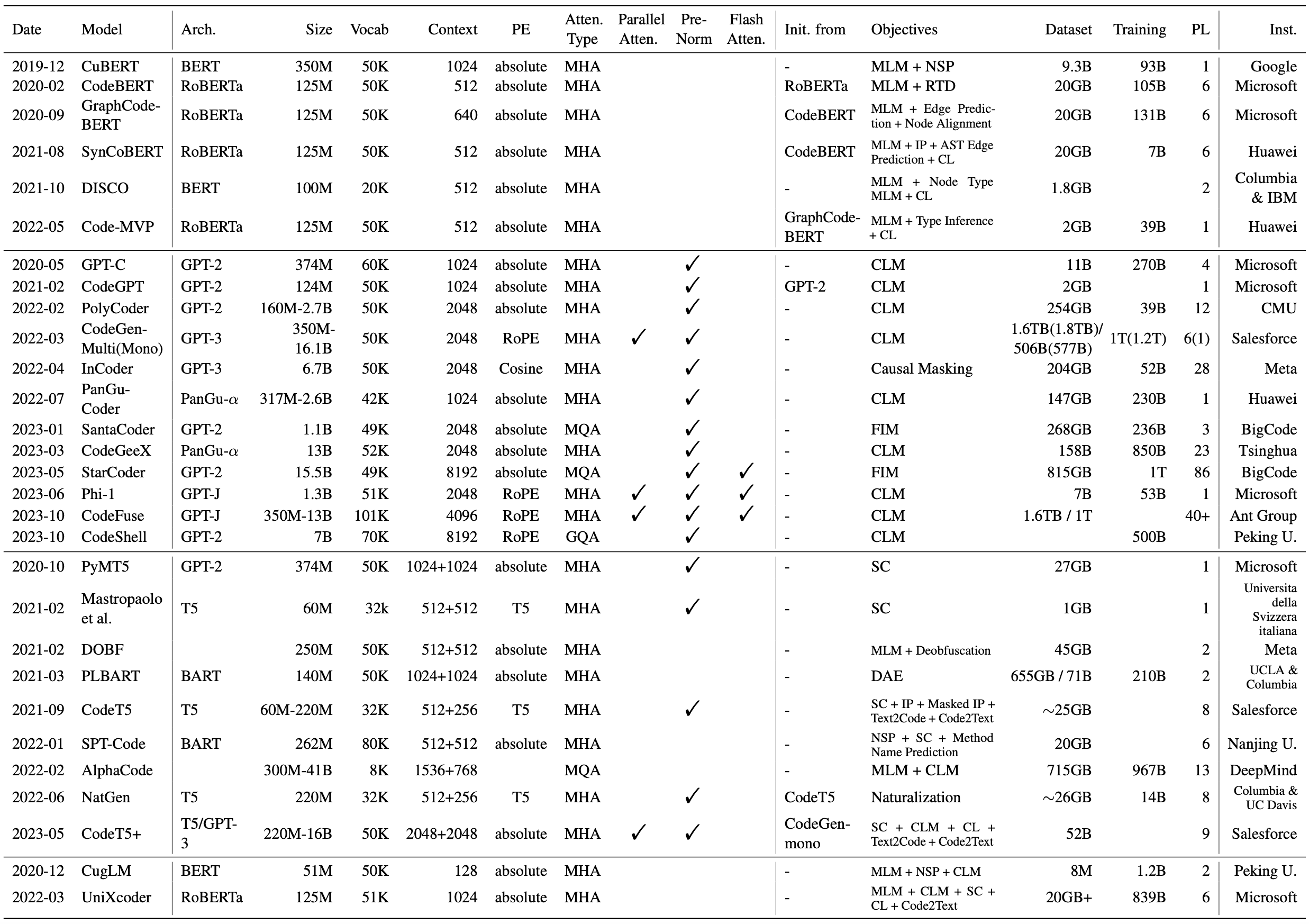
参与贡献
Awesome-Code-LLM作为一个开源项目,欢迎所有对代码大语言模型感兴趣的研究者和开发者参与贡献。您可以通过以下方式参与:
- 提交新的研究论文、模型或数据集信息
- 改进现有内容的组织和分类
- 修正错误或更新过时的信息
- 提供使用经验和最佳实践建议
通过共同维护和完善这个资源列表,我们可以为代码大语言模型的研究和应用构建一个更加强大和活跃的社区。
如果您对Awesome-Code-LLM项目感兴趣,欢迎访问其GitHub仓库了解更多信息,并考虑为项目贡献您的力量。让我们共同推动代码大语言模型技术的发展,为软件开发的未来描绘更加美好的蓝图。










