
Awesome-Efficient-LLM学习资料汇总 - 高效大语言模型压缩与加速技术
随着大语言模型(LLM)的快速发展,如何提高LLM的效率成为了一个重要的研究方向。Awesome-Efficient-LLM项目汇总了这一领域的最新进展,为研究者和开发者提供了宝贵的学习资源。本文将对该项目的主要内容进行介绍,帮助读者快速了解高效LLM技术的前沿动态。
项目概览
Awesome-Efficient-LLM项目由GitHub用户horseee维护,项目地址为:https://github.com/horseee/Awesome-Efficient-LLM
该项目主要收集了以下几个方面的高效LLM技术:
- 网络剪枝/稀疏化
- 知识蒸馏
- 量化
- 推理加速
- 高效MOE
- 高效LLM架构
- KV缓存压缩
- 文本压缩
- 低秩分解
- 硬件/系统优化
- 微调技术
- 相关综述
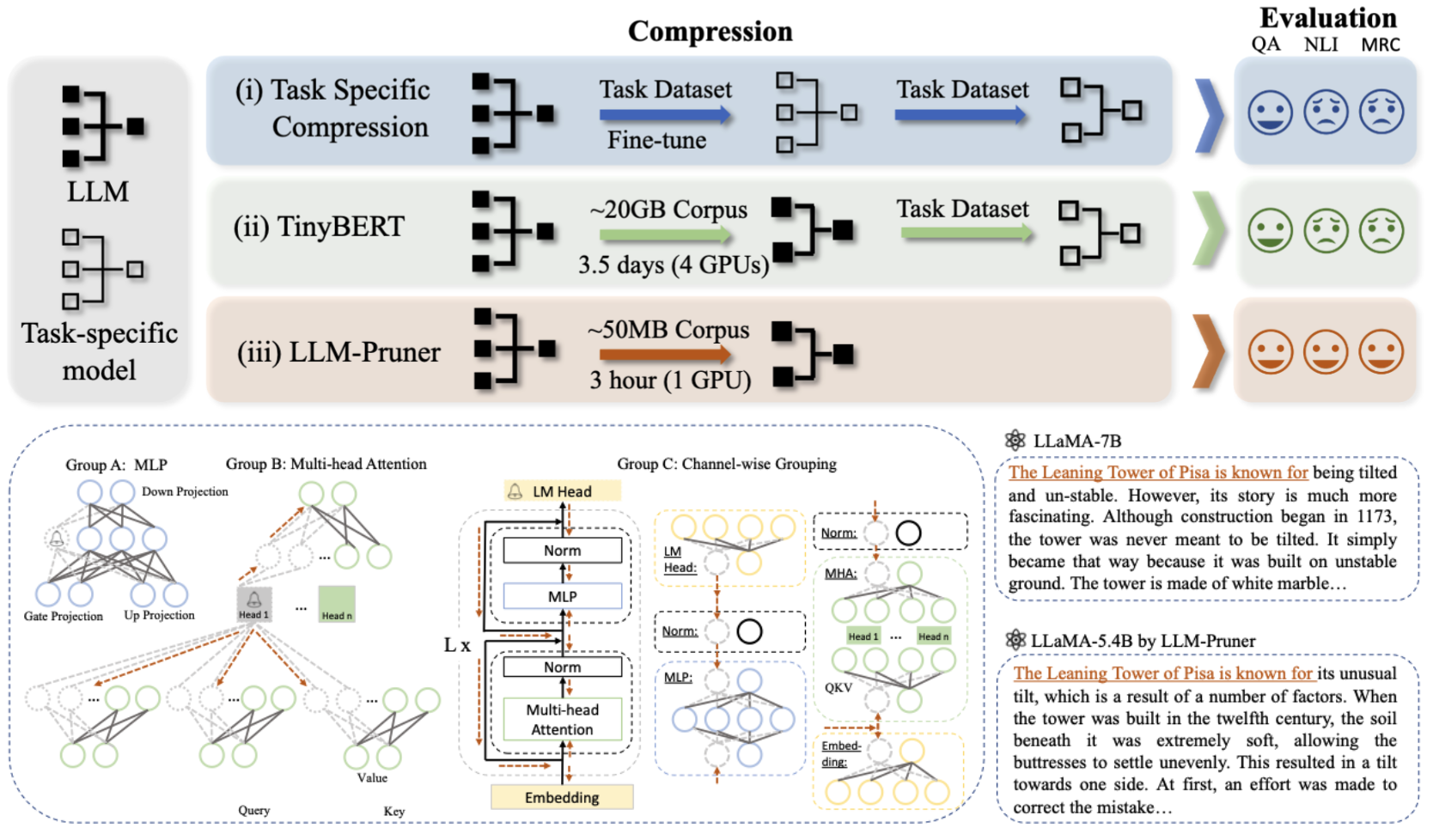
网络剪枝/稀疏化
网络剪枝是一种有效的模型压缩方法,通过去除冗余或不重要的连接来减小模型规模。该项目收集了多篇关于LLM剪枝的重要论文,例如:
- SparseGPT: 一种一次性剪枝大语言模型的方法
- LLM-Pruner: 对LLM进行结构化剪枝的方法
- Sheared LLaMA: 通过结构化剪枝加速LLM预训练
知识蒸馏
知识蒸馏是将大模型的知识转移到小模型中的技术。项目收集了多篇LLM知识蒸馏相关论文,如:
- Compact Language Models via Pruning and Knowledge Distillation
- MINI-LLM: Memory-Efficient Structured Pruning for Large Language Models
量化
量化是一种通过降低数值精度来压缩模型的方法。项目收集了多篇LLM量化相关论文,如:
- AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
- SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
推理加速
推理加速主要关注如何提高LLM的推理速度。项目收集了多篇相关论文,如:
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- LLM-Speedup: Fast Inference of Large Language Models with Dynamic Sampling
总结
Awesome-Efficient-LLM项目为我们提供了一个全面了解高效LLM技术的窗口。随着LLM规模的不断增大,如何提高其效率将成为一个越来越重要的研究方向。该项目的持续更新将为研究者和开发者提供宝贵的参考资源。
欢迎访问项目主页了解更多详情,也欢迎大家为项目贡献新的相关资源。让我们一起推动LLM技术向更高效、更实用的方向发展!


















