
Baichuan2: 开源大语言模型的新突破
百川智能最近推出了新一代开源大语言模型Baichuan2,这是一个在多个权威基准测试中取得同尺寸最佳效果的模型。本文将详细介绍Baichuan2的特点、性能表现以及应用方法。
模型介绍
Baichuan2是百川智能推出的新一代开源大语言模型,采用2.6万亿Tokens的高质量语料进行训练。该模型在多个权威的中文、英文和多语言的通用、领域benchmark上取得了同尺寸最佳的效果。本次发布包含7B和13B两种规模,每种规模又分为Base和Chat两个版本,并提供了Chat版本的4bits量化。
所有版本对学术研究完全开放,同时开发者通过邮件申请并获得官方商用许可后,即可免费商用。这体现了百川智能推动AI开源开放的决心。
性能表现
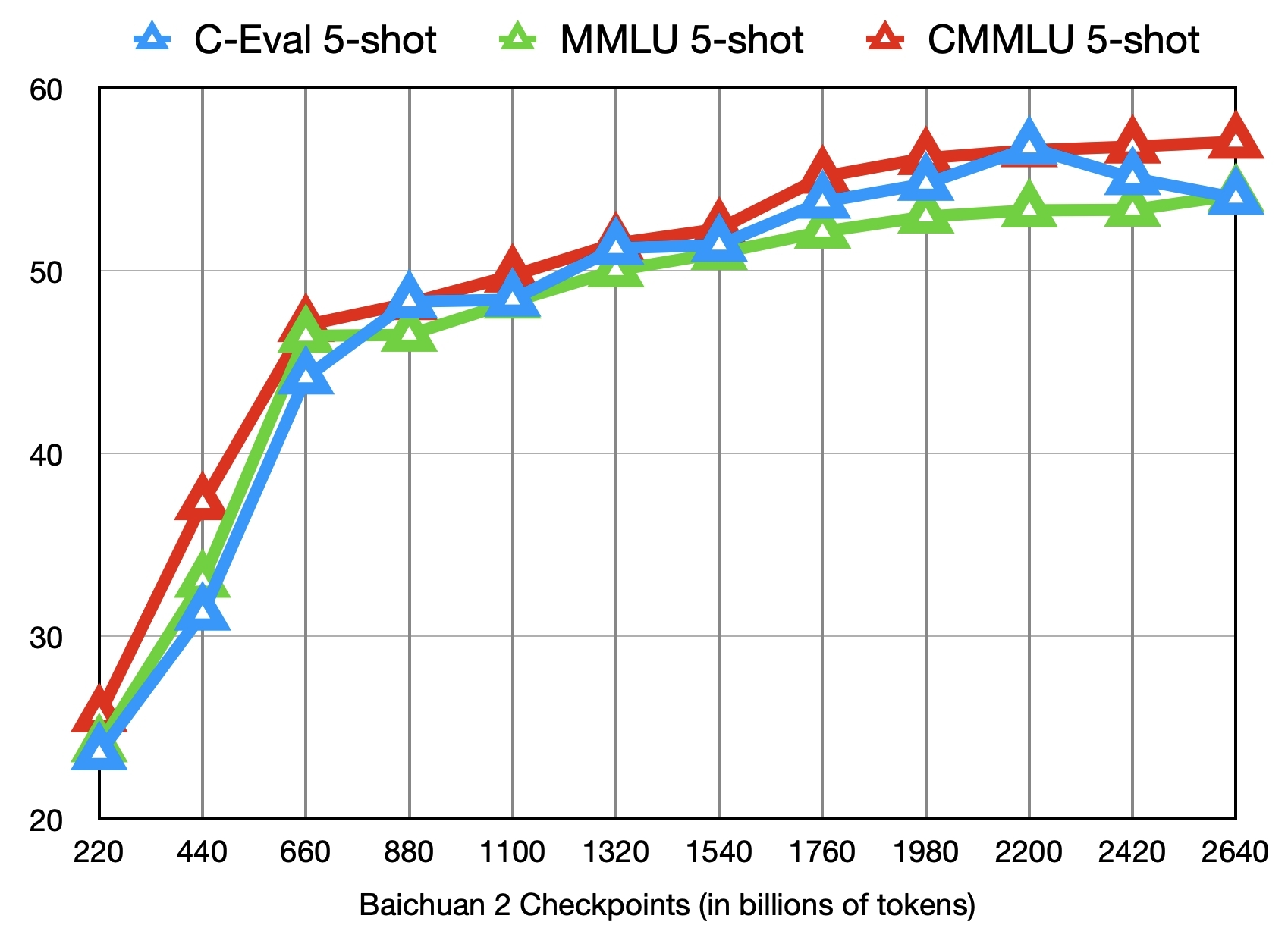
Baichuan2在多个权威基准测试中展现出了卓越的性能:
-
通用领域:在C-Eval、MMLU、CMMLU等测试中,Baichuan2-13B-Base模型的得分分别达到58.10、59.17和61.97,显著优于同尺寸的其他开源模型。
-
法律医疗:在JEC-QA法律数据集上,Baichuan2-13B-Base得分47.40,在医疗相关数据集上的综合得分也达到59.33,均为同尺寸最佳。
-
数学编程:在GSM8K数学推理数据集上,Baichuan2-13B-Base得分52.77,在HumanEval编程数据集上得分17.07,也都优于同尺寸其他开源模型。
-
多语言翻译:在Flores-101多语言翻译任务中,Baichuan2-13B-Base的平均得分达到16.09,展现了优秀的多语言能力。
这些测试结果表明,Baichuan2在通用能力和专业领域都具有出色的表现,是一个全面且强大的大语言模型。
应用方法
Baichuan2提供了多种便捷的使用方式:
- Python代码调用:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Chat",
use_fast=False,
trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Chat",
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan2-13B-Chat")
messages = []
messages.append({"role": "user", "content": "解释一下"温故而知新"})
response = model.chat(tokenizer, messages)
print(response)
-
命令行工具:提供了专门的命令行工具,方便快速体验模型效果。
-
网页demo:通过streamlit可以快速搭建一个本地网页demo,直观地与模型进行对话交互。
这些多样化的使用方式使得研究者和开发者可以根据自己的需求灵活地应用Baichuan2模型。
结语
Baichuan2的发布标志着开源大语言模型领域的一个新的里程碑。它不仅在性能上达到了同尺寸的最优水平,还提供了全面的开源开放政策,为AI技术的普及和应用提供了强大支持。我们期待看到更多基于Baichuan2的创新应用,推动AI技术在各个领域的深入发展。











