
BakLLaVA:视觉语言模型的新篇章
在人工智能快速发展的今天,多模态模型正成为学术界和工业界关注的焦点。其中,BakLLaVA作为一个集视觉和语言于一体的强大模型,正在掀起一场多模态AI的革命。本文将深入探讨BakLLaVA的创新之处,以及它在视觉语言模型领域带来的突破性进展。
BakLLaVA的诞生与发展
BakLLaVA项目诞生于一个充满创新精神的合作中。该项目由SkunkworksAI、LAION和Ontocord三方共同推进,旨在将最先进的多模态技术融入语言模型中。BakLLaVA v1的训练得益于Together Compute的算力支持,展现了AI领域跨机构合作的巨大潜力。
BakLLaVA的核心理念是"将最先进的多模态能力烘焙到语言模型中"。为实现这一目标,研发团队采取了多项创新措施:
- 改进基础模型
- 优化训练流程
- 构建定制数据集
- 对原LLaVA架构进行重大改进
这些措施的综合运用,使BakLLaVA在多模态理解和生成方面取得了显著进步。
技术创新与架构优化
BakLLaVA的成功离不开其在技术层面的多项创新。以下是一些关键的技术亮点:
-
基于Mistral 7B的增强: BakLLaVA采用Mistral 7B作为基础语言模型,并在此基础上融合了LLaVA架构,实现了强大的视觉语言理解能力。
-
多阶段训练策略:
- 特征对齐阶段: 利用约60万经过筛选的CC3M数据集,将预训练的视觉编码器与冻结的LLM连接起来。
- 视觉指令微调阶段: 使用15万GPT生成的多模态指令数据,教会模型遵循多模态指令。
-
高效训练技术:
- 使用DeepSpeed进行训练,大幅节省GPU内存。
- 引入LLaVA-Lightning技术,将训练时间缩短至仅3小时(包括预训练和微调),同时保持模型性能。
-
灵活的部署选项:
- 支持4位和8位量化推理,降低GPU内存占用。
- 提供LoRA权重加载方式,节省磁盘空间。
-
多GPU支持: 自动检测并利用多个GPU,提高训练和推理效率。
BakLLaVA的卓越性能
BakLLaVA在多个方面展现出了优秀的性能:
-
视觉理解能力: 能够准确识别和描述图像中的物体、场景和活动。
-
跨模态交互: 可以理解并回答关于图像的复杂问题,实现自然的视觉对话。
-
指令遵循: 通过视觉指令微调,模型能够准确执行各种与图像相关的任务。
-
推理效率: 支持量化推理,在保持性能的同时大幅降低资源需求。
-
快速训练: LLaVA-Lightning技术使得模型可以在极短时间内完成训练,加速研究和应用迭代。
应用场景与未来展望
BakLLaVA的强大能力为多个领域带来了新的可能性:
-
智能助手: 可以理解和讨论用户提供的图像,提供更自然的人机交互体验。
-
内容创作: 辅助设计师和创作者,根据文字描述生成相关的视觉内容构思。
-
医疗诊断: 协助医生分析医学影像,提供初步诊断建议。
-
教育领域: 为学生提供图像化的学习辅助,增强理解复杂概念的能力。
-
自动驾驶: 提升车载系统对道路环境的理解和决策能力。
随着技术的不断进步,我们可以期待BakLLaVA在以下方面有更多突破:
- 更大规模的模型训练,进一步提升性能
- 多语言支持,扩大全球应用范围
- 与其他模态(如音频、视频)的融合,实现更全面的多模态理解
- 在特定领域(如医疗、教育)的深度优化和应用
结语
BakLLaVA作为一个创新的多模态AI模型,正在重新定义视觉语言交互的可能性。它不仅展示了AI技术的最新进展,也为未来的研究和应用指明了方向。随着BakLLaVA及类似模型的不断发展,我们正在迈向一个视觉和语言深度融合的AI新时代。
研究者和开发者可以通过BakLLaVA的GitHub仓库深入了解这个项目,参与其中,共同推动多模态AI的发展。让我们期待BakLLaVA在未来带来更多令人兴奋的突破和应用!
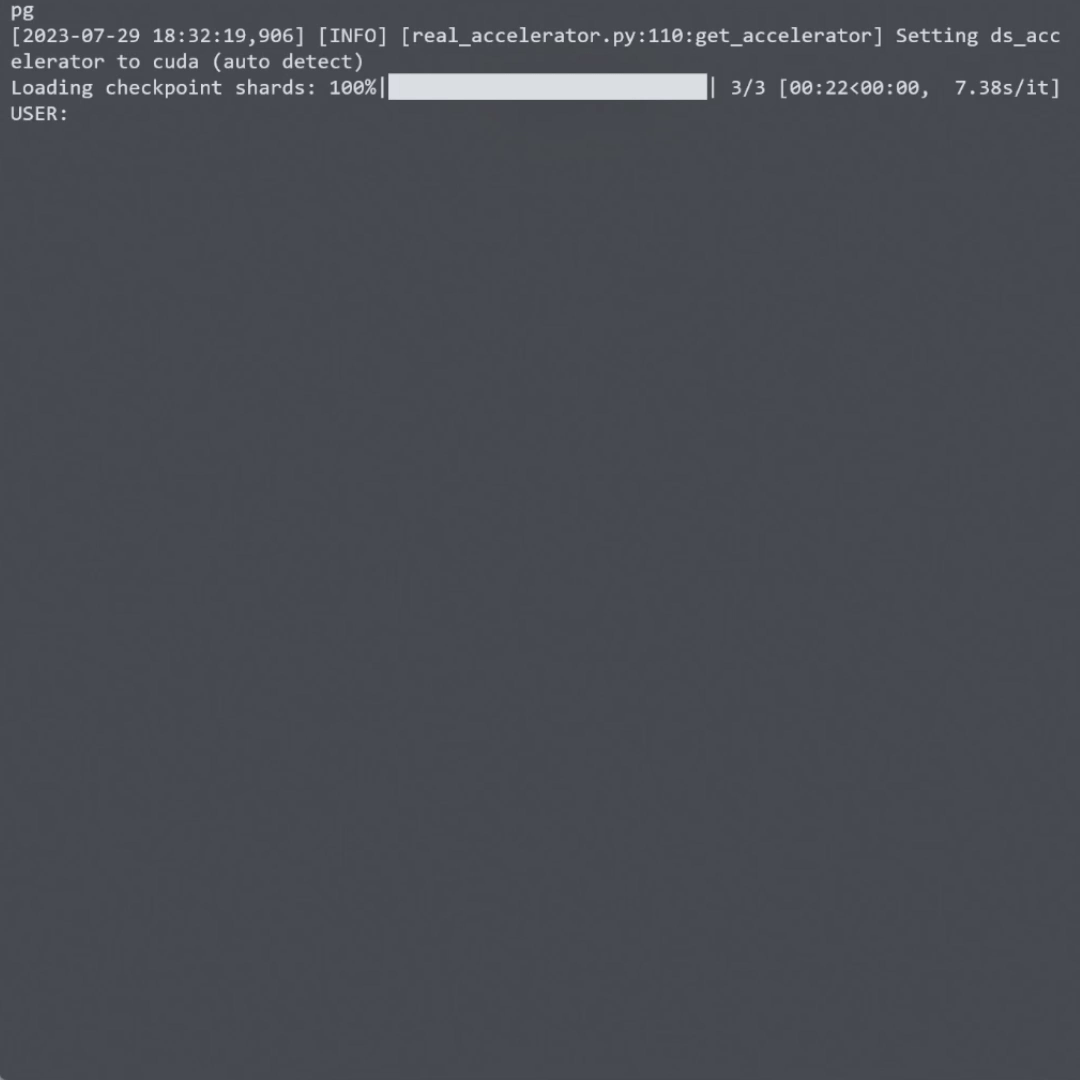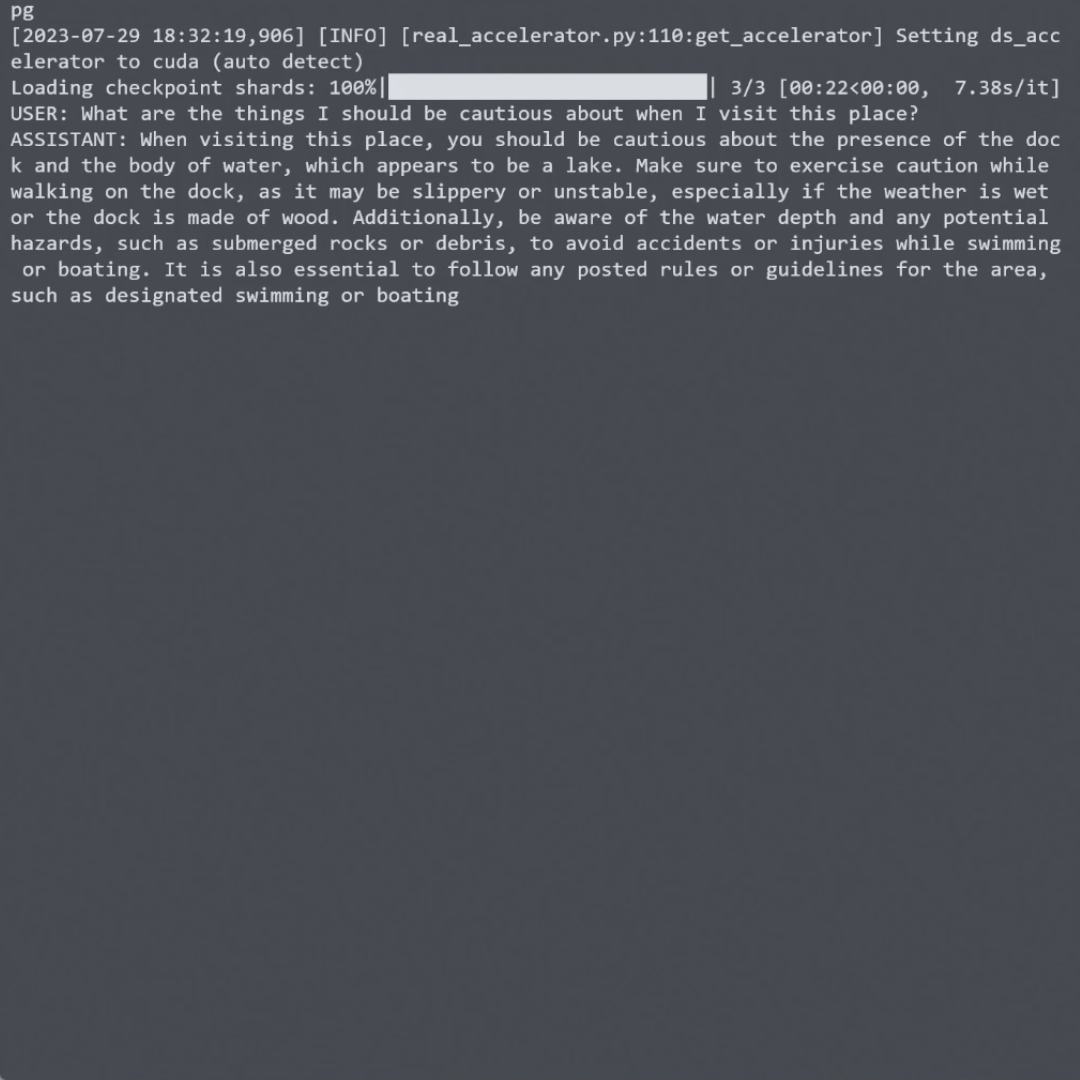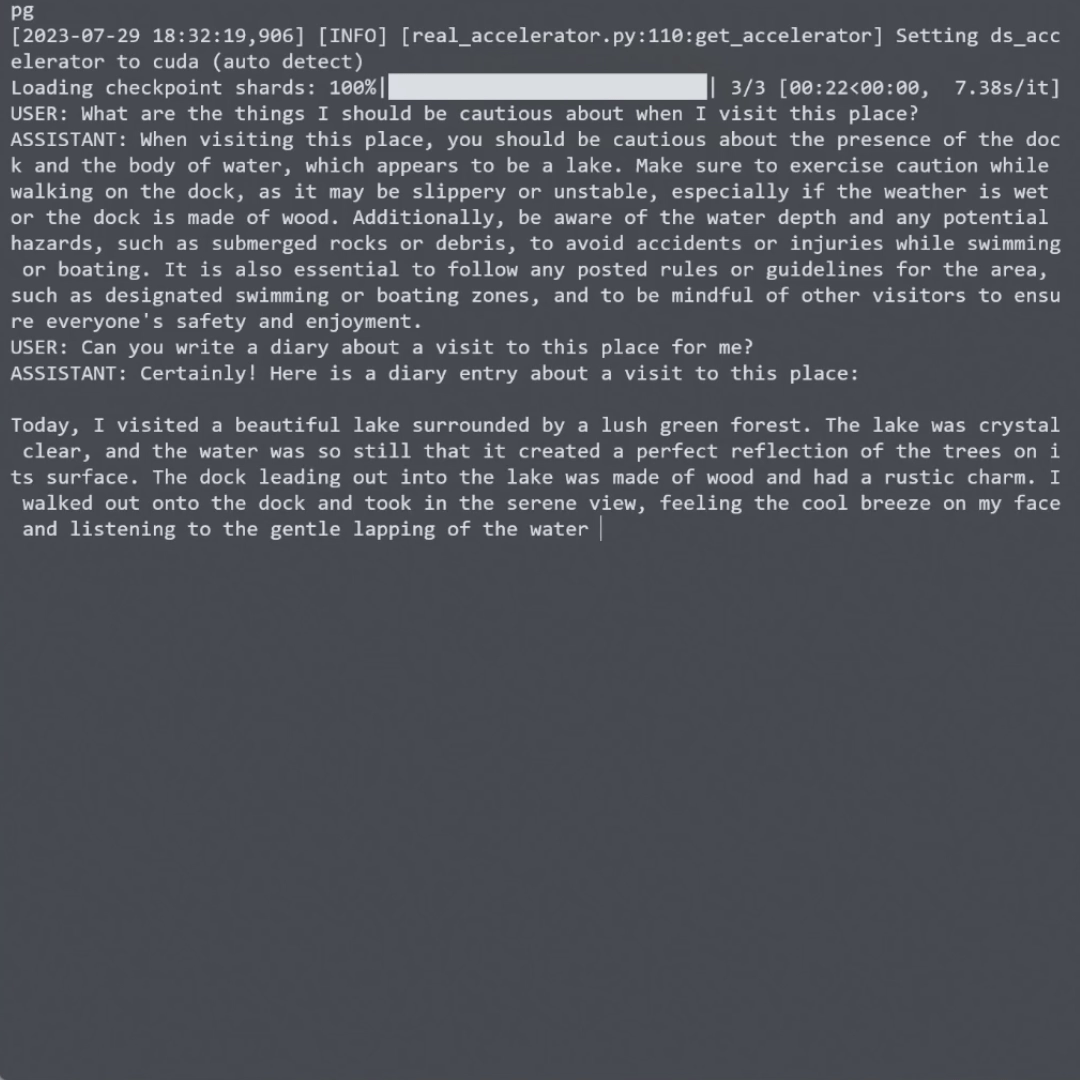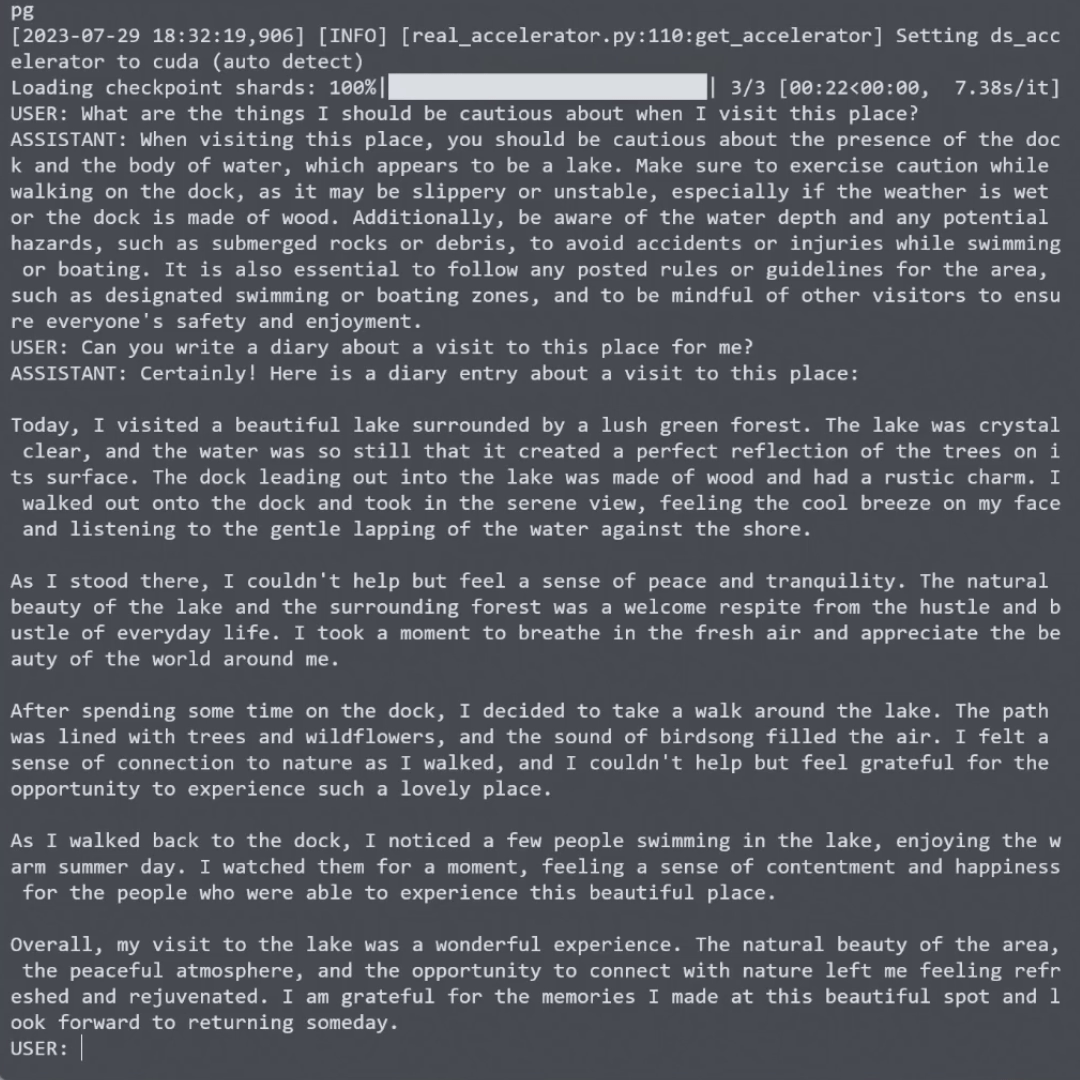
🚀 BakLLaVA正在快速发展中,欢迎关注项目GitHub页面以获取最新进展!










