
BentoDiffusion项目简介
BentoDiffusion是由BentoML团队开发的一个开源项目,旨在为使用BentoML部署和服务各种扩散模型提供完整的示例和指南。该项目涵盖了Stable Diffusion系列中的多个热门模型,包括SDXL、ControlNet、LCM等,为开发者提供了丰富的参考实现。
![]()
项目特点
-
多样化的模型支持: BentoDiffusion支持多种流行的扩散模型,如SDXL、ControlNet、LCM等,满足不同应用场景的需求。
-
完整的部署流程: 从环境配置、模型加载到服务部署,项目提供了端到端的实现指南。
-
性能优化: 利用BentoML的特性,实现了模型服务的高效部署和优化。
-
易于扩展: 项目结构清晰,便于开发者基于现有示例进行定制和扩展。
-
云端部署支持: 提供了BentoCloud部署的完整流程,方便模型服务的云端管理和扩展。
快速开始
以SDXL Turbo模型为例,我们来看看如何使用BentoDiffusion部署一个扩散模型服务:
- 克隆项目并安装依赖:
git clone https://github.com/bentoml/BentoDiffusion.git
cd BentoDiffusion/sdxl-turbo
pip install -r requirements.txt
- 运行BentoML服务:
bentoml serve .
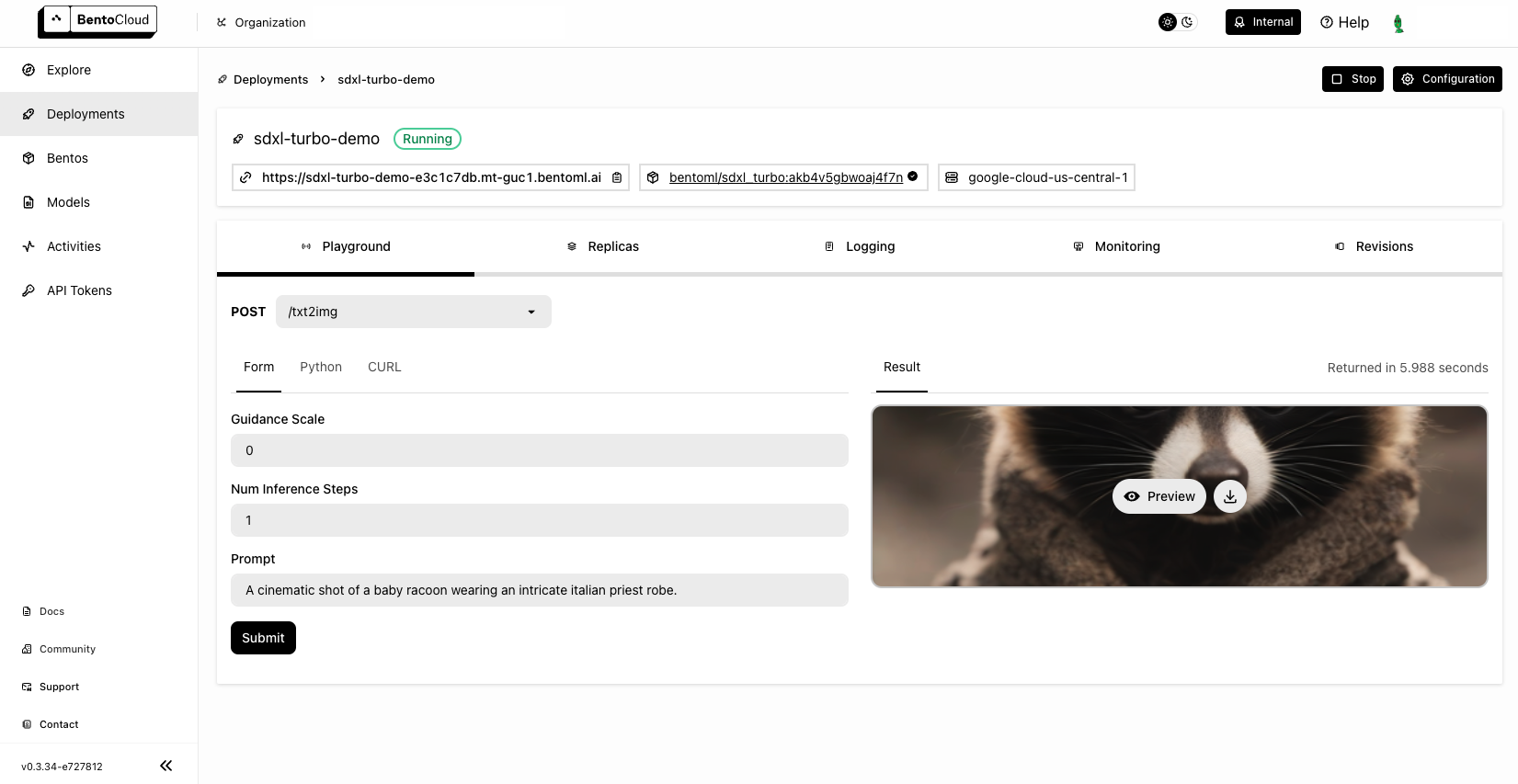
- 使用API生成图像:
import bentoml
with bentoml.SyncHTTPClient("http://localhost:3000") as client:
result = client.txt2img(
prompt="A cinematic shot of a baby racoon wearing an intricate italian priest robe.",
num_inference_steps=1,
guidance_scale=0.0
)
支持的模型
BentoDiffusion目前支持以下扩散模型:
- SDXL Turbo
- ControlNet
- Latent Consistency Model (LCM)
- Stable Diffusion 2 with 4x upscaler
- SDXL Lightning
- Stable Video Diffusion
每个模型都有独立的子目录,包含了完整的部署示例和说明文档。
深入理解服务代码
让我们以SDXL Turbo为例,深入了解一下服务代码的核心部分:
@bentoml.service(
traffic={
"timeout": 300,
"external_queue": True,
"concurrency": 1,
},
workers=1,
resources={
"gpu": 1,
"gpu_type": "nvidia-l4",
},
)
class SDXLTurbo:
def __init__(self) -> None:
from diffusers import AutoPipelineForText2Image
import torch
self.pipe = AutoPipelineForText2Image.from_pretrained(
MODEL_ID,
torch_dtype=torch.float16,
variant="fp16",
)
self.pipe.to(device="cuda")
@bentoml.api
def txt2img(
self,
prompt: str = sample_prompt,
num_inference_steps: int = 1,
guidance_scale: float = 0.0,
) -> Image:
image = self.pipe(
prompt=prompt,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
).images[0]
return image
这段代码定义了一个BentoML服务,具有以下特点:
-
使用
@bentoml.service装饰器定义服务配置,包括超时时间、并发数和GPU资源需求。 -
在
__init__方法中加载预训练模型,并将其移至GPU设备。 -
txt2img方法定义了API端点,接收文本提示和生成参数,返回生成的图像。
部署到BentoCloud
BentoDiffusion还提供了将服务部署到BentoCloud的指南。以下是基本步骤:
-
注册BentoCloud账户并获取访问令牌。
-
使用BentoML CLI登录BentoCloud:
bentoml cloud login
- 部署服务:
bentoml deploy .
部署完成后,你可以通过BentoCloud控制台管理和监控你的服务。
自定义和扩展
BentoDiffusion的设计使得开发者可以轻松地基于现有示例进行自定义和扩展:
-
添加新模型: 你可以参考现有模型的实现,为新的扩散模型创建子目录和服务代码。
-
优化性能: 通过调整BentoML服务配置,如并发数、批处理大小等,可以优化模型服务的性能。
-
集成其他功能: 你可以在服务中集成其他功能,如图像后处理、多模型集成等。
最佳实践
在使用BentoDiffusion部署扩散模型服务时,以下是一些建议的最佳实践:
-
资源管理: 根据模型大小和复杂度,合理配置GPU资源和内存需求。
-
批处理优化: 对于高并发场景,考虑实现批处理逻辑以提高吞吐量。
-
错误处理: 实现健壮的错误处理机制,确保服务的稳定性。
-
监控和日志: 利用BentoML和BentoCloud提供的监控和日志功能,及时发现和解决问题。
-
定期更新: 关注项目更新和新模型发布,及时更新你的服务以获得最新特性和性能改进。
总结
BentoDiffusion为使用BentoML部署扩散模型提供了一个强大而灵活的框架。通过本文的介绍,你应该对项目有了全面的了解,并能够开始使用BentoDiffusion来部署你自己的扩散模型服务。无论你是想快速部署一个现有模型,还是开发自定义的扩散模型服务,BentoDiffusion都为你提供了坚实的基础和丰富的参考实现。
随着AI技术的不断发展,像BentoDiffusion这样的工具将在推动扩散模型的实际应用中发挥越来越重要的作用。我们期待看到更多基于BentoDiffusion的创新应用和服务在未来涌现。












