
Bonito入门指南 - 无需GPT即可生成指令调优数据集的轻量级库
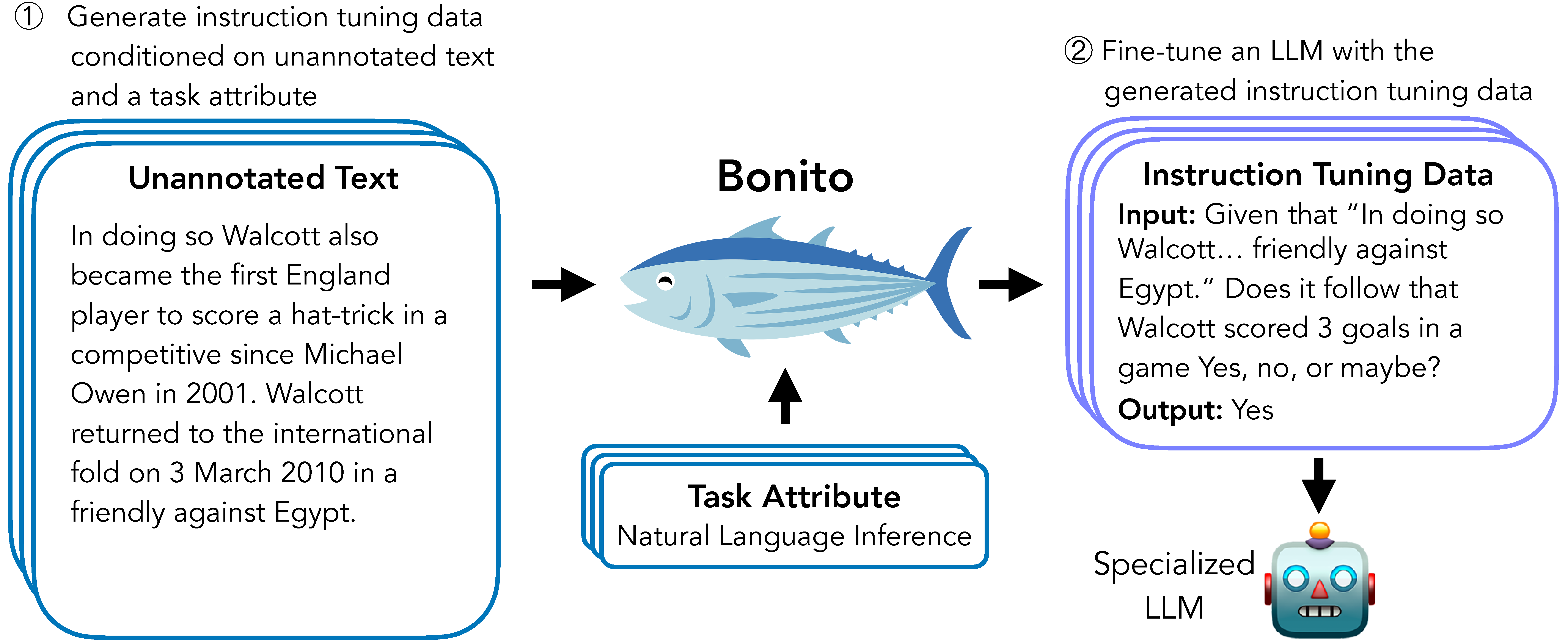
Bonito是一个开源模型,用于条件任务生成:将未标注文本转换为特定任务的指令调优训练数据集。它是一个轻量级库,可以轻松创建合成数据集,构建在Hugging Face的transformers和vllm库之上。
🐟 Bonito的主要特性
- 无需依赖GPT等大型语言模型
- 支持多种NLP任务类型的数据生成
- 轻量级设计,易于使用和集成
- 基于Hugging Face生态系统,兼容性好
📦 安装
使用以下命令创建环境并安装Bonito:
conda create -n bonito python=3.9
conda activate bonito
pip install -e .
🚀 基本用法
以下代码展示了如何使用Bonito生成合成指令调优数据集:
from bonito import Bonito
from vllm import SamplingParams
from datasets import load_dataset
# 初始化Bonito模型
bonito = Bonito("BatsResearch/bonito-v1")
# 加载未标注文本数据集
unannotated_text = load_dataset(
"BatsResearch/bonito-experiment",
"unannotated_contract_nli"
)["train"].select(range(10))
# 生成合成指令调优数据集
sampling_params = SamplingParams(max_tokens=256, top_p=0.95, temperature=0.5, n=1)
synthetic_dataset = bonito.generate_tasks(
unannotated_text,
context_col="input",
task_type="nli",
sampling_params=sampling_params
)
🎯 支持的任务类型
Bonito支持多种NLP任务类型,包括:
- 抽取式问答 (exqa)
- 多项选择问答 (mcqa)
- 问题生成 (qg)
- 开放式问答 (qa)
- 是非问答 (ynqa)
- 指代消解 (coref)
- 释义生成 (paraphrase)
- 释义识别 (paraphrase_id)
- 句子补全 (sent_comp)
- 情感分析 (sentiment)
- 文本摘要 (summarization)
- 文本生成 (text_gen)
- 主题分类 (topic_class)
- 词义消歧 (wsd)
- 文本蕴含 (te)
- 自然语言推理 (nli)
🔗 相关资源
🎓 教程
我们提供了两个Google Colab教程,帮助你快速上手Bonito:
通过Bonito,你可以轻松生成高质量的指令调优数据集,无需依赖昂贵的GPT模型。它为NLP研究和应用开辟了新的可能性,特别是在资源受限的场景下。快来尝试Bonito,探索条件任务生成的无限潜力吧!










