
diart: 构建实时音频AI应用的Python框架
diart是一个强大的Python框架,专门用于构建AI驱动的实时音频应用。它的核心功能是能够以最先进的性能实时识别不同的说话者,这项技术通常被称为'说话人分离'(speaker diarization)。diart不仅提供了高效的实时处理能力,还集成了多种先进的AI模型,使开发者能够轻松构建复杂的音频分析应用。
🌟 主要特性
-
实时说话人分离: diart的核心功能是能够在实时音频流中识别和区分不同的说话者。这项技术对于会议记录、实时字幕等应用至关重要。
-
灵活的流式处理: 框架支持从各种音频源进行流式处理,包括麦克风实时输入和预录音频文件。
-
预训练模型集成: diart集成了多个预训练模型,包括说话人分离、语音活动检测等,未来还将支持转录和说话人感知转录功能。
-
自定义管道构建: 开发者可以利用diart提供的构建块来创建自定义的AI管道,满足特定需求。
-
WebSocket支持: 框架兼容WebSocket协议,使得在Web环境中部署和使用变得更加便捷。
-
性能优化工具: 内置了基于optuna的优化器,可以帮助调整管道的超参数以获得最佳性能。
💻 安装与使用
安装diart非常简单,只需要确保系统满足一些基本依赖,然后通过pip进行安装:
pip install diart
使用diart处理音频流可以通过命令行或Python API实现。例如,使用命令行处理一段录音:
diart.stream /path/to/audio.wav
或者使用Python API进行更灵活的控制:
from diart import SpeakerDiarization
from diart.sources import MicrophoneAudioSource
from diart.inference import StreamingInference
pipeline = SpeakerDiarization()
mic = MicrophoneAudioSource()
inference = StreamingInference(pipeline, mic, do_plot=True)
prediction = inference()
🧠 模型与性能
diart支持多种预训练模型,包括分割模型和嵌入模型。以下是一些支持的模型及其性能数据:

这些模型在不同的硬件上有不同的性能表现,diart提供了详细的性能指标,帮助开发者选择最适合其应用场景的模型。
🔬 研究背景
diart是论文《Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation》的官方实现。这项研究提出了一种新颖的在线说话人分离方法,结合了增量聚类和局部分离技术,能够有效处理说话人重叠的情况。
研究团队开发的端到端重叠感知分割模型能够有效检测和分离重叠说话者。此外,他们还提出了一种修改版的统计池化层,可以对预测有同时说话者的帧赋予较低的权重,从而提高分离的准确性。
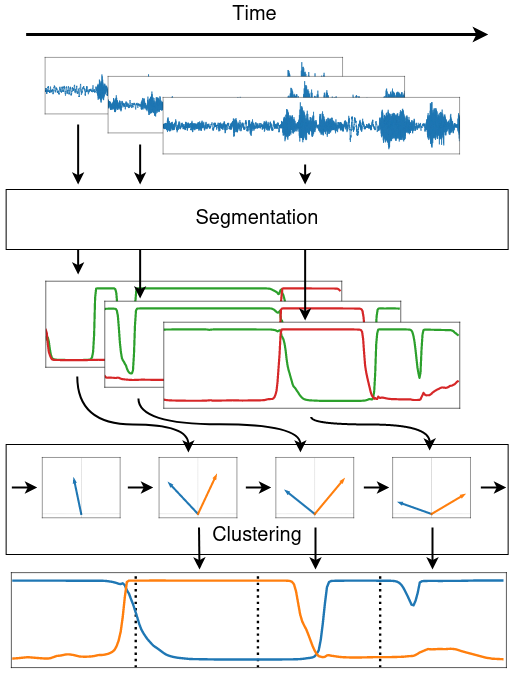
🌐 应用场景
diart框架的应用场景非常广泛,包括但不限于:
- 实时会议转录: 在多人会议中实时识别说话者并生成带说话人标识的转录。
- 广播内容分析: 对广播节目进行实时说话人分析,识别不同主持人和嘉宾。
- 客户服务质量监控: 在呼叫中心实时分析客户与服务人员的对话。
- 司法听证记录: 在法庭或听证会上实时记录并区分不同发言者。
- 多人播客制作: 为多人播客提供自动化的说话人标记和分离。
- 智能家居交互: 在智能家居系统中区分不同家庭成员的语音命令。
📈 未来展望
diart团队正在积极开发新功能,包括:
- 集成更多先进的预训练模型
- 改进实时转录功能
- 增强说话人感知转录的能力
- 优化WebSocket服务,提高在线部署的效率
- 扩展对多语言的支持
🤝 社区贡献
diart是一个开源项目,欢迎社区成员参与贡献。无论是报告问题、提出新功能建议,还是直接提交代码,都能帮助diart变得更好。项目遵循MIT许可证,确保了其在学术和商业领域的广泛应用。
🏆 结语
diart为实时音频AI应用的开发提供了一个强大而灵活的框架。无论是研究人员、开发者还是企业,都能从diart的功能中受益,快速构建出高性能的音频分析应用。随着语音技术在各个领域的重要性日益增加,diart无疑将在未来的AI驱动的音频处理中扮演重要角色。











