
BunkaTopics:洞察文本数据的利器
在当今数据驱动的世界中,从海量文本信息中提取有价值的洞察变得越来越重要。BunkaTopics应运而生,为研究人员、数据科学家和开发者提供了一个强大的工具,用于探索、分析和可视化大规模文本数据集。本文将深入介绍BunkaTopics的功能、特点和应用场景,帮助读者了解这一创新工具如何revolutionize文本数据分析领域。
BunkaTopics简介
BunkaTopics是一个专为数据清理、主题建模可视化和框架分析设计的Python包。它的主要目标是帮助开发者从非结构化数据中获取洞察,促进数据清理过程,并通过微调优化大型语言模型(LLMs)。BunkaTopics基于广受欢迎的库如sentence_transformers、langchain和transformers构建,确保了与各种环境的无缝集成。

核心功能
-
数据清理与微调优化:BunkaTopics提供了强大的功能,使用户能够控制数据,筛选相关信息并剔除无关数据。这对于实现精确的模型微调至关重要。
-
内容概览:通过高级的主题建模技术,BunkaTopics能够从大量文本中提取关键主题和趋势。例如,它可以深入分析Medium网站的技术类别,揭示其中包含的具体主题。
-
框架分析:BunkaTopics允许用户通过语义定制自己的坐标轴来可视化数据。这种灵活性使得数据分析可以根据特定目标和兴趣进行调整。
快速上手
要开始使用BunkaTopics,首先需要安装该包:
pip install bunkatopics
接下来,让我们通过一个简单的例子来展示BunkaTopics的基本用法:
from datasets import load_dataset
from sentence_transformers import SentenceTransformer
import umap
from bunkatopics import Bunka
from sklearn.cluster import KMeans
# 加载示例数据
docs = load_dataset("bunkalab/medium-sample-technology")["train"]["title"]
# 选择嵌入模型
embedding_model = SentenceTransformer(model_name_or_path="all-MiniLM-L6-v2")
# 设置投影模型
projection_model = umap.UMAP(n_components=2, random_state=42)
# 初始化Bunka
bunka = Bunka(embedding_model=embedding_model, projection_model=projection_model)
# 拟合数据
bunka.fit(docs)
# 获取主题
clustering_model = KMeans(n_clusters=15)
topics = bunka.get_topics(name_length=5, custom_clustering_model=clustering_model)
# 可视化主题
topic_fig = bunka.visualize_topics(width=800, height=800, colorscale='delta')
这个简单的示例展示了如何加载数据、提取主题并生成可视化结果。BunkaTopics的强大之处在于它能够处理大规模数据集,并提供直观的可视化输出。
高级特性
-
GenAI主题总结:BunkaTopics集成了生成式AI技术,能够自动为提取的主题生成简洁明了的总结。这大大提高了主题的可解释性和可读性。
-
Bourdieu地图:受法国社会学家布迪厄的启发,BunkaTopics提供了一种独特的2D可视化方法,称为Bourdieu地图。这种可视化技术能够在二维平面上展示文本数据的分布,揭示数据中的潜在结构和关系。
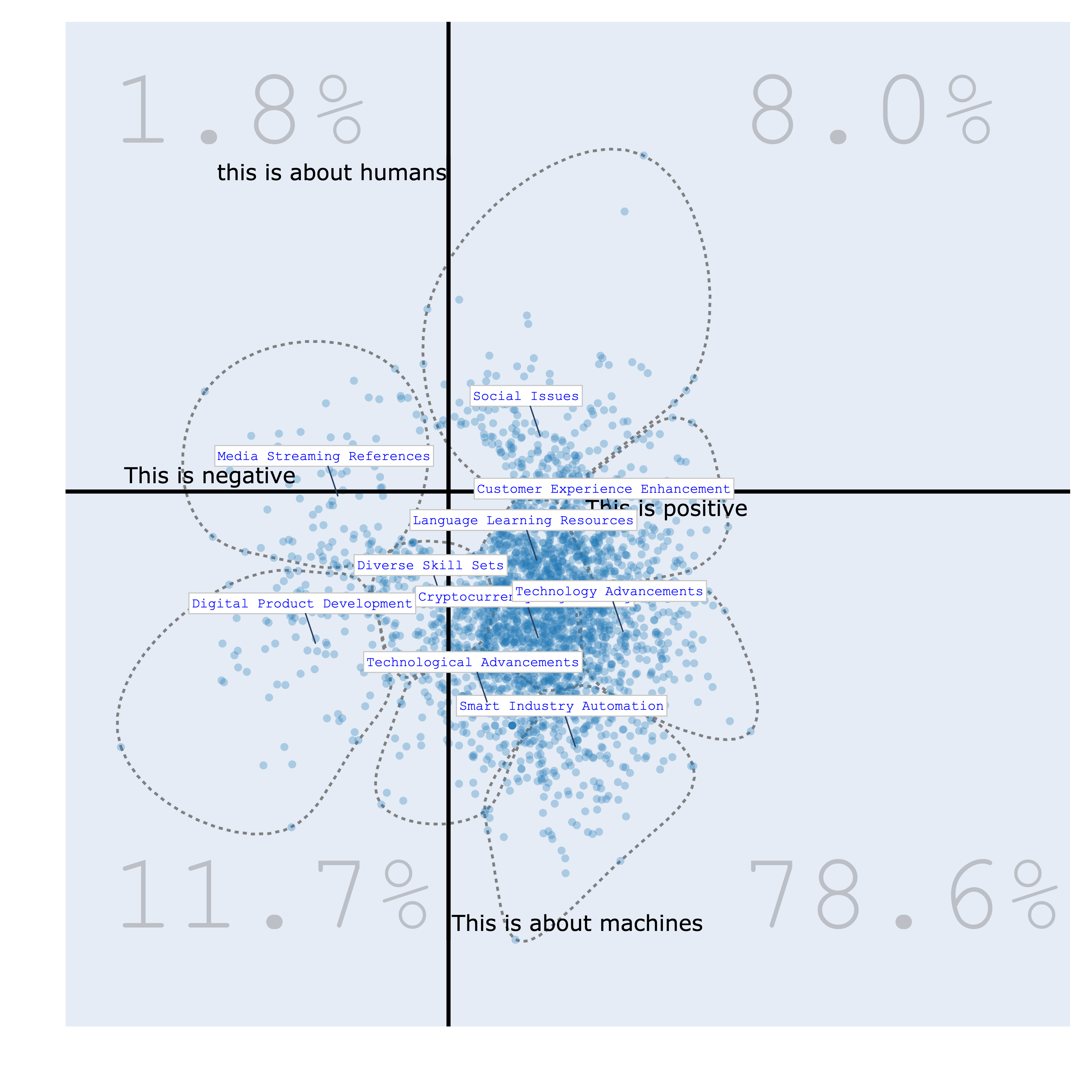
-
交互式数据清理:BunkaTopics提供了直观的界面,允许用户手动调整和优化主题。这对于微调大语言模型的训练数据集特别有用,用户可以轻松地排除不相关的主题或内容。
-
多语言支持:借助Spacy的语言模型,BunkaTopics能够处理多种语言的文本数据,为全球用户提供了强大的分析工具。
应用场景
-
内容分析与管理:对于拥有大量文本内容的平台(如Medium、博客网站等),BunkaTopics可以帮助管理者快速了解内容的主题分布,发现热门话题和新兴趋势。
-
学术研究:研究人员可以使用BunkaTopics分析大规模文献库,发现研究领域的主要主题和发展方向。
-
商业智能:企业可以利用BunkaTopics分析客户反馈、社交媒体数据等,洞察市场趋势和客户需求。
-
数据清理与预处理:在构建机器学习模型之前,数据科学家可以使用BunkaTopics清理和优化训练数据集,提高模型的质量和性能。
未来展望
BunkaTopics作为一个开源项目,正在不断发展和完善。未来,我们可以期待看到更多exciting的功能,例如:
- 与更多大语言模型的深度集成
- 更高级的可视化技术
- 实时数据流分析支持
- 更强大的跨语言分析能力
结语
BunkaTopics为文本数据分析和可视化领域带来了革命性的变化。它不仅提供了强大的分析工具,还通过直观的可视化方式使复杂的数据变得易于理解。无论您是数据科学家、研究人员还是企业分析师,BunkaTopics都能为您的工作带来显著的价值。
随着自然语言处理技术的不断进步,我们可以预见BunkaTopics将在未来扮演更加重要的角色,持续推动文本数据分析领域的创新和发展。现在就开始探索BunkaTopics吧,让它成为您洞察文本数据的得力助手!
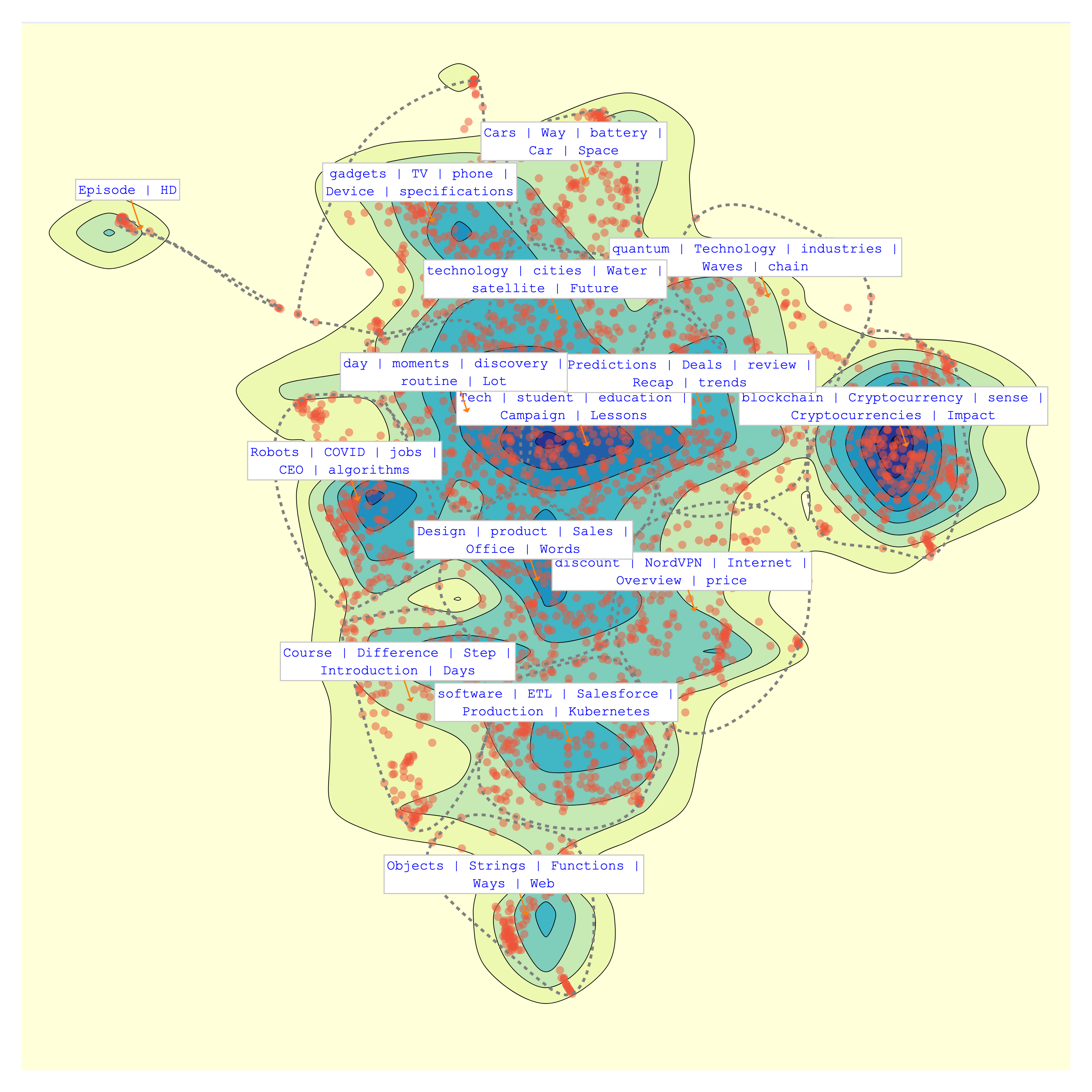
通过本文的介绍,相信读者已经对BunkaTopics有了全面的了解。这个强大的工具不仅能帮助我们更好地理解和分析文本数据,还能为数据驱动的决策提供有力支持。随着数据量的不断增长和分析需求的日益复杂,BunkaTopics无疑将成为数据科学家和研究人员的必备工具之一。








