
CareGPT简介
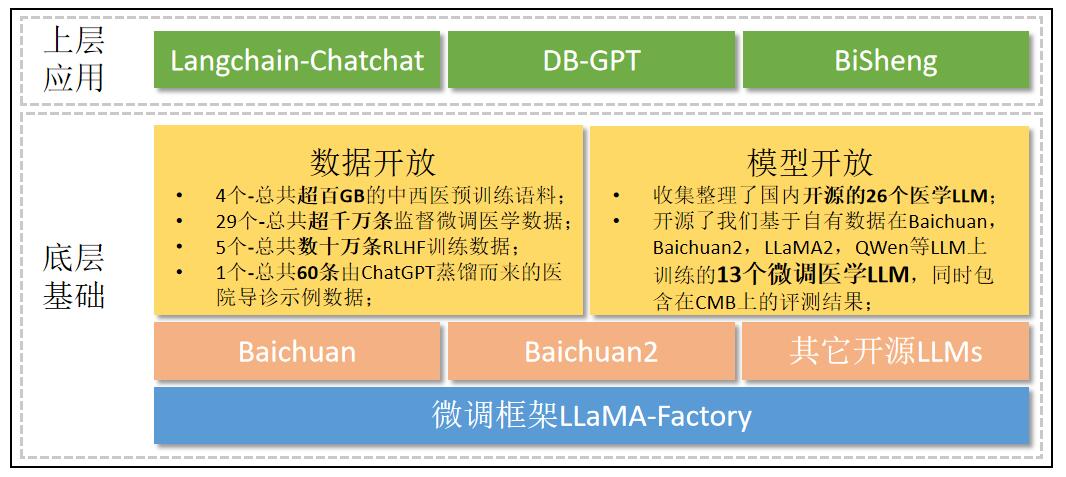
CareGPT(关怀GPT)是一个开源的医疗大语言模型项目,旨在促进医疗人工智能的发展。该项目由王荣胜等人发起,集合了数十个公开可用的医疗微调数据集和开放可用的医疗大语言模型,包含了LLM的训练、测评、部署等全流程内容。

主要资源
1. 代码库
CareGPT的核心代码库托管在GitHub上:
该仓库包含了模型训练、评估、部署的全部代码,以及详细的说明文档。
2. 数据集
CareGPT整理并开源了多个医疗领域数据集,主要包括:
- 预训练数据集
- 监督训练数据集
- 奖励训练数据集
其中比较重要的有:
- Huatuo-26M - 2600万中文医疗对话数据集
- CMB - 中文医学知识评测基准
- DISC-Med-SFT - 医疗指令微调数据集
完整的数据集列表可以在GitHub仓库的数据集部分查看。
3. 模型
CareGPT基于自有数据集在不同基座模型上训练了多个医疗LLM,包括:
- 基于LLaMA的医疗模型
- 基于LLaMA-2的医疗模型
- 基于BLOOMZ的医疗模型
这些模型可以在Hugging Face上下载使用。
4. 部署方法
CareGPT提供了多种部署和使用方式:
-
Web UI部署
python src/web_demo.py \ --model_name_or_path ./Llama-2-7b-chat-hf \ --checkpoint_dir output \ --finetuning_type lora \ --template llama2 -
API部署
python src/api_demo.py \ --model_name_or_path ./Llama-2-7b-chat-hf \ --checkpoint_dir output \ --finetuning_type lora \ --template llama2 -
CLI部署
python src/cli_demo.py \ --model_name_or_path ./Llama-2-7b-chat-hf \ --checkpoint_dir output \ --finetuning_type lora \ --template llama2 -
Gradio部署
-
ChatGPT-Next-Web部署
详细的部署说明可以参考GitHub仓库的部署部分。
学习路径
对于想要深入学习CareGPT的读者,建议按以下路径进行:
- 阅读项目README,了解项目整体架构
- 克隆代码仓库,按照说明配置环境
- 尝试使用提供的数据集和脚本训练一个简单的模型
- 学习如何部署和使用训练好的模型
- 深入研究代码,理解模型训练和优化的细节
- 尝试使用自己的数据集进行训练和微调
总结
CareGPT为医疗AI的研究和应用提供了宝贵的开源资源。无论您是研究人员、开发者还是医疗从业者,都可以从这个项目中获益。我们鼓励更多的人参与到CareGPT的开发中来,共同推动医疗AI的进步。
希望这篇资料汇总能帮助您更好地了解和使用CareGPT。如果您有任何问题或建议,欢迎在GitHub仓库中提出issue或贡献代码。让我们一起为开源医疗AI的未来贡献力量!










