
Chain of Hindsight: 革新语言模型的反馈学习
在人工智能和自然语言处理领域,如何让语言模型更好地理解和执行人类指令、符合人类价值观一直是一个重要而富有挑战性的问题。近日,来自加州大学伯克利分校的研究团队提出了一种名为"Chain of Hindsight"(CoH)的新方法,为解决这一问题带来了新的突破。
传统方法的局限性
传统的语言模型反馈学习方法主要面临两个问题:一是依赖人工挑选的模型生成结果,这在数据利用效率和普适性上存在不足;二是依赖强化学习,但不完善的奖励函数和复杂的优化过程常常使其效果不尽如人意。这些局限性促使研究者们寻求新的解决方案。
Chain of Hindsight的创新之处
Chain of Hindsight的核心思想是将所有类型的反馈转化为语言序列,并利用语言模型本身强大的语言理解能力来学习这些反馈。具体来说,该方法将模型生成的输出与相应的反馈配对,形成一个序列,然后用这些序列来微调模型。
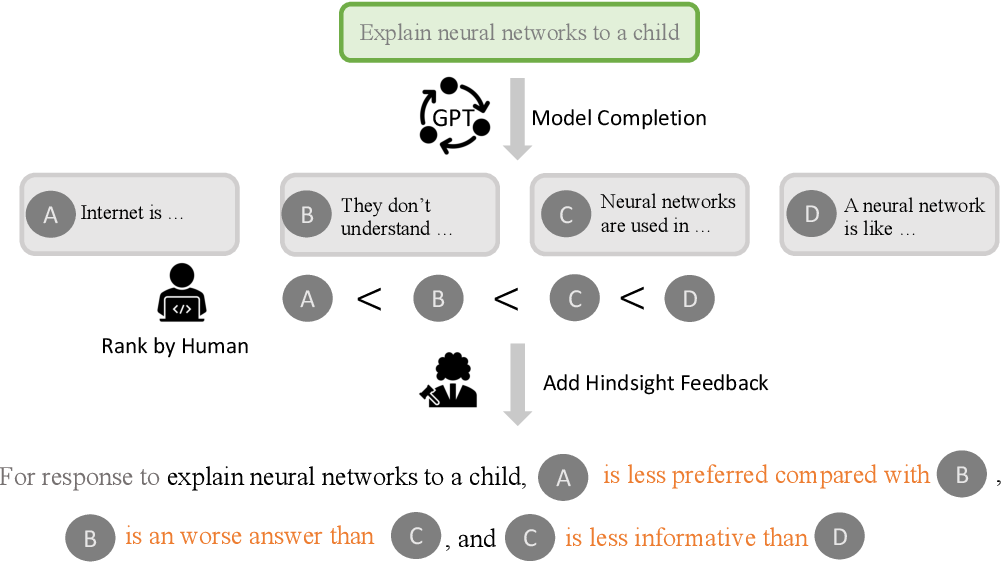
这种方法的优势在于:
- 可以学习任何形式的反馈,无论是正面还是负面。
- 充分利用了语言模型已有的语言理解能力。
- 通过学习识别和纠正负面特征或错误,提高了模型的性能。
实验结果令人瞩目
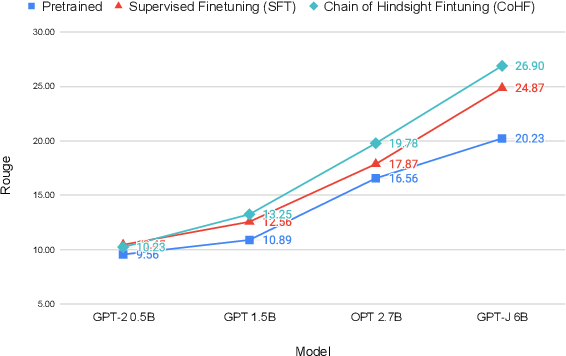
研究团队在多个基准测试上评估了Chain of Hindsight的性能,结果表明该方法显著优于之前的方法。在对话和摘要任务中,CoH训练的模型得到了人类评估者的高度认可。

这些结果充分证明了Chain of Hindsight在使语言模型与人类偏好保持一致方面的优越性。
技术实现细节
Chain of Hindsight的实现主要基于JAX框架,并支持多种大型语言模型,如LLaMA和GPT-J。研究团队还提供了详细的安装和使用说明,方便其他研究者复现和扩展这项工作。
主要步骤包括:
- 数据准备: 使用
pack_hf.py脚本生成训练所需的反馈数据。 - 模型训练: 通过
coh_train_llama或coh_train_gptj脚本进行模型微调。 - 模型评估: 可以使用
coh_serve_llama或coh_serve_gptj脚本启动一个服务器进行交互式评估。
python -m coh.data.pack_hf \
--output_dir='./' \
--dataset='dialogue,webgpt,summary' \
--include_feedback='p,n,pn,np'
这个命令用于生成包含多种反馈类型的训练数据。
应用前景广阔
Chain of Hindsight的应用前景非常广阔,不仅限于对话系统和文本摘要,还可以扩展到其他需要与人类偏好保持一致的自然语言处理任务中。例如:
- 内容生成: 可以帮助生成更符合用户偏好和道德标准的文章、广告文案等。
- 代码生成: 通过学习程序员的反馈,生成更高质量、更符合编程规范的代码。
- 教育辅助: 根据学生的反馈调整解释和教学内容,提供个性化的学习体验。
- 客户服务: 优化客服机器人的回复,使其更贴近客户需求和公司政策。
未来研究方向
尽管Chain of Hindsight取得了显著成果,但仍有许多值得探索的方向:
- 多模态反馈: 扩展该方法以处理图像、音频等多模态反馈。
- 长期记忆: 研究如何让模型从长期的反馈历史中学习,而不仅限于当前对话。
- 隐私保护: 探索在保护用户隐私的前提下,如何更有效地利用反馈数据。
- 跨语言适应: 研究如何将一种语言的反馈学习迁移到其他语言。
伦理考虑
在应用Chain of Hindsight时,研究者和开发者需要特别注意以下伦理问题:
- 数据偏见: 确保用于训练的反馈数据不包含有害的偏见。
- 透明度: 明确告知用户他们与AI系统交互,并解释系统如何利用反馈。
- 人机协作: 将Chain of Hindsight视为增强人类能力的工具,而非替代人类判断。
- 持续监督: 定期评估模型输出,确保其始终符合道德标准和社会价值观。
结语
Chain of Hindsight为语言模型的反馈学习开辟了一条新路,其简单而高效的方法有望在未来的AI系统中得到广泛应用。随着技术的不断发展和完善,我们可以期待看到更多智能、更贴近人类需求的语言模型出现,为各行各业带来革命性的变化。
作为研究人员、开发者或是对AI感兴趣的读者,我们都应该密切关注Chain of Hindsight及相关技术的发展。通过不断学习和实践,我们可以为构建更加智能、更加人性化的AI系统贡献自己的力量。
最后,让我们共同期待Chain of Hindsight为人工智能领域带来的更多惊喜和突破,推动语言模型向着更加智能、更加符合人类价值观的方向不断前进。
参考文献:
- Liu, H., Sferrazza, C., & Abbeel, P. (2023). Chain of Hindsight aligns Language Models with Feedback. arXiv preprint arXiv:2302.02676.
- Chain of Hindsight GitHub仓库
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., ... & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, 27730-27744.










