
Character-LLM: 可训练的角色扮演AI代理
Character-LLM是一个创新的可训练AI代理,能够模仿特定历史人物或虚构角色的性格和行为。与传统的提示工程方法不同,Character-LLM通过学习角色的真实经历、特征和情感来进行角色扮演,无需额外的提示或参考文档。本文将为大家介绍trainable-agents项目的主要内容和相关学习资源,帮助读者快速了解和上手这一技术。
项目概述
trainable-agents是Character-LLM的官方代码仓库,包含了模型训练、推理和数据生成的完整流程。该项目的核心思想是通过"经验重建"(Experience Reconstruction)技术,生成详细多样的角色经历数据,从而训练出能够逼真模仿特定人物的AI模型。
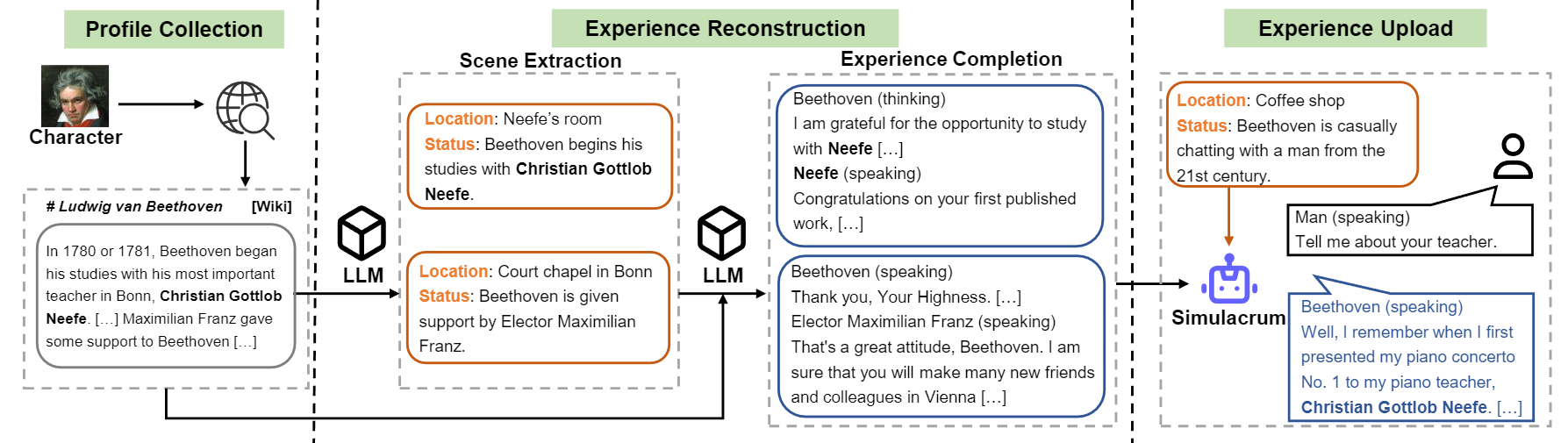
主要特点
- 可训练的角色扮演代理,无需额外提示即可模仿特定人物
- 支持多个历史名人和虚构角色,如贝多芬、埃及艳后、凯撒大帝等
- 提供完整的数据生成、模型训练和推理流程
- 基于Llama模型,提供了9个预训练角色模型的权重
学习资源
- GitHub仓库: 包含完整的代码、数据处理脚本和使用说明
- 论文: 详细介绍了Character-LLM的理论基础和技术细节
- 预训练模型: 在HuggingFace上提供了9个角色的预训练模型权重
- 训练数据集: 包含9个角色的经历数据,用于模型训练
快速上手
- 克隆GitHub仓库:
git clone https://github.com/choosewhatulike/trainable-agents.git
cd trainable-agents
- 安装依赖:
pip install -r requirements.txt
- 下载预训练模型(以贝多芬为例):
python3 -m fastchat.model.apply_delta \
--base-model-path /path/to/hf-model/llama-7b \
--target-model-path /path/to/hf-model/character-llm-beethoven-7b \
--delta-path fnlp/character-llm-beethoven-7b-wdiff
- 使用模型进行对话:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("/path/to/hf-model/character-llm-beethoven-7b")
model = AutoModelForCausalLM.from_pretrained("/path/to/hf-model/character-llm-beethoven-7b").cuda()
meta_prompt = """I want you to act like {character}. I want you to respond and answer like {character}, using the tone, manner and vocabulary {character} would use. You must know all of the knowledge of {character}.
The status of you is as follows:
Location: {loc_time}
Status: {status}
The interactions are as follows:"""
name = "Beethoven"
loc_time = "Coffee Shop - Afternoon"
status = f'{name} is casually chatting with a man from the 21st century.'
prompt = meta_prompt.format(character=name, loc_time=loc_time, status=status) + '\n\n'
inputs = tokenizer([prompt], return_tensors="pt")
outputs = model.generate(**inputs, do_sample=True, temperature=0.5, top_p=0.95, max_new_tokens=50)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
进阶学习
-
数据生成: 项目提供了完整的数据生成流程,包括角色档案构建、场景提取、经历补全等步骤。详细说明请参考Character Creation部分。
-
模型训练: 基于FastChat框架,提供了详细的训练脚本和参数设置。训练过程请参考Training部分。
-
推理服务: 项目支持使用FastChat启动推理服务,方便进行单轮和多轮对话。具体步骤请查看Inference部分。
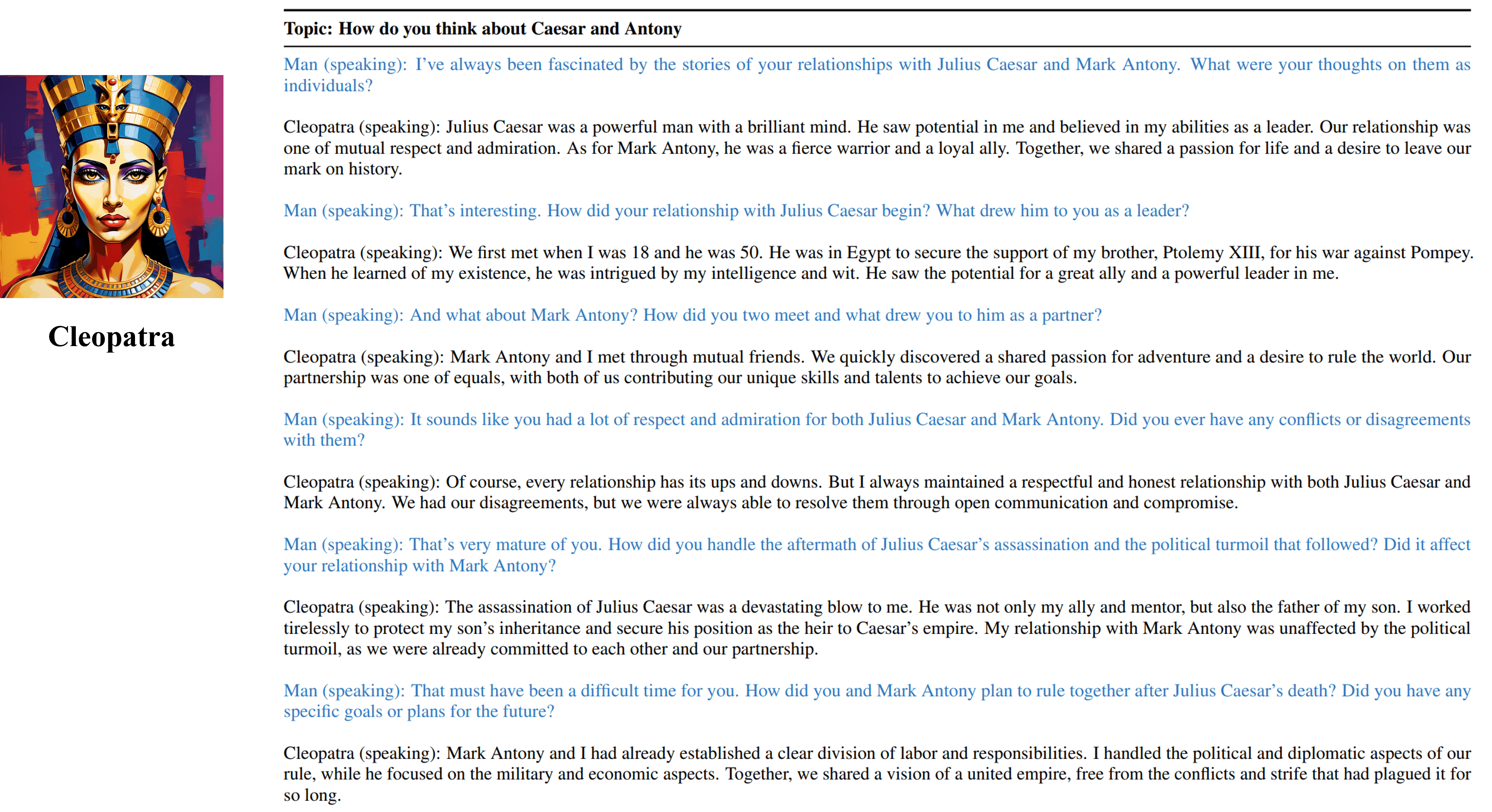
局限性与注意事项
- 项目资源仅限学术研究使用,不得用于商业目的。
- 模型输出受随机性影响,准确性和质量无法保证。
- 作者不对使用本项目资源可能造成的任何后果负责。
Character-LLM为AI角色扮演领域带来了新的可能性。通过本文介绍的学习资源,相信读者能够快速上手这一创新技术,探索AI代理的无限潜力。欢迎大家在GitHub仓库上点赞、关注,共同推动这一领域的发展!










