ChatGPT检索插件:提升AI对话的智能检索能力
 Ray
RayChatGPT检索插件:让AI对话更智能、更个性化
在人工智能快速发展的今天,如何让AI助手更好地理解和利用大量的个人或组织信息,成为了一个重要的研究方向。OpenAI推出的ChatGPT检索插件(ChatGPT Retrieval Plugin)正是为解决这一问题而生的强大工具。本文将深入探讨这个插件的功能、工作原理以及如何利用它来提升AI对话的智能程度。
什么是ChatGPT检索插件?
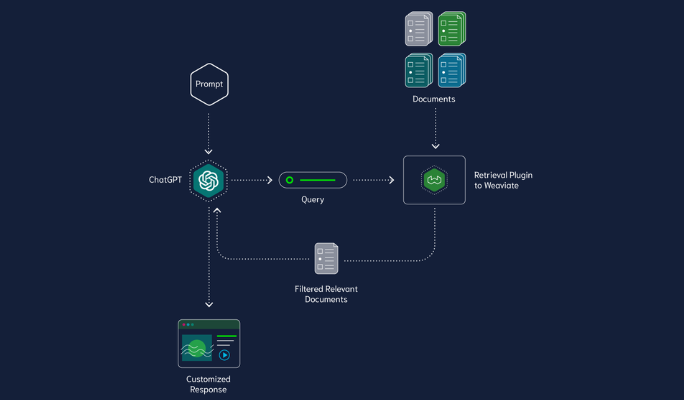
ChatGPT检索插件是一个独立的检索后端,它可以与多种AI应用场景结合使用,包括ChatGPT自定义GPT、函数调用以及聊天完成或助手API等。这个插件的核心功能是实现语义搜索和文档检索,让AI模型能够根据自然语言查询或需求,获取最相关的文档片段。
这个插件的主要特点包括:
- 语义搜索:使用OpenAI的嵌入模型生成文档片段的嵌入向量,并存储在向量数据库中进行检索。
- 灵活性:支持多种向量数据库提供商,开发者可以根据需求选择合适的存储方案。
- API接口:提供了用于上传、查询和删除文档的FastAPI服务器端点。
- 元数据过滤:用户可以使用来源、日期、作者等元数据来精确筛选搜索结果。
- 开源性:作为一个开源解决方案,开发者可以自由部署和定制自己的检索插件。
如何工作?
ChatGPT检索插件的工作流程可以概括为以下几个步骤:
- 文档处理:将输入的文档分割成大约200个标记的小块,每个块都有唯一的ID。
- 嵌入生成:使用OpenAI的嵌入模型(默认为text-embedding-3-large)为每个文档块生成嵌入向量。
- 向量存储:将生成的嵌入向量存储在选定的向量数据库中。
- 查询处理:当收到自然语言查询时,插件会将查询转换为嵌入向量,并在向量数据库中搜索最相关的文档块。
- 结果返回:将检索到的相关文档块及其元数据返回给AI模型,以供进一步处理和回答。
与自定义GPT的结合
要创建一个能够使用检索插件进行语义搜索和文档检索的自定义GPT,开发者需要遵循以下步骤:
- 部署检索插件并获取应用URL。
- 在ChatGPT的GPT编辑器中创建新的GPT。
- 在"Configure"标签页中设置GPT的基本信息。
- 在"Actions"部分添加新的操作,选择适当的认证方法。
- 导入OpenAPI模式,可以直接从应用URL导入或手动粘贴模式内容。
- 根据需要,可以添加额外的端点,如fetch或upsert,以增强GPT的功能。
通过这些步骤,开发者可以创建一个能够智能检索和利用个人或组织文档的自定义GPT,从而提供更加个性化和知识丰富的对话体验。
函数调用与检索插件的结合
ChatGPT检索插件不仅可以与自定义GPT结合使用,还可以通过函数调用在聊天完成API和助手API中发挥作用。这种方式允许模型根据对话上下文决定何时使用插件提供的函数(如查询、获取、更新等)。
在使用聊天完成API时,开发者可以定义检索插件端点的函数,并将其作为工具传递给最新的模型(如gpt-3.5-turbo-0125或gpt-4-turbo-preview)。模型会智能地调用这些函数,执行查询、调用后端API,并将响应作为工具消息返回给模型以继续对话。
对于助手API,开发者可以使用相同的函数定义,特别是在工具使用中的函数调用。这使得开发者能够在自己的应用程序中构建利用模型、工具和知识来响应用户查询的AI助手。
值得注意的是,这两种API都支持并行函数调用,这意味着�可以在同一条消息中执行多个任务,例如同时查询信息和将新信息保存回向量数据库。
记忆功能:让AI助手更懂你
ChatGPT检索插件的一个重要特性是它能够为AI模型提供"记忆"功能。通过使用插件的upsert端点,ChatGPT可以将对话中的重要片段保存到向量数据库中,以便日后参考。这个功能大大提升了聊天体验的上下文感知能力,使AI助手能够记住并检索之前对话中的信息。
要配置带有记忆功能的检索插件,开发者需要在OpenAPI模式中包含/upsert端点,并在GPT的指令中添加适当的提示,以便在用户要求时保存重要信息。这样,AI助手就能在长期对话中表现出更强的连贯性和个性化。
安全性考虑
在使用ChatGPT检索插件时,安全性是一个重要的考虑因素。插件允许ChatGPT搜索向量数据库中的内容,并将最佳结果添加到ChatGPT会话中。这意味着主要的风险涉及数据授权和隐私。
开发者应该只将他们有授权的内容添加到检索插件中,并且这些内容应该是他们愿意出现在用户的ChatGPT会话中的。为了保护插件的安全,开发者可以选择多种认证方法,如API密钥(基本或Bearer)和OAuth等。
选择合适的嵌入模型
ChatGPT检索插件默认使用OpenAI的text-embedding-3-large模型生成256维的嵌入向量。然而,OpenAI提供了多个嵌入模型选项,包括text-embedding-3-small和较旧的text-embedding-ada-002。
在选择嵌入模型时,开发者需要考虑以下几个因素:
- 检索准确性与成本:
text-embedding-3-large提供最高的准确性,但成本也较高。text-embedding-3-small在成本效益和准确性之间取得了很好的平衡。 - 嵌入大小:较大的嵌入提供更好的准确性,但会消耗更多存储空间��,查询速度可能较慢。
- 向量数据库的支持:确保选择的嵌入大小与所使用的向量数据库兼容。
通过调整环境变量EMBEDDING_DIMENSION和EMBEDDING_MODEL,开发者可以根据自己的需求选择最合适的嵌入模型和大小。
选择向量数据库
ChatGPT检索插件支持多种向量数据库提供商,每种都有其独特的特性、性能和定价模型。以下是一些常用的选项:
- Pinecone:管理型向量数据库,专为速度、规模和快速部署而设计。
- Weaviate:开源向量搜索引擎,支持混合搜索,可自托管或托管。
- Zilliz:托管的云原生向量数据库,适用于十亿级数据。
- Qdrant:支持存储文档和向量嵌入的向量数据库,提供自托管和托管选项。
- Chroma:AI原生开源嵌入数据库,易于上手和使用。
- Azure Cognitive Search:完整的云检索服务,支持向量搜索、文本搜索和混合搜索。
选择合适的向量数据库时,开发者需要考虑因素如性能需求、数据规模、部署灵活性、成本等。每种数据库都有其优势和适用场景,开发者应根据项目需求仔细评估和选择。
实际应用场景
ChatGPT检索插件在多个领域都有广泛的应用前景:
- 客户支持:企业可以利用插件提供更准确、更有帮助的客户问题解答,快速解决问题。
- 内容创作:企业可以使用插件获取可靠的信息,创建更有价值、更可信的内容。
- 市场研究:插件可以提供外部数据和行业、趋势、竞争对手的洞察,帮助企业更好地了解市场。
- 员工培训:利用插件可以创建更加精准和有效的培训材料,加速员工学习过程。

结语
ChatGPT检索插件为AI对话带来了新的可能性。通过实现智能的语义搜索和文档检索,它使AI助手能够更好地理解和利用大量的个人或组织信息,从而提供更加智能、个性化的对话体验。无论是在客户服务、内容创作、市场研究还是员工培训等领域,这个插件都展现出了巨大的应用潜力。
随着技术的不断发展,我们可以期待看到更多创新的应用场景。对于开发者来说,深入了解和掌握ChatGPT检索插件的使用方法,将有助于创建更加强大和智能的AI应用,为用户带来更大的价值。
通过遵循本文介绍的步骤和最佳实践,开发者可以轻松地将自己的知识库整合到ChatGPT数据存储中,并开始利用这一强大工具。未来,随着更多开发者的参与和贡献,我们有理由相信ChatGPT检索插件将继续evolve,为AI对话技术带来更多突破性的进展。
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号