
ChatLLM-Web: 浏览器中的AI对话革命
在人工智能和自然语言处理技术飞速发展的今天,ChatLLM-Web项目为我们带来了一次革命性的突破。这个创新的Web应用允许用户直接在浏览器中与大型语言模型(LLM)进行对话,无需任何服务器支持,同时保证了用户的安全和隐私。让我们深入了解这个令人兴奋的项目,探索它如何改变我们与AI交互的方式。
项目概览
ChatLLM-Web是由开发者Ryan-yang125创建的开源项目,旨在让用户能够在浏览器中与像Vicuna这样的大型语言模型进行对话。该项目利用了WebGPU技术,实现了在客户端运行复杂的AI模型,这意味着所有的处理都在用户的设备上完成,无需将数据发送到远程服务器。
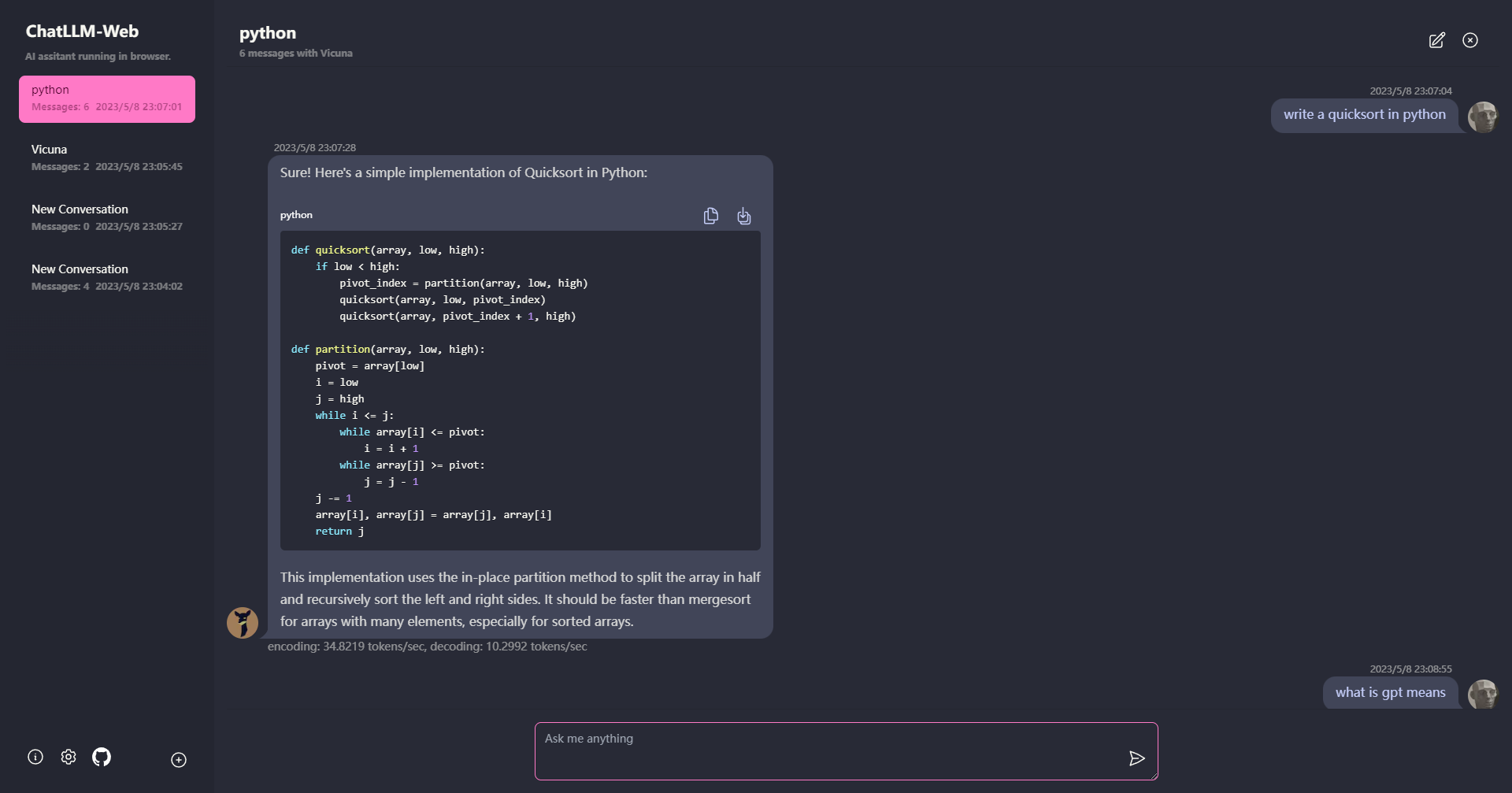
核心特性
-
浏览器端运行: 整个AI模型在浏览器中运行,通过WebGPU加速,无需服务器支持。
-
Web Worker技术: 模型在Web Worker中运行,确保不会阻塞用户界面,提供流畅的体验。
-
一键部署: 用户可以在Vercel上轻松部署自己的ChatLLM-Web实例,只需不到1分钟。
-
模型缓存: 支持模型缓存,用户只需下载一次模型即可。
-
多会话支持: 支持多个对话会话,所有数据本地存储,保护用户隐私。
-
Markdown和流式响应: 支持Markdown格式,包括数学公式、代码高亮等功能。
-
响应式设计: 提供包括暗黑模式在内的精心设计的用户界面。
-
PWA支持: 可作为渐进式Web应用使用,支持离线运行。
技术实现
ChatLLM-Web的核心是基于web-llm项目,这是一个允许在Web浏览器中运行大型语言模型的创新技术。项目使用了最新的Web技术,包括:
- WebGPU: 用于在浏览器中进行高性能计算。
- React: 构建用户界面。
- Next.js: 提供服务端渲染和静态站点生成能力。
- TypeScript: 确保代码的类型安全。
使用指南
要使用ChatLLM-Web,用户需要:
- 使用支持WebGPU的浏览器,如Chrome 113或更高版本。
- 拥有至少6.4GB显存的GPU。如果显存较少,应用仍可运行,但响应时间会较慢。
- 首次使用时需要下载模型,目前使用的Vicuna-7b模型大小约为4GB。
部署自己的实例
ChatLLM-Web的一大亮点是其易于部署的特性。用户可以通过以下步骤在Vercel上部署自己的实例:
- 点击项目README中的"Deploy with Vercel"按钮。
- 按照指示完成部署过程,整个过程不超过1分钟。
这种简单的部署方式使得任何人都可以轻松拥有自己的AI对话平台,无需复杂的服务器配置和维护。
开发路线图
ChatLLM-Web项目有着雄心勃勃的发展计划,包括:
- 支持多种语言模型,如RedPajama-INCITE-Chat-3B。
- 增加更多设置选项,如GPU设备选择、缓存管理等。
- 支持模型参数配置,如温度、最大长度等。
- 实现模型导出和导入功能。
这些计划显示了项目团队对持续改进和扩展功能的承诺,为用户提供更加灵活和强大的AI对话工具。
社区反响
自发布以来,ChatLLM-Web在GitHub上已获得了超过600颗星,这证明了开发者社区对这种创新技术的浓厚兴趣。项目的开源性质也吸引了多位贡献者参与开发,推动了项目的快速迭代和改进。
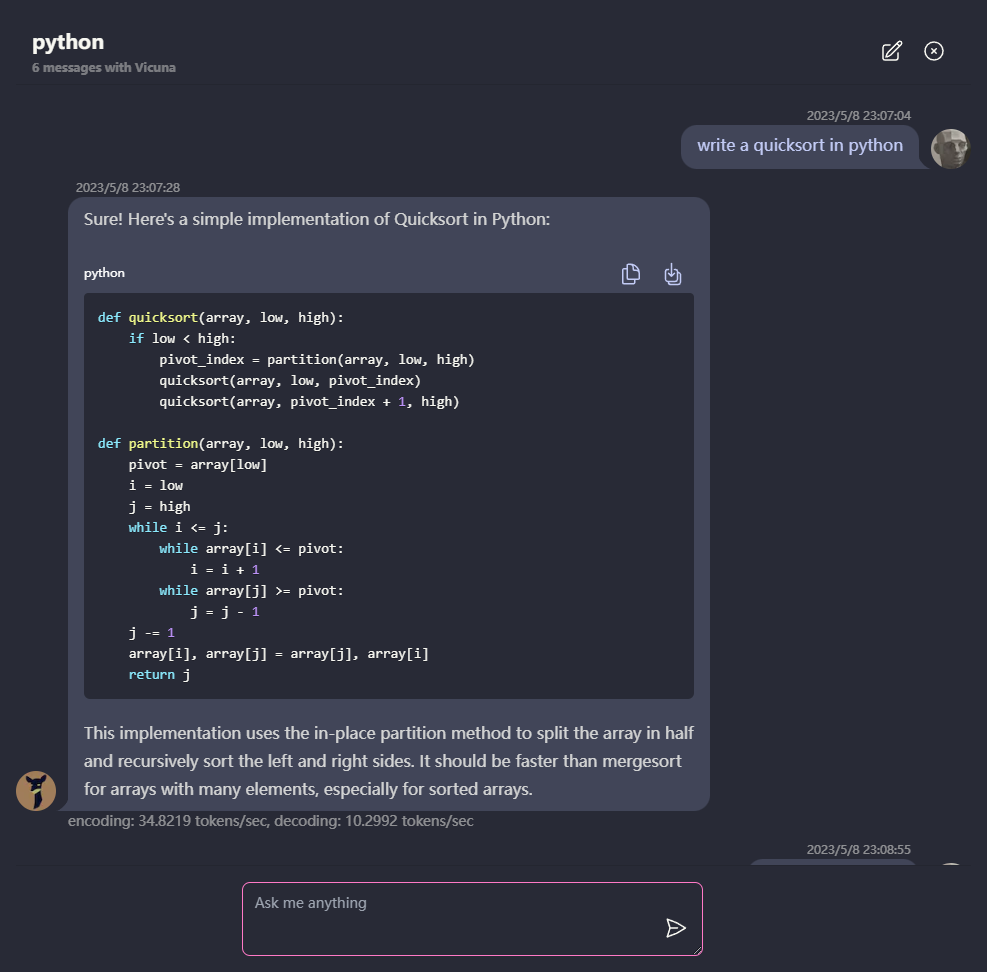
未来展望
随着WebGPU技术的成熟和浏览器支持的增加,我们可以预见ChatLLM-Web这样的项目将在未来发挥更大的作用。它不仅为个人用户提供了便捷的AI对话工具,也为企业和开发者提供了一种新的AI应用部署方式。
可以想象,未来我们可能会看到更多基于这种技术的应用,如:
- 个性化的AI助手,完全运行在用户设备上,保护隐私。
- 教育领域的智能辅导系统,无需复杂的后端设施。
- 离线工作的AI写作助手,适用于各种场景。
结语
ChatLLM-Web代表了AI技术与Web技术融合的一个重要里程碑。它展示了如何将复杂的AI模型带到用户的浏览器中,提供安全、私密且高效的对话体验。对于开发者来说,这个项目提供了宝贵的学习资源和灵感;对于用户来说,它开启了一个全新的AI交互方式。
随着项目的不断发展和完善,我们有理由相信,ChatLLM-Web将继续推动Web-based AI应用的边界,为更多创新应用铺平道路。无论你是AI爱好者、Web开发者,还是对未来技术感兴趣的普通用户,都值得关注这个令人兴奋的项目。
访问ChatLLM-Web GitHub仓库了解更多信息,或者直接体验在线演示,感受AI对话的未来。让我们一起期待ChatLLM-Web带来的更多可能性!









