中文预训练自然语言处理模型的发展与应用
 Ray
Ray中文预训练自然语言处理模型的蓬勃发展
近年来,随着深度学习技术的快速进步,预训练语言模型在自然语言处理(NLP)领域取得了突破性的进展。特别是在中文NLP领域,各种高质量的预训练模型层出不穷,极大地推动了相关技术和应用的发展。本文将全面介绍中文预训练NLP模型的发展历程、主要类型以及最新进展,并探讨这些模型的广泛应用前景。
中文预训练模型的发展历程
预训练语言模型的概念最早可以追溯到2018年,当时Google发布的BERT模型在多项NLP任务上取得了突破性的成果。此后,预训练模型的研究如火如荼,各种改进版本和新架构不断涌现。在中文NLP领域,也随即掀起了预训练模型的研究热潮。
最初的中文预训练模型主要是在BERT的基础上进行改进,如哈工大发布的Chinese-BERT-wwm、智源研究院的ERNIE等。这些模型通过优化预训练任务、扩大训练数据等方式,使模型更好地适应中文语言的特点。随后,RoBERTa、ALBERT、ELECTRA等新的预训练架构被引入中文领域,进一步提升了模型性能。
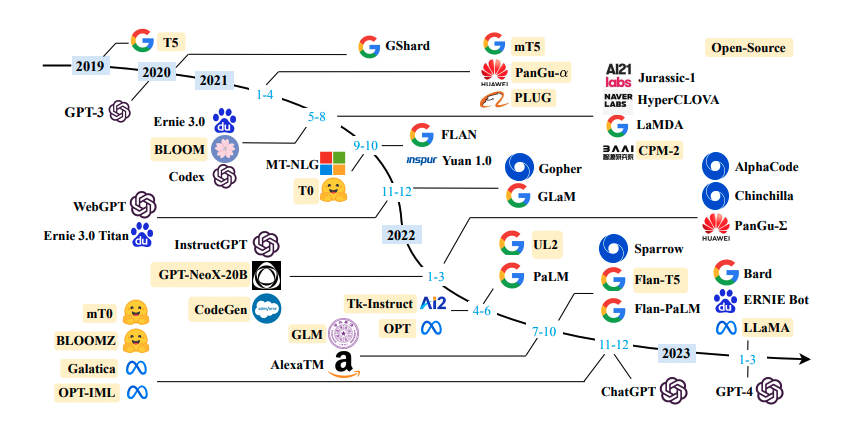
2020年以来,大规模预训练模型成为研究热点。以GPT-3为代表的超大规模语言模型展现出了惊人的能力,引发了学术界和产业界的广泛关注。在中文领域,也相继出现了一批大规模预训练模型,如华为的盘古α、智源的悟道、百度的文心等。这些模型的参数规模从数十亿到数千亿不等,在多项任务上展现出了强大的性能。
中文预训练模型的主要类型
目前,中文预训练NLP模型主要可以分为以下几类:
-
NLU(自然语言理解)系列:以BERT及其变体为代表,主要用于文本分类、命名实体识别、问答等理解类任务。代表模型包括BERT、RoBERTa、ALBERT、ERNIE等。
-
NLG(自然语言生成)系列:以GPT为代表,主要用于文本生成、对话等生成类任务。代表模型包括GPT、CPM、PanGu-α等。
-
NLU-NLG融合系列:结合了理解和生成能力的模型,如UniLM、T5等。这类模型在多种任务上都表现出色。
-
多模态模型:除了处理文本,还能处理图像、语音等多模态数据的模型。如文澜、CogView等。
-
大规模基础模型:参数规模达到数十亿甚至数千亿的超大模型,如ERNIE 3.0 Titan、智源PLUG等。
最新进展与技术趋势
在中文预训练NLP模型领域,最新的技术趋势主要体现在以下几个方面:
-
模型规模持续增大:从最初的亿级参数,到现在的千亿级参数,模型规模不断突破。大模型展现出了强大的few-shot甚至zero-shot学习能力。
-
多任务学习与迁移学习:通过在预训练阶段引入多种任务,提高模型的通用性和迁移能力。如ERNIE 3.0采用了多任务训练策略。
-
长文本建模:改进模型架构,提高对长文本的处理能力。如Longformer、BigBird等模型引入了稀疏注意力机制。
-
知识融合:将结构化知识融入预训练过程,提升模型的知识理解能力。如K-BERT、ERNIE等模型。
-
效率优化:通过模型压缩、知识蒸馏等技术,降低模型计算复杂度,提高推理效率。
-
多模态融合:将文本、图像、语音等多模态信息融合,构建统一的表示空间。如文澜、M6等模型。
广泛的应用前景
中文预训练NLP模型在各个领域都展现出了广阔的应用前景:
-
智能客服:利用模型的对话能力,构建智能客服系统,提高服务效率。
-
内容生成:用于自动写作、新闻摘要、广告文案生成等任务。
-
信息抽取:从非结构化文本中抽取结构化信息,用于知识图谱构建等。
-
机器翻译:提升翻译质量,特别是在低资源语言对上。
-
情感分析:分析文本情感倾向,用于舆情监测、用户反馈分析等。
-
智能问答:构建问答系统,用于知识问答、阅读理解等场景。
-
文本分类:用于新闻分类、垃圾邮件过滤、意图识别等任务。
-
多模态应用:结合图像识别、语音识别等技术,开发更智能的人机交互系统。
面临的挑战与未来展望
尽管中文预训练NLP模型取得了巨大进展,但仍面临一些挑战:
-
计算资源需求:大规模模型的训练和部署需要海量的计算资源,限制了其广泛应用。
-
数据质量:高质量的中文语料相对缺乏,影响模型的训练效果。
-
模型解释性:大型神经网络模型往往是"黑盒",其决策过程难以解释。
-
伦理问题:大语言模型可能产生偏见、歧视等不当内容,需要加强伦理约束。
-
版权问题:使用网络数据训练模型可能涉及版权纠纷。
未来,中文预训练NLP模型的研究可能会朝以下方向发展:
-
更高效的模型架构:降低计算复杂度,提高训练和推理效率。
-
可控性增强:提高模型输出的可控性和一致性。
-
知识融合:更好地将领域知识融入模型,提升理解能力。
-
多模态融合:构建统一的多模态表示空间,实现跨模态理解和生成。
-
小样本学习:提高模型在少量样本下的学习能力。
-
可解释性研究:提高模型决策的可解释性和透明度。
-
伦理与安全:加强模型的伦理约束和安全性研究。
结语
中文预训练NLP模型的蓬勃发展为自然语言处理技术带来了革命性的进步。这些模型不仅大大提升了各种NLP任务的性能,还开启了许多新的应用可能。随着技术的不断进步和创新,我们有理由相信,中文预训练NLP模型将在未来发挥更加重要的作用,为人工智能和智能信息处理领域带来更多突破。
研究者和开发者可以关注awesome-pretrained-chinese-nlp-models项目,该项目收集了大量高质量的中文预训练NLP模型资源,为相关研究和应用提供了宝贵的参考。同时,我们也期待看到更多创新性的研究成果和应用案例,推动中文NLP技术的进一步发展.
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片��或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号