
Cleanlab:革新数据中心AI的开源利器
在人工智能和机器学习快速发展的今天,数据质量已成为制约AI进步的关键瓶颈。来自MIT的开源项目Cleanlab应运而生,为解决这一问题提供了强有力的工具。Cleanlab是一个专注于数据中心AI的Python包,能够自动检测和修复机器学习数据集中的各种问题,帮助用户清理数据、改进标签,从而训练出更加强大和可靠的AI模型。
Cleanlab的核心功能
Cleanlab的核心功能在于其强大的数据问题检测和修复能力。它可以自动识别出数据集中的异常值、重复数据、标签错误等问题,并提供修复建议。具体来说,Cleanlab能够:
- 自动检查图像、文本、音频和表格等各类数据集
- 检测数据问题,如离群值、重复项、标签错误等
- 训练稳健的模型,能更好地处理噪声数据
- 为多标注者数据推断共识标签和标注者质量
- 应用主动学习,建议下一步应标注或重新标注的数据
Cleanlab的这些功能使得它成为了数据科学家和机器学习工程师的得力助手,大大提高了数据处理和模型训练的效率。
Cleanlab的工作原理
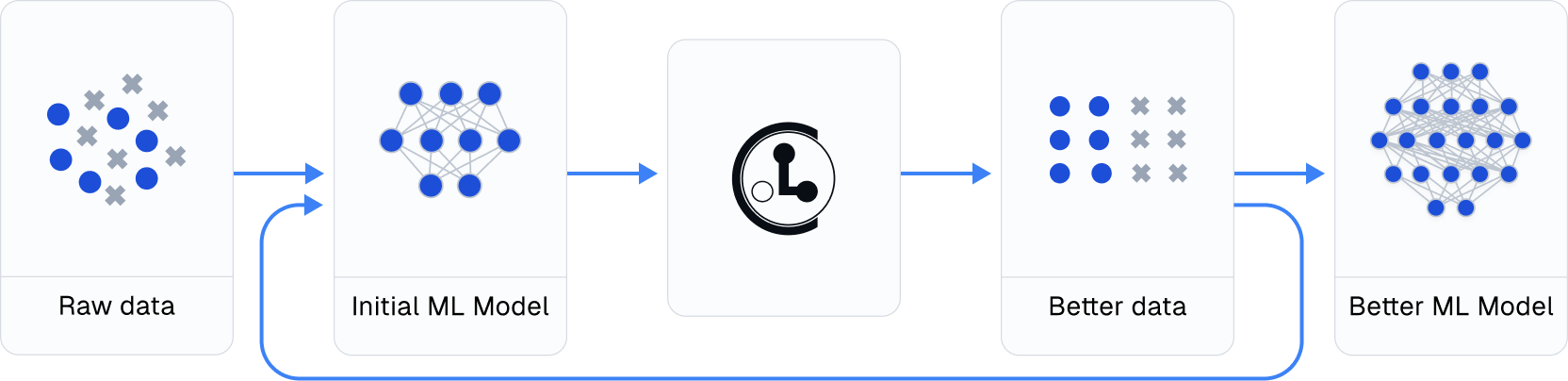
Cleanlab采用了一种称为"置信学习"(confident learning)的算法,这是一种先进的数据清理方法。它的工作流程大致如下:
- 首先在原始数据集上训练初始机器学习模型
- 利用该模型诊断数据问题并改进数据集
- 在改进后的数据集上重新训练模型
- 尝试各种建模技术以进一步提升性能
通过这种迭代的方式,Cleanlab能够持续提升数据质量和模型性能。
Cleanlab的广泛应用
Cleanlab可以与任何数据集和任何机器学习模型配合使用,包括PyTorch、TensorFlow、Keras、JAX、HuggingFace、OpenAI、XGBoost、scikit-learn等。它在各种机器学习任务中都能发挥作用,例如:
- 二分类和多分类
- 多标签分类(如图像/文档标记)
- 令牌分类(如文本中的实体识别)
- 回归(预测数据集中的数值列)
- 图像分割(像素级注释的图像)
- 目标检测(带有边界框注释的图像)
- 多标注者数据分类
- 多标注者主动学习
- 异常检测
这种广泛的适用性使得Cleanlab成为了一个真正通用的数据中心AI工具。
Cleanlab Studio:更易用的商业版本
除了开源版本,Cleanlab还提供了一个名为Cleanlab Studio的商业版本。Cleanlab Studio是一个数据管理平台,可以在任何{图像、文本、表格}数据集中查找和修复问题。它自动运行来自开源包的优化算法,结合AutoML和基础模型,并在智能数据校正界面中展示检测到的问题(以及AI建议的修复方案)。
Cleanlab Studio的主要优势包括:
- 工作速度提高100倍(1分钟即可分析原始数据,无需编码或ML工作)
- 生成更高质量的数据(通过内置AI自动检测和修正10倍以上的问题类型)
- 实现更多功能(自动标记数据、即时部署ML、审核LLM输入/输出、审核内容等)
- 实时监控传入数据并检测问题
这些功能使得Cleanlab Studio成为企业级用户的理想选择,特别是那些需要快速、高效地处理大量数据的团队。
Cleanlab的理论基础和性能保证
Cleanlab不仅仅是一个实用工具,它还有坚实的理论基础。其核心算法已在多篇同行评审的学术论文中发表,包括发表在人工智能研究杂志(JAIR)上的"置信学习"论文。这些研究工作为Cleanlab提供了理论保证,即使在模型不完美的情况下,也能准确估计标签噪声。
Cleanlab的主要优势包括:
- 理论支持 - 即使使用不完美的模型,也能保证准确估计标签噪声
- 高效 - 代码并行化和可扩展
- 易用 - 只需一行代码即可找到错误标记的数据、不良标注者、异常值,或训练抗噪声模型
- 通用性 - 适用于任何数据集(文本、图像、表格、音频等)和任何模型(PyTorch、OpenAI、XGBoost等)
这些特性使得Cleanlab成为了一个既实用又可靠的数据中心AI工具。
Cleanlab的实际应用案例
Cleanlab已在多个领域展现出其强大的能力。例如:
- 在图像分类任务中,Cleanlab成功识别并纠正了多个知名数据集中的标签错误,包括将一只猫错误标记为狗的情况。
- 在自然语言处理领域,Cleanlab帮助改进了文本分类和命名实体识别等任务的数据质量。
- 在金融领域,Cleanlab协助提高了交易分类的准确性,显著减少了人工标注的工作量。
这些案例证明了Cleanlab在实际应用中的价值和潜力。
加入Cleanlab社区
Cleanlab不仅仅是一个工具,它还拥有一个活跃的开源社区。开发者们可以通过多种方式参与到Cleanlab的发展中来:
- 加入Cleanlab的Slack社区,与其他1000多名成员一起学习、讨论和塑造Cleanlab的未来。
- 查看贡献指南、开发指南,以及有关有用贡献的想法,参与到Cleanlab的开发中来。
- 如果遇到问题,可以查看FAQ、GitHub Issues或在Slack上提问。
通过这种方式,Cleanlab正在不断发展和完善,以满足数据科学和机器学习社区的需求。
结语
在当今数据驱动的世界中,数据质量的重要性怎么强调都不为过。Cleanlab作为一个强大的开源工具,为提高数据质量、改进机器学习模型提供了宝贵的解决方案。无论是学术研究还是商业应用,Cleanlab都有潜力成为数据科学家和机器学习工程师的得力助手,推动人工智能领域的进步。
随着AI技术的不断发展,我们可以期待Cleanlab在未来会有更多创新和突破,为数据中心AI带来更多可能性。对于那些致力于提高数据质量、构建更可靠AI系统的个人和组织来说,Cleanlab无疑是一个值得关注和尝试的工具。









