
CoCa-pytorch: 开启图像-文本多模态AI的新纪元
在人工智能快速发展的今天,多模态学习已成为一个备受关注的研究方向。其中,图像-文本模型因其在理解和生成跨模态内容方面的巨大潜力而备受瞩目。在这个背景下,CoCa (Contrastive Captioners) 模型应运而生,为多模态AI领域带来了新的突破。本文将深入探讨CoCa-pytorch项目,这是一个基于PyTorch框架实现的CoCa模型,展现了其在图像理解和文本生成任务上的卓越表现。
CoCa模型:融合对比学习的创新架构
CoCa模型的核心创新在于它巧妙地将对比学习融入到传统的编码器/解码器(图像到文本)transformer架构中。这种设计使得模型能够同时学习图像和文本的表示,并在两种模态之间建立强有力的联系。通过这种方式,CoCa不仅能够生成高质量的图像描述,还能够在各种视觉-语言任务中展现出色的性能。
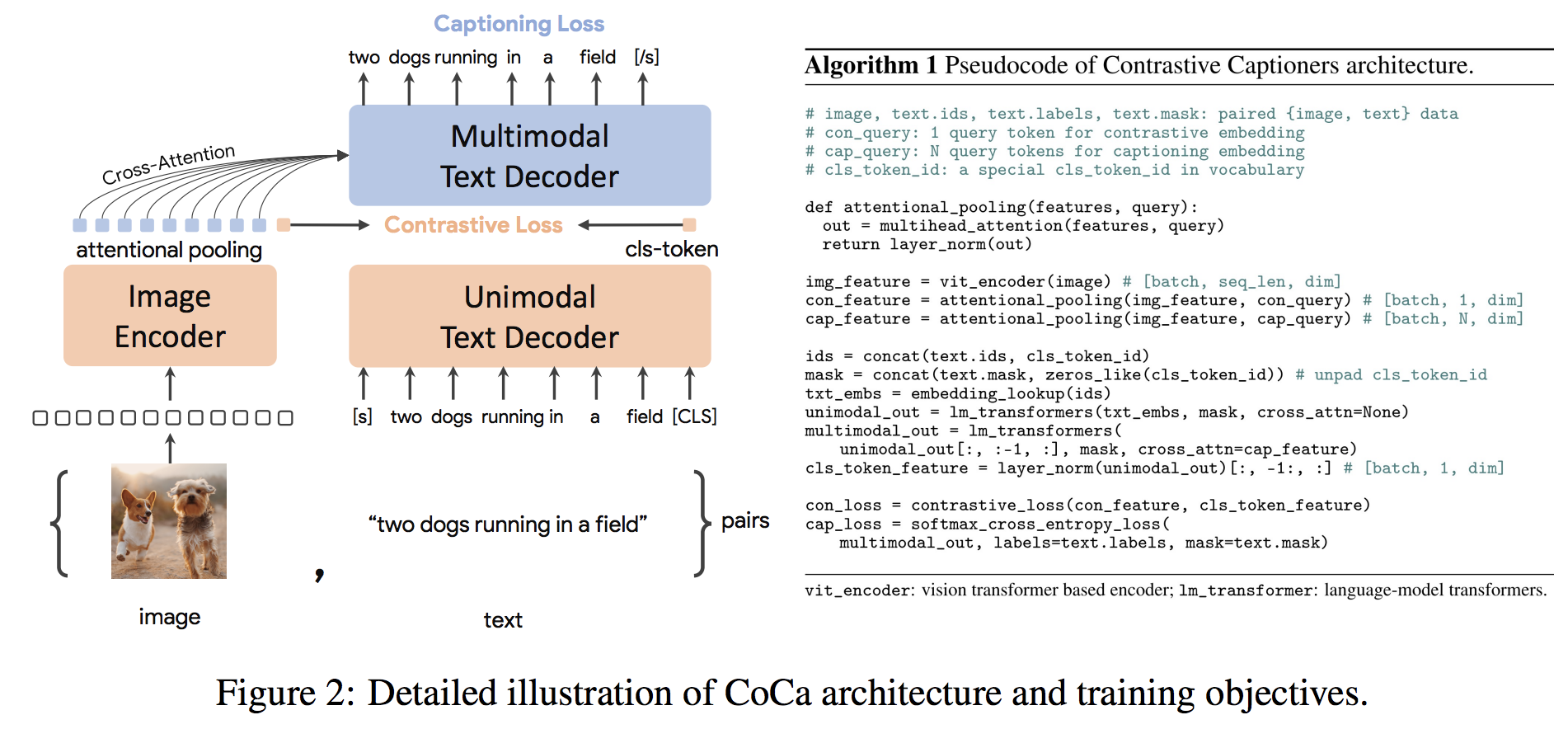
上图展示了CoCa模型的整体架构,清晰地呈现了其中的各个关键组件和数据流动过程。
CoCa-pytorch:强大而灵活的实现
CoCa-pytorch项目由GitHub用户lucidrains开发,是CoCa模型的一个高效实现。这个项目不仅忠实地复现了原始CoCa模型的设计,还引入了一些创新性的改进,使其更加适用于实际应用场景。
主要特点:
-
基于PyTorch框架: 利用PyTorch强大的动态计算图和丰富的生态系统,使得模型训练和部署更加灵活高效。
-
采用PaLM架构: 项目选择了PaLM (Pathways Language Model) 的transformer架构,用于单模态和多模态transformer以及交叉注意力模块,进一步提升了模型的性能。
-
灵活的配置选项: 提供了多种参数配置选项,允许用户根据具体需求调整模型结构和训练过程。
-
支持多种任务: 除了图像描述生成,CoCa-pytorch还支持图像-文本检索、视觉问答等多种下游任务。
安装与使用
CoCa-pytorch的安装非常简单,只需通过pip命令即可完成:
pip install coca-pytorch
在使用CoCa-pytorch之前,还需要安装图像编码器所需的vit-pytorch库:
pip install vit-pytorch>=0.40.2
以下是一个简单的使用示例,展示了如何初始化模型并进行训练:
import torch
from vit_pytorch.simple_vit_with_patch_dropout import SimpleViT
from vit_pytorch.extractor import Extractor
from coca_pytorch.coca_pytorch import CoCa
# 初始化视觉transformer
vit = SimpleViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
patch_dropout = 0.5
)
vit = Extractor(vit, return_embeddings_only = True, detach = False)
# 初始化CoCa模型
coca = CoCa(
dim = 512,
img_encoder = vit,
image_dim = 1024,
num_tokens = 20000,
unimodal_depth = 6,
multimodal_depth = 6,
dim_head = 64,
heads = 8,
caption_loss_weight = 1.,
contrastive_loss_weight = 1.,
).cuda()
# 模拟输入数据
text = torch.randint(0, 20000, (4, 512)).cuda()
images = torch.randn(4, 3, 256, 256).cuda()
# 训练过程
loss = coca(
text = text,
images = images,
return_loss = True
)
loss.backward()
CoCa-pytorch的应用前景
CoCa-pytorch的出现为多模态AI研究和应用开辟了新的可能性。以下是一些潜在的应用场景:
-
智能图像描述生成: 可用于自动为图像生成准确、丰富的描述文本,广泛应用于媒体内容管理、辅助视觉障碍人士等领域。
-
视觉-语言检索: 能够实现基于文本查找相关图像,或根据图像检索相关文本描述,对于大规模多媒体数据库的管理和检索具有重要意义。
-
视觉问答系统: 可以构建能够理解图像内容并回答相关问题的AI系统,在教育、客户服务等领域有广阔应用前景。
-
多模态内容创作: 为AI辅助内容创作提供新的可能,如根据文本描述生成相关的图像概念,或基于图像创作相关的文学作品。
-
跨模态知识表示学习: 通过学习图像和文本的统一表示,为知识图谱构建、多模态推理等任务提供基础。
结语
CoCa-pytorch项目为研究人员和开发者提供了一个强大而灵活的工具,用于探索和开发基于图像-文本多模态学习的创新应用。随着这一领域的不断发展,我们可以期待看到更多基于CoCa模型的令人兴奋的应用出现,进一步推动人工智能向着真正理解和生成多模态内容的目标迈进。
无论您是对多模态AI研究感兴趣的学者,还是希望在实际应用中利用先进AI技术的开发者,CoCa-pytorch都为您提供了一个极具价值的起点。我们鼓励更多的人参与到这个开源项目中来,共同推动多模态AI技术的发展,创造出更多改变世界的智能应用。









