CodeAct: 用可执行代码行动提升大语言模型智能体能力
 Ray
RayCodeAct:用可执行代码行动提升大语言模型智能体能力
在人工智能快速发展的今天,大语言模型(LLM)智能体展现出了令人瞩目的潜力,能够执行广泛的任务,如调用工具、控制机器人等。然而,传统的LLM智能体在行动空间上往往受到限制,难以应对复杂多变的现实世界挑战。近期,来自多所知名大学的研究人员提出了一种创新的方法——CodeAct,旨在通过可执行代码行动来提升LLM智能体的能力。本文将深入探讨CodeAct的核心理念、技术实现以及其在实际应用中的优势。
CodeAct的核心理念
CodeAct的核心思想是使用可执行的Python代码来整合LLM智能体的行动到一个统一的行动空间中。与传统方法不同,CodeAct不再局限于预定义的工具集或固定格式的输出,而是赋予智能体更大的灵活性和创造力。
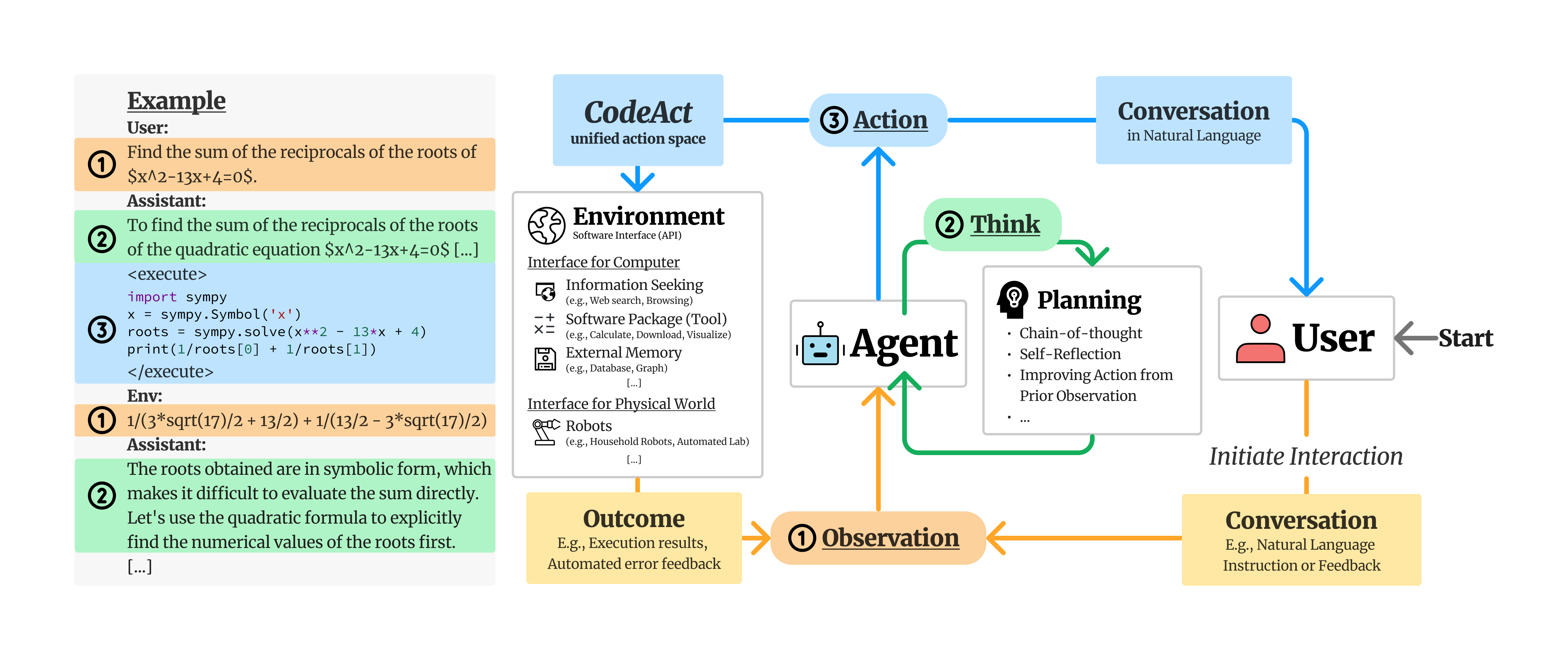
如上图所示,CodeAct智能体能够生成Python代码作为其行动,这些代码可以被实时执行,执行结果会作为新的观察反馈给智能体。这种方式使得智能体可以根据执行结果动态修改先前的行动或生成新的行动,实现了多轮交互的能力。
CodeAct的技术实现
CodeAct的实现依赖于以下几个关键组件:
-
LLM服务:使用vLLM或其他兼容OpenAI API的服务来部署大语言模型。
-
交互接口:可以选择使用Chat-UI配合MongoDB进行聊天界面和历史记录管理,或者使用简单的Python脚本进行交互。
-
代码执行引擎:基于JupyterKernelGateway实现的容器化代码执行服务,为每个聊天会话启动独立的Docker容器来执行代码。
研究团队还开发了CodeActAgent,这是一个基于CodeAct理念训练的模型。CodeActAgent有两个版本:
- CodeActAgent-Mistral-7b-v0.1:基于Mistral-7b-v0.1模型,具有32k上下文窗口。
- CodeActAgent-Llama-7b:基于Llama-2-7b模型,具有4k上下文窗口。
CodeAct的优势
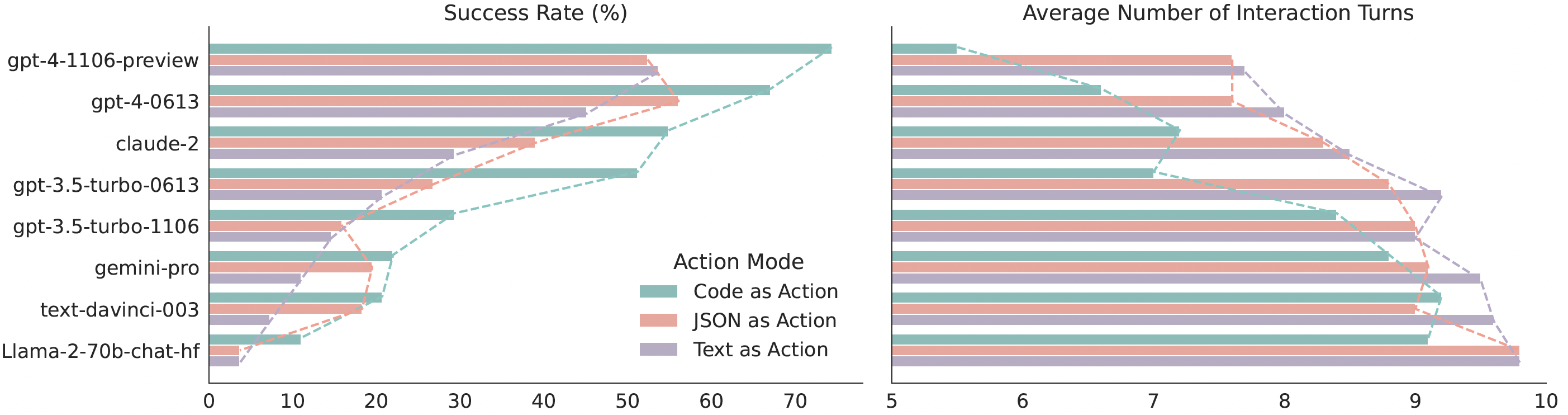
研究团队对17个LLM在API-Bank和新开发的M3ToolEval基准上进行了广泛分析,结果显示CodeAct相比传统的文本和JSON方法具有显著优势:
-
更高的成功率:在某些任务中,CodeAct的成功率比传统方法高出多达20%。
-
灵活性:CodeAct不受预定义工具的限制,能够动态组合和创建新的功能。
-
可解释性:生成的Python代码提供了清晰的行动轨迹,便于理解和调试。
-
自我调试能力:CodeActAgent能够自主识别和修正错误,提高了任务完成的稳定性。
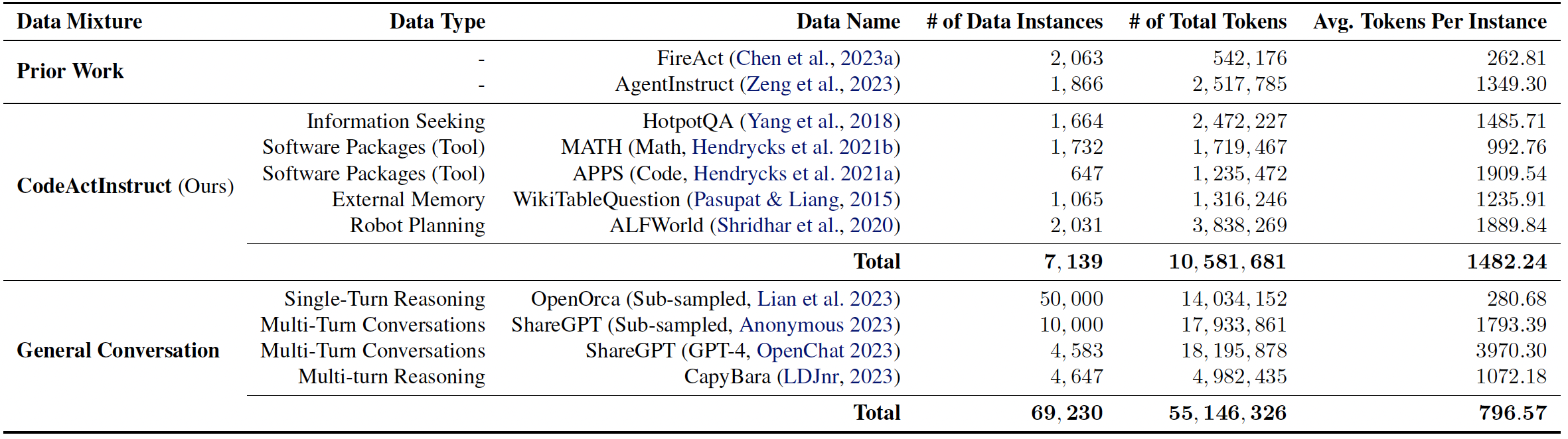
CodeActInstruct数据集
为了训练CodeActAgent,研究团队收集了CodeActInstruct数据集,包含7000多个使用CodeAct的多轮交互样本。这个数据集不仅用于模型训练,也为研究人员提供了宝贵的学习资源。
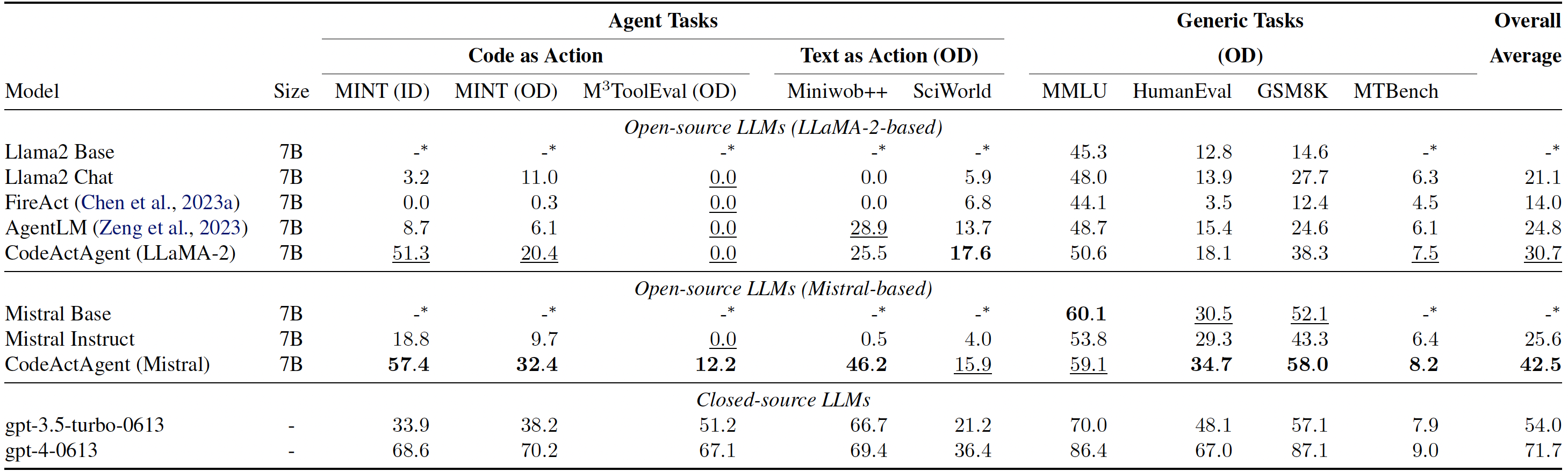
CodeActAgent的应用
CodeActAgent展现出了优秀的跨域任务处理能力,同时保持了在通用对话和知识问答方面的高水平表现。它的一些关键特性包括:
- 与Python解释器的深度集成
- 使用现有库执行复杂任务(如模型训练)的能力
- 自主调试能力
部署和使用CodeActAgent
研究团队提供了详细的部署指南,包括如何使用Docker或Kubernetes设置完整的CodeActAgent系统。用户可以选择通过简单的Python脚本或更高级的Chat-UI界面与CodeActAgent交互。
对于希望在本地笔记本电脑上运行CodeActAgent的用户,研究团队还提供了使用llama.cpp的轻量级解决方案。
结论与未来展望
CodeAct为LLM智能体的发展开辟了新的方向。通过将可执行代码作为行动空间,CodeAct大大提升了智能体的能力边界和灵活性。未来,我们可以期待看到更多基于CodeAct理念的应用,以及在更广泛的任务和领域中的实践。
CodeAct的开源性质也为整个AI社区提供了宝贵的资源。研究人员和开发者可以基于CodeAct的代码库进行二次开发,推动LLM智能体技术的进一步发展。
随着技术的不断进步,我们可以预见CodeAct将在智能助手、自动化工具链、教育辅助系统等多个领域发挥重要作用,为人工智能的实际应用带来新的可能性。
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发�的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号