
Cognita简介
Cognita是一个开源的RAG(检索增强生成)框架,由TrueFoundry开发,旨在帮助开发者构建模块化、可扩展的生产级应用程序。与Langchain和LlamaIndex等主要用于快速原型开发的框架不同,Cognita专注于提供一个组织良好的代码库结构,使RAG组件模块化、API驱动且易于扩展。
Cognita的主要优势
- 提供了一个中心化的可重用组件库,包括解析器、加载器、嵌入器和检索器。
- 通过UI界面,使非技术用户也能轻松上传文档并进行问答。
- 完全API驱动,便于与其他系统集成。
- 支持多种文档检索方法,如相似性搜索、查询分解、文档重排等。
- 支持使用最先进的开源嵌入和重排模型。
- 支持使用Ollama等工具进行本地LLM部署。
- 支持增量索引,减少计算负担并避免重复索引。
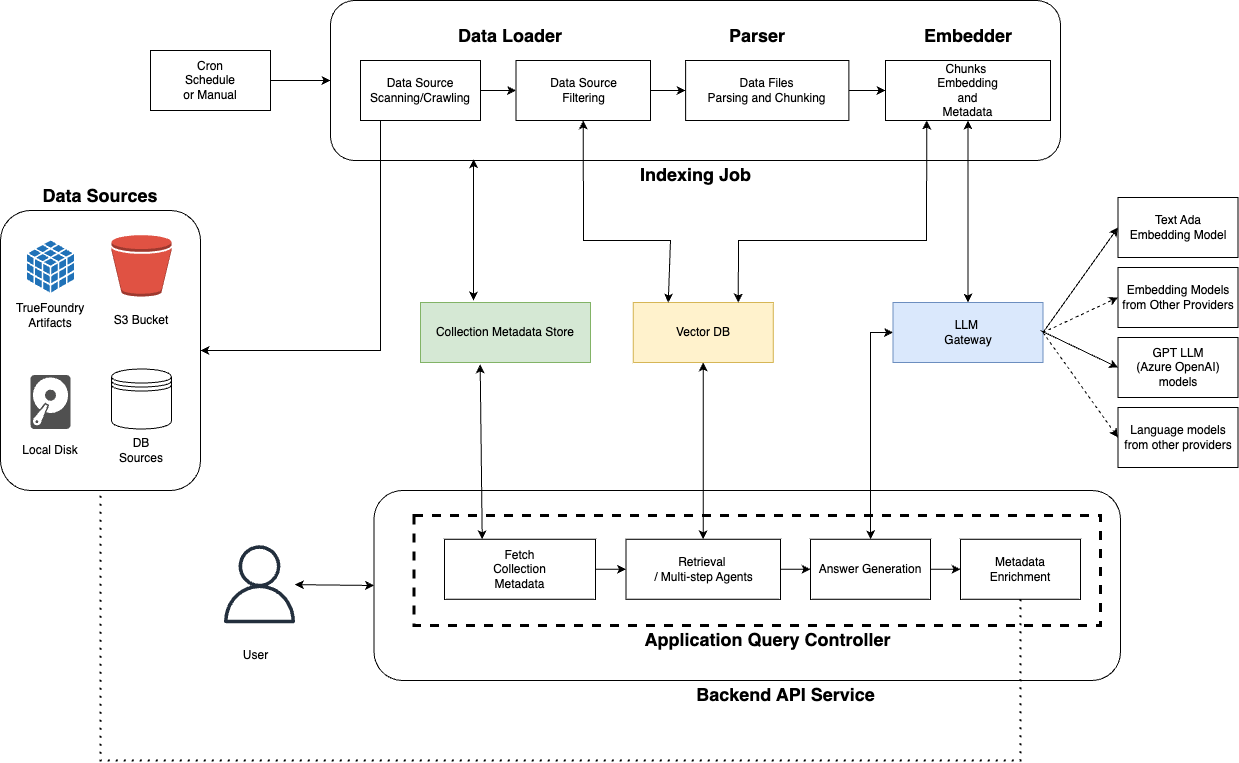
Cognita架构
Cognita的整体架构由以下几个主要组件构成:
- 数据源: 存储待索引文档的位置,如S3存储桶、数据库等。
- 元数据存储: 存储集合(一组文档)的元数据信息,包括集合名称、向量数据库信息、关联数据源等。
- LLM网关: 统一代理各种嵌入和LLM模型的请求。
- 向量数据库: 存储解析文件的嵌入和元数据,目前支持Qdrant和SingleStore。
- 索引作业: 负责协调索引流程的异步作业,可手动启动或定期运行。
- API服务器: 同步处理用户查询并生成答案,每个应用程序可以完全控制检索和回答过程。
数据索引流程
- 定期触发索引作业
- 扫描数据源中的所有数据点(文件)
- 比较向量数据库状态和数据源状态,确定新增、更新和删除的文件
- 下载新增和更新的文件
- 解析和分块处理文件
- 使用嵌入模型对分块进行嵌入
- 将嵌入的分块及元数据存入向量数据库
问答流程
- 用户发送查询请求
- 路由到相应的查询控制器
- 构建一个或多个检索器
- 构建问答链或代理
- 嵌入用户查询并获取相似分块
- 使用LLM模型生成答案
- 更新相关分块的元数据(如预签名URL等)
- 返回答案和相关文档分块
本地运行Cognita
Cognita提供了一种简单的方法来在本地运行整个系统,推荐使用Docker Compose(版本25+)。
-
安装Docker和docker-compose。
-
配置模型提供者:
- 复制
models_config.sample.yaml为models_config.yaml - 默认配置使用本地提供者,需要infinity和ollama服务器
- 如果有OpenAI API密钥,可以在
models_config.yaml中取消注释openai提供者,并在compose.env中更新OPENAI_API_KEY
- 复制
-
运行以下命令启动服务:
docker-compose --env-file compose.env up
这将启动以下服务:
- cognita-db: 用于存储集合和数据源元数据的Postgres实例
- qdrant-server: 本地向量数据库服务器
- cognita-backend: Cognita的FastAPI后端服务器
- cognita-frontend: Cognita的前端
-
访问服务:
- Qdrant服务器: http://localhost:6333
- 后端: http://localhost:8000
- 前端: http://localhost:5001
-
启动额外服务(如ollama和infinity-server):
docker-compose --env-file compose.env --profile ollama --profile infinity up
自定义Cognita
Cognita的设计理念是"一切皆可用,一切皆可定制"。它提供了简单的方法来切换解析器、加载器、模型和检索器。
自定义数据加载器
- 继承
backend/modules/dataloaders/loader.py中的BaseDataLoader类 - 在
backend/modules/dataloaders/__init__.py中注册加载器
自定义嵌入器
- 在
backend/modules/embedder/__init__.py中注册自定义嵌入 - 可以参考
backend/modules/embedder/mixbread_embedder.py添加自己的嵌入器
自定义解析器
- 继承
backend/modules/parsers/parser.py中的BaseParser类 - 在
backend/modules/parsers/__init__.py中注册解析器
添加自定义向量数据库
- 继承
backend/modules/vector_db/base.py中的BaseVectorDB - 在
backend/modules/vector_db/__init__.py中注册向量数据库
编写查询控制器
查询控制器负责实现RAG应用程序的查询接口。步骤如下:
- 在
backend/modules/query_controllers/中添加查询控制器类 - 使用
query_controller装饰器并传入自定义控制器名称 - 添加方法并使用HTTP装饰器(如
post,get,delete)使其成为API - 在
backend/modules/query_controllers/__init__.py中导入自定义控制器类
使用TrueFoundry部署
Cognita可以轻松部署到TrueFoundry平台上。主要步骤包括:
- 在TrueFoundry注册并创建组织
- 设置集群和存储集成
- 创建ML仓库和工作空间
- 部署RAG应用程序
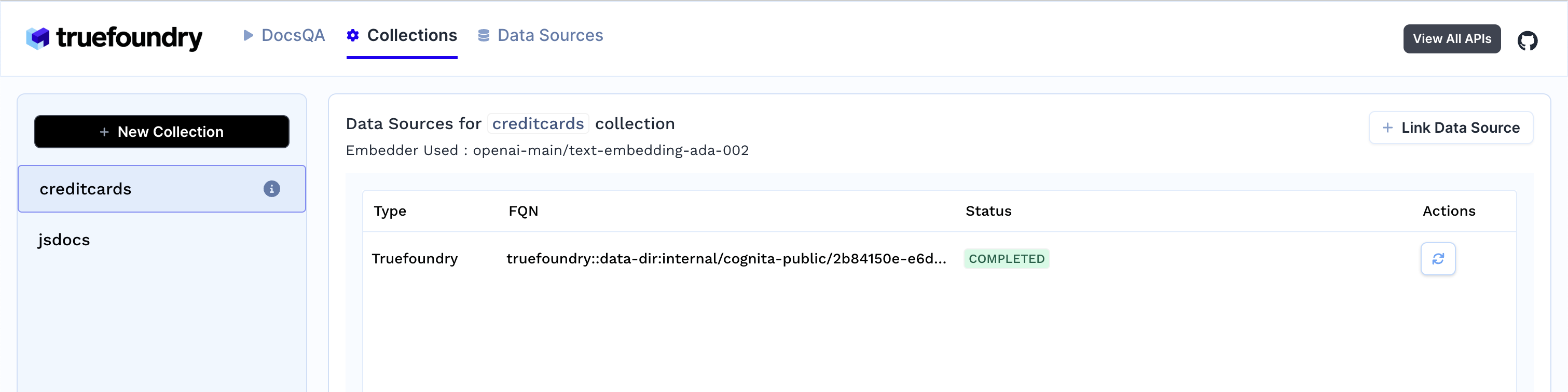
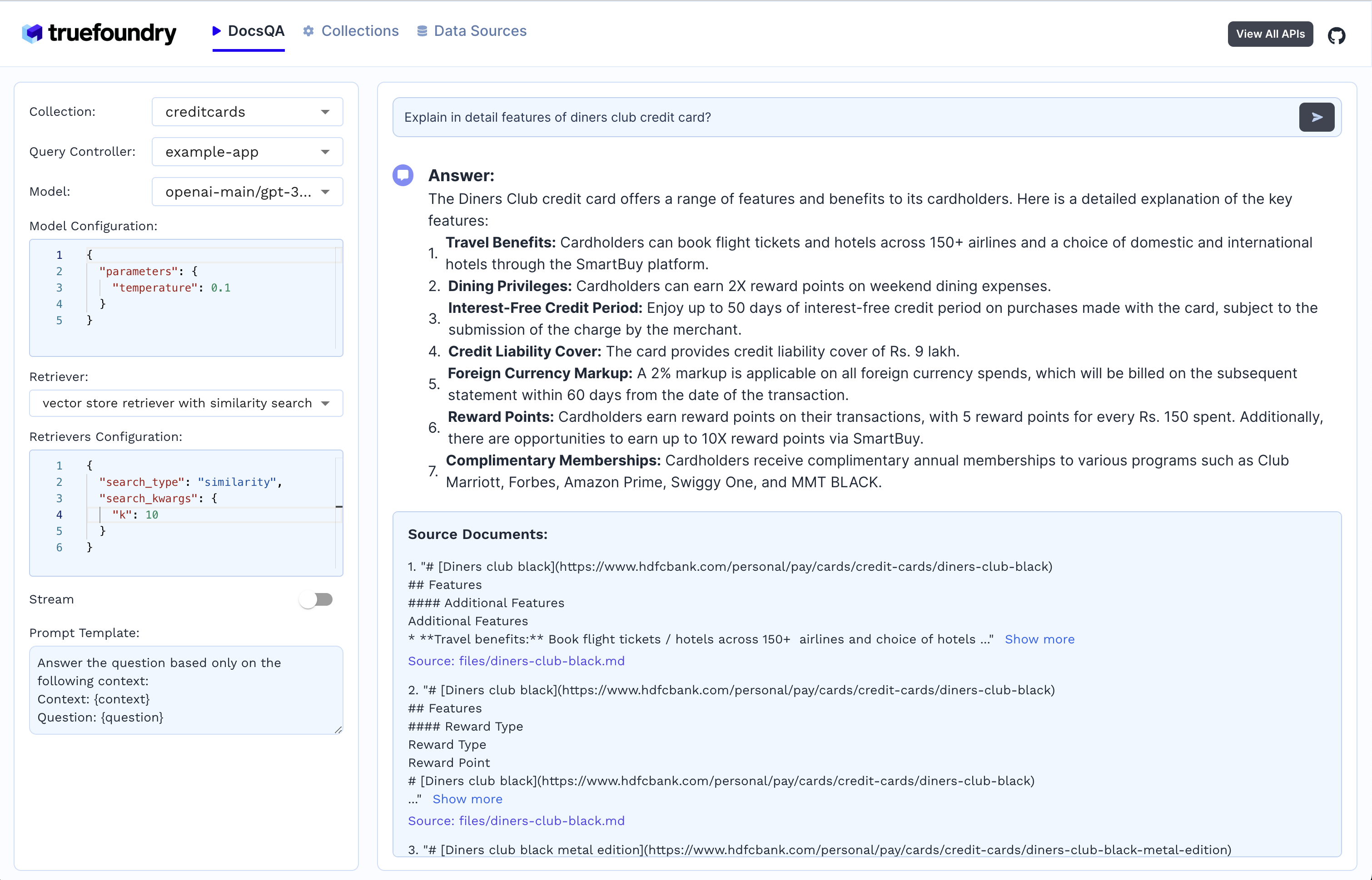
部署后,可以通过UI界面上传文档、创建数据源和集合,并进行问答交互。
开源贡献
Cognita欢迎社区贡献。您可以提出想法、反馈,或创建问题和错误报告。在贡献之前,请阅读贡献指南。
未来发展
Cognita的未来发展方向包括:
- 支持更多向量数据库(如Chroma、Weaviate等)
- 支持标量+二进制量化嵌入
- 支持RAG评估和可视化
- 支持带上下文的对话式聊天机器人
- 支持RAG优化的LLM(如stable-lm-3b、dragon-yi-6b等)
- 支持图数据库
总之,Cognita为构建生产级RAG应用提供了一个强大而灵活的框架。无论是本地开发还是云端部署,它都能满足开发者的需求,并且具有良好的可扩展性和可定制性。随着持续的开发和社区贡献,Cognita有望成为RAG应用开发的首选框架之一。










