🚀 continuous-eval简介
continuous-eval是一个为LLM应用提供数据驱动评估的开源工具包。它具有以下特点:
- 模块化评估:可以为管道中的每个模块使用定制的评估指标
- 综合的指标库:涵盖了RAG、代码生成、代理工具使用、分类等多种LLM应用场景
- 利用用户反馈:可以轻松构建接近人类评估的集成评估管道
- 合成数据集生成:可以生成大规模合成数据集来测试您的应用
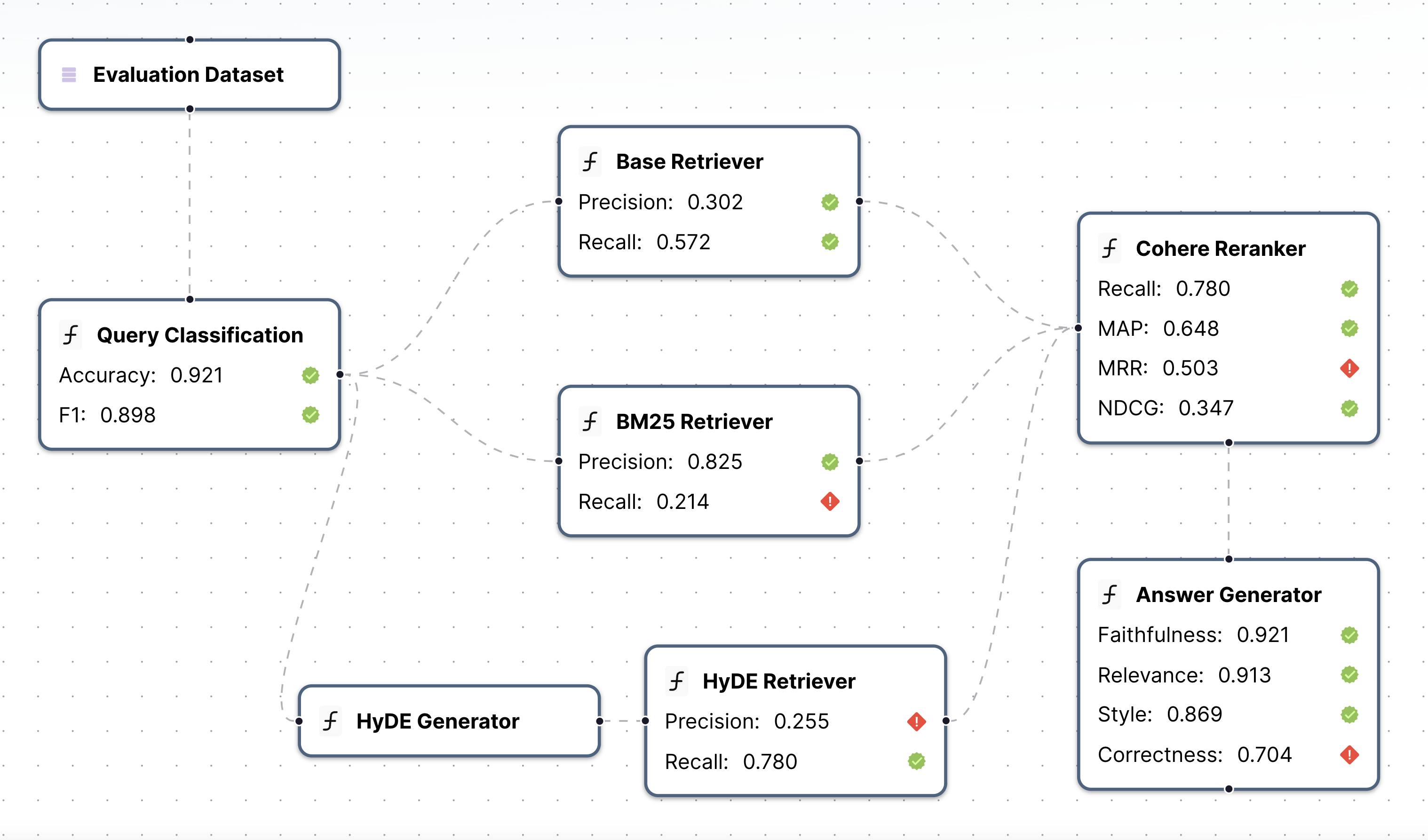
📚 官方文档
continuous-eval的官方文档提供了详细的使用说明和API参考:
文档包括:
- 快速入门指南
- 核心概念解释
- API参考
- 高级用法示例
强烈建议先阅读官方文档,以全面了解continuous-eval的功能和使用方法。
💻 代码示例
以下是一个使用continuous-eval的简单示例:
from continuous_eval.metrics.retrieval import PrecisionRecallF1
datum = {
"question": "What is the capital of France?",
"retrieved_context": [
"Paris is the capital of France and its largest city.",
"Lyon is a major city in France.",
],
"ground_truth_context": ["Paris is the capital of France."],
"answer": "Paris",
"ground_truths": ["Paris"],
}
metric = PrecisionRecallF1()
print(metric(**datum))
更多代码示例可以在项目的examples目录中找到。
📝 相关博客文章
以下博客文章深入探讨了continuous-eval的使用方法和最佳实践:
- RAG管道评估实用指南(第1部分:检索)
- RAG管道评估实用指南(第2部分:生成)
- 黄金数据集对LLM评估有多重要?
- 如何评估复杂的GenAI应用:细粒度方法
- 如何充分利用LLM生产数据:模拟用户反馈
这些文章提供了valuable insights,帮助您更好地理解和使用continuous-eval。
🤝 社区资源
🔧 安装指南
通过pip安装continuous-eval:
python3 -m pip install continuous-eval
或者从源代码安装:
git clone https://github.com/relari-ai/continuous-eval.git
cd continuous-eval
poetry install --all-extras
注意:要运行基于LLM的指标,您需要在.env文件中设置至少一个LLM API密钥。
🎓 结语
continuous-eval为LLM应用的评估提供了强大而灵活的工具。通过本文提供的资源,您可以快速上手并充分利用continuous-eval的功能。祝您在LLM应用开发和评估中取得成功!










