
CUTLASS简介
CUTLASS (CUDA Templates for Linear Algebra Subroutines) 是NVIDIA开发的一个开源CUDA C++模板库,用于实现高性能的矩阵乘法(GEMM)和相关计算。它采用了类似cuBLAS和cuDNN的分层分解和数据移动策略,将这些"移动部件"分解为可重用的模块化软件组件,通过C++模板类进行抽象。
CUTLASS的主要特点包括:
-
高性能:CUTLASS原语非常高效,在构建设备级GEMM内核时,其峰值性能可与cuBLAS相媲美。
-
灵活性:CUTLASS提供了不同级别的并行化层次结构原语,可以通过自定义平铺大小、数据类型和其他算法策略进行专门化和调优。
-
多精度支持:CUTLASS提供了广泛的混合精度计算支持,包括FP16、BF16、TF32、FP32、FP64等浮点类型,以及整数和二进制数据类型。
-
Tensor Core支持:CUTLASS演示了针对NVIDIA Volta、Turing、Ampere和Hopper架构实现的高吞吐量Tensor Core的同步矩阵乘法操作。
-
卷积支持:除了GEMM,CUTLASS还通过隐式GEMM算法实现了高性能卷积。
CUTLASS 3.5的新特性
CUTLASS 3.5.1是CUTLASS的最新更新版本,主要新增了以下功能:
-
100行代码的最小SM90 WGMMA + TMA GEMM示例。
-
TMA复制原子中L2 cache_hints的暴露。
-
CUTLASS库分析器和示例48中光栅顺序和tile swizzle范围的暴露。
-
用于Hopper指针数组批处理内核的基于TMA存储和支持EVT的epilogues。
-
用于CUTLASS 2.x Ampere内核的新GemmSparseUniversal API。
-
CUDA主机适配器扩展以支持TMA描述符构造驱动程序API。
-
在CUTLASS库和分析器中包含更多Hopper fprop、dgrad和wgrad卷积内核。
-
卷积内核中对残差加法(beta != 0)的支持。
-
CUTLASS 2.x的新卷积epilogue,以支持非打包的NHWC输出。
-
对CUTLASS核心目录中包含文件的重构,以减少循环依赖。
-
用于设置VSCode以更好地使用CUTLASS的指南和扩展的代码风格指南。
-
对MSVC作为主机编译器的更好支持。
-
许多性能优化、改进和错误修复,包括对FlashAttention-2的修复。
-
使用CUDA工具包版本12.4和12.5u1进行最佳代码生成。
这些更新进一步提高了CUTLASS的性能和易用性,使其能够更好地支持最新的GPU架构和应用需求。
CUTLASS的性能
CUTLASS原语在构建设备级GEMM内核时表现出与cuBLAS相当的峰值性能。以下是CUTLASS在NVIDIA H100 GPU上的性能数据:
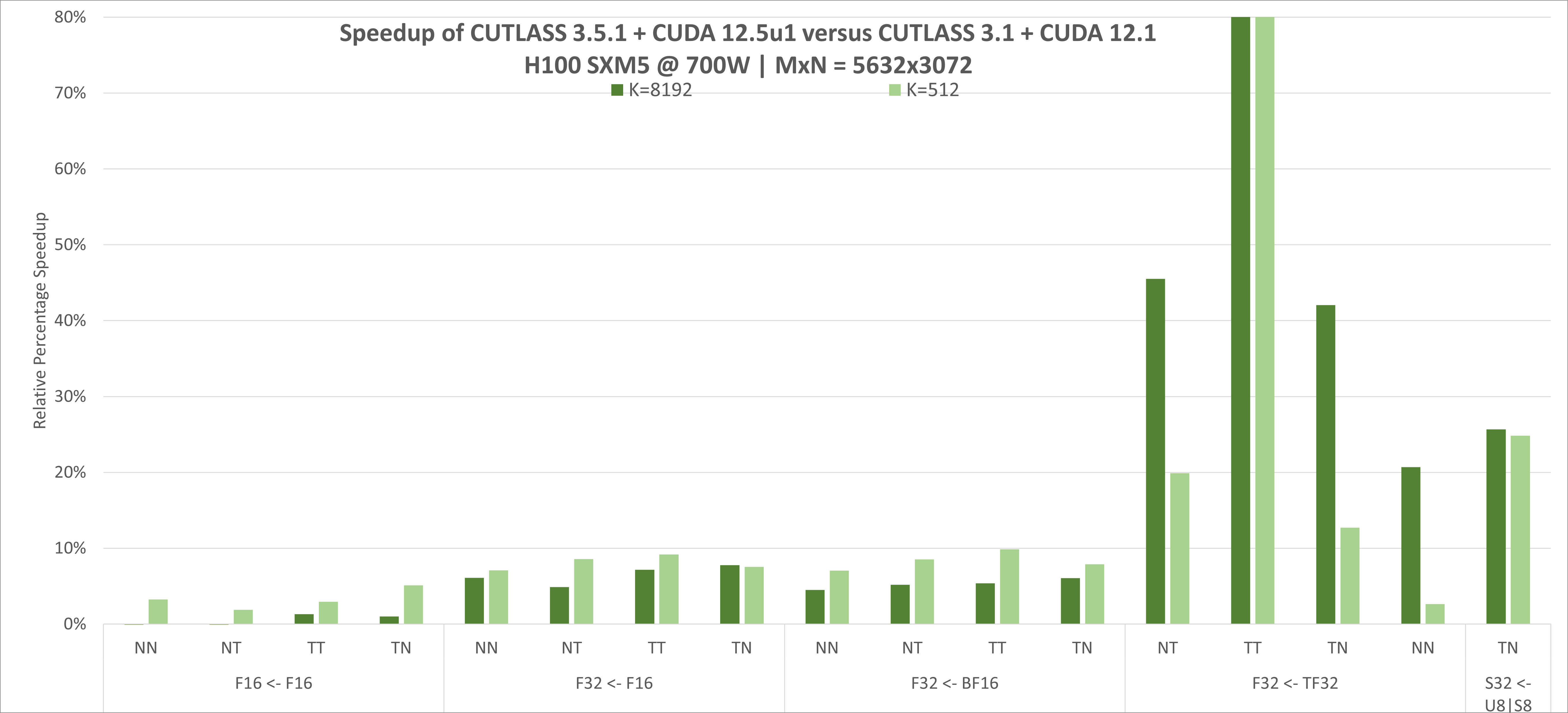
上图显示了自CUTLASS 3.1以来,CUTLASS在NVIDIA H100(NVIDIA Hopper架构)上的持续性能改进。CUTLASS 3.5.1使用CUDA 12.5u1工具包编译。Tensor Core操作使用CUDA的mma和wgmma指令实现。
在使用CUTLASS构建块构建设备级隐式gemm(Fprop、Dgrad和Wgrad)内核时,CUTLASS的性能也与cuDNN相当:
上图显示了在NVIDIA A100上运行Resnet-50层时,CUTLASS与cuDNN的性能比较。
CUTLASS的兼容性
CUTLASS要求C++17主机编译器,并在使用CUDA 12.4工具包构建时性能最佳。它还兼容CUDA 11.4及以上版本。
CUTLASS可以在以下NVIDIA GPU上成功运行,并且预计在基于Volta、Turing、Ampere、Ada和Hopper架构的NVIDIA GPU上都能高效运行:
- NVIDIA V100 Tensor Core GPU (CUDA计算能力7.0)
- NVIDIA TitanV (7.0)
- NVIDIA GeForce RTX 2080 TI, 2080, 2070 (7.5)
- NVIDIA T4 (7.5)
- NVIDIA A100 Tensor Core GPU (8.0)
- NVIDIA A10 (8.6)
- NVIDIA GeForce RTX 3090 (8.6)
- NVIDIA GeForce RTX 4090 (8.9)
- NVIDIA L40 (8.9)
- NVIDIA H100 Tensor Core GPU (9.0)
CUTLASS的文档和资源
CUTLASS提供了详细的文档来帮助用户理解和使用该库:
- 快速入门指南 - 构建和运行CUTLASS
- 功能列表 - 总结CUTLASS中可用的功能
- CUDA中的高效GEMM - 描述如何在CUDA中高效实现GEMM内核
- CUTLASS 3.x设计 - 描述CUTLASS 3.x的设计、其优势以及CuTe如何使我们能够编写更多可组合的组件
- GEMM API 3.x - 描述CUTLASS 3.x GEMM模型和C++模板概念
- 隐式GEMM卷积 - 描述CUTLASS中的2-D和3-D卷积
此外,NVIDIA还提供了一系列技术讲座和演示,深入探讨了CUTLASS的设计理念和使用方法:
- CUTLASS:CUDA中各级别和规模的密集线性代数软件原语
- 开发CUDA内核以将Tensor Cores推向NVIDIA A100的绝对极限
- 在CUTLASS中使用Tensor Cores加速卷积
- 通过增加CUTLASS中的Tensor Core利用率来加速反向数据梯度
- CUTLASS:Python API、增强功能和NVIDIA Hopper
这些资源为开发者提供了深入了解CUTLASS内部工作原理和最佳实践的机会。
构建和使用CUTLASS
CUTLASS是一个仅头文件的模板库,不需要单独构建就可以被其他项目使用。客户端应用程序应该将CUTLASS的include/目录包含在其包含路径中。
CUTLASS的单元测试、示例和实用程序可以使用CMake构建。最低CMake版本要求在快速入门指南中给出。确保CUDACXX环境变量指向系统上安装的CUDA工具包中的NVCC。
构建CUTLASS的基本步骤如下:
-
创建构建目录:
$ mkdir build && cd build -
运行CMake:
$ cmake .. -DCUTLASS_NVCC_ARCHS=80 # 为NVIDIA的Ampere架构编译 -
编译和运行CUTLASS单元测试:
$ make test_unit -j
CUTLASS还提供了一个性能分析工具,可以用来启动和测试各种GEMM内核。可以通过以下命令构建:
$ make cutlass_profiler -j16
结论
CUTLASS作为NVIDIA开发的开源CUDA线性代数库,为深度学习和科学计算等领域提供了强大的加速能力。它不仅提供了高性能的矩阵乘法和卷积实现,还通过灵活的模板设计允许用户根据特定需求进行定制和优化。随着版本的不断更新,CUTLASS持续改进其性能和功能,支持最新的GPU架构和计算需求。对于需要在NVIDIA GPU上进行高性能线性代数计算的开发者来说,CUTLASS是一个值得深入研究和使用的强大工具。











