
DALLE2-pytorch:开源复现OpenAI的DALL-E 2模型
DALL-E 2是OpenAI在2022年发布的最新文本到图像生成模型,相比第一代DALL-E有了显著的提升。然而,OpenAI并未开源DALL-E 2的代码和模型权重。为了推动AI技术的开放和民主化,一些研究者和开发者开始尝试复现DALL-E 2。其中,DALLE2-pytorch项目是一个备受关注的开源实现。
项目概述
DALLE2-pytorch是由知名AI研究者Phil Wang (lucidrains)发起的开源项目,旨在用PyTorch框架复现DALL-E 2的核心架构。该项目的GitHub仓库地址为:https://github.com/lucidrains/DALLE2-pytorch
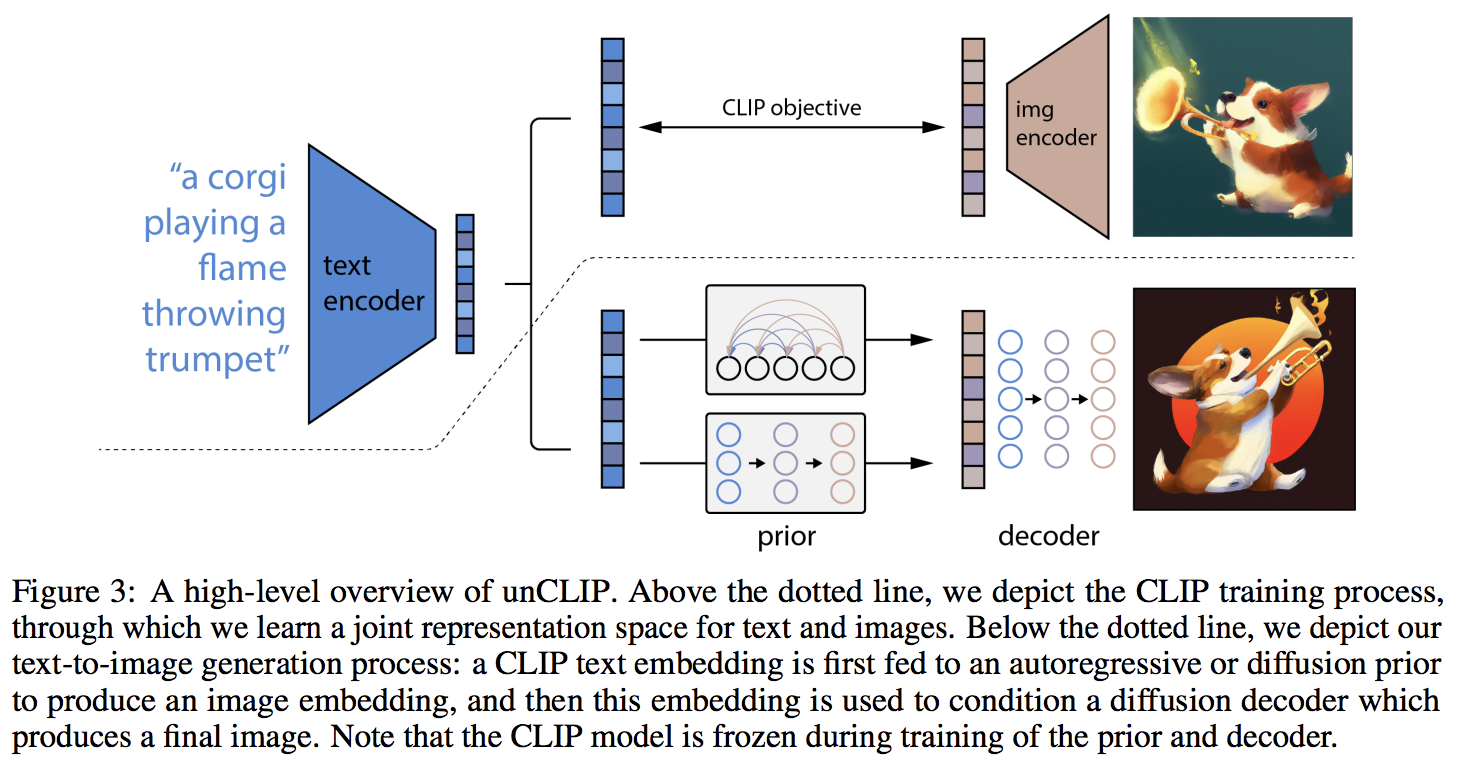
如上图所示,DALL-E 2的核心架构包含三个主要组件:
- CLIP:一个多模态神经网络,可以将文本和图像编码到同一潜在空间。
- Prior:一个扩散模型,用于从文本嵌入生成图像嵌入。
- Decoder:另一个扩散模型,用于从图像嵌入生成实际的图像。
DALLE2-pytorch项目实现了这三个核心组件,并提供了训练和推理的接口。
主要特性
DALLE2-pytorch具有以下主要特性:
- 完整实现了DALL-E 2的核心架构,包括CLIP、Prior和Decoder
- 支持分布式训练,可以在多GPU上进行扩展
- 提供了预处理CLIP嵌入的功能,方便大规模训练
- 集成了OpenAI的预训练CLIP模型,也支持使用开源的CLIP实现
- 实现了级联扩散模型,可以生成高分辨率图像
- 支持图像修复(inpainting)功能
- 实验性地结合了潜在扩散(latent diffusion)技术
使用方法
要使用DALLE2-pytorch,首先需要安装该库:
pip install dalle2-pytorch
然后,可以按照以下步骤使用:
- 训练或加载预训练的CLIP模型
- 训练Prior网络
- 训练Decoder网络
- 使用训练好的模型生成图像
以下是一个简单的示例代码:
import torch
from dalle2_pytorch import DALLE2, DiffusionPriorNetwork, DiffusionPrior, Unet, Decoder, CLIP
# 初始化CLIP
clip = CLIP(
dim_text = 512,
dim_image = 512,
dim_latent = 512,
num_text_tokens = 49408,
text_enc_depth = 6,
text_seq_len = 256,
text_heads = 8,
visual_enc_depth = 6,
visual_image_size = 256,
visual_patch_size = 32,
visual_heads = 8
).cuda()
# 初始化Prior网络
prior_network = DiffusionPriorNetwork(
dim = 512,
depth = 6,
dim_head = 64,
heads = 8
).cuda()
diffusion_prior = DiffusionPrior(
net = prior_network,
clip = clip,
timesteps = 100,
cond_drop_prob = 0.2
).cuda()
# 初始化Decoder
unet1 = Unet(
dim = 128,
image_embed_dim = 512,
cond_dim = 128,
channels = 3,
dim_mults=(1, 2, 4, 8)
).cuda()
decoder = Decoder(
unet = unet1,
image_sizes = (256,),
timesteps = 100,
image_cond_drop_prob = 0.1,
text_cond_drop_prob = 0.5
).cuda()
# 创建DALLE2实例
dalle2 = DALLE2(
prior = diffusion_prior,
decoder = decoder
)
# 生成图像
images = dalle2(
['a butterfly trying to escape a tornado'],
cond_scale = 2.
)
训练过程
训练DALL-E 2是一个分阶段的过程:
-
训练CLIP:这一步可以使用现有的CLIP实现或预训练模型。
-
训练Prior:使用CLIP生成的文本和图像嵌入来训练Prior网络。
loss = diffusion_prior(text, images)
loss.backward()
- 训练Decoder:使用真实图像和CLIP生成的图像嵌入来训练Decoder。
loss = decoder(images, unet_number = 1)
loss.backward()
DALLE2-pytorch提供了DecoderTrainer类来简化Decoder的训练过程,它可以自动管理多个Unet的优化器和指数移动平均。
实验性功能
潜在扩散
DALLE2-pytorch实验性地结合了潜在扩散(Latent Diffusion)技术。这种方法首先在低维潜在空间中进行扩散,然后再上采样到高分辨率图像,可以提高生成效率和质量。
vae1 = VQGanVAE(
dim = 32,
image_size = 256,
layers = 3,
layer_mults = (1, 2, 4)
)
decoder = Decoder(
clip = clip,
vae = (vae1,),
unet = (unet1, unet2, unet3),
image_sizes = (256, 512, 1024),
timesteps = 100
)
图像修复
DALLE2-pytorch还支持图像修复(inpainting)功能。用户可以提供一个待修复的图像和一个掩码,模型将生成符合上下文的修复结果。
inpainted_images = decoder.sample(
image_embed = mock_image_embed,
inpaint_image = inpaint_image,
inpaint_mask = inpaint_mask
)
结论
DALLE2-pytorch为研究者和开发者提供了一个强大的工具,可以复现和改进DALL-E 2模型。该项目不仅实现了原始论文中的核心架构,还加入了一些创新性的改进。随着社区的不断贡献,DALLE2-pytorch有望成为推动文本到图像生成技术发展的重要开源项目。
然而,需要注意的是,训练一个完整的DALL-E 2模型需要大量的计算资源和数据。对于个人研究者来说,可以考虑使用预训练的CLIP模型,并在小规模数据集上训练Prior和Decoder,以探索这一技术的潜力。
未来,DALLE2-pytorch项目可能会进一步改进模型架构、提高训练效率,并加入更多实用功能。随着大规模语言模型和视觉-语言模型的快速发展,我们可以期待看到更多令人兴奋的文本到图像生成技术的突破。












