
数据工程:21世纪的黄金职业
在当今数字化时代,数据已成为企业最宝贵的资产之一。随着大数据技术的飞速发展,对能够有效管理、处理和分析海量数据的专业人才的需求与日俱增。数据工程师正是在这样的背景下应运而生的新兴职业,被誉为21世纪的"黄金职业"之一。
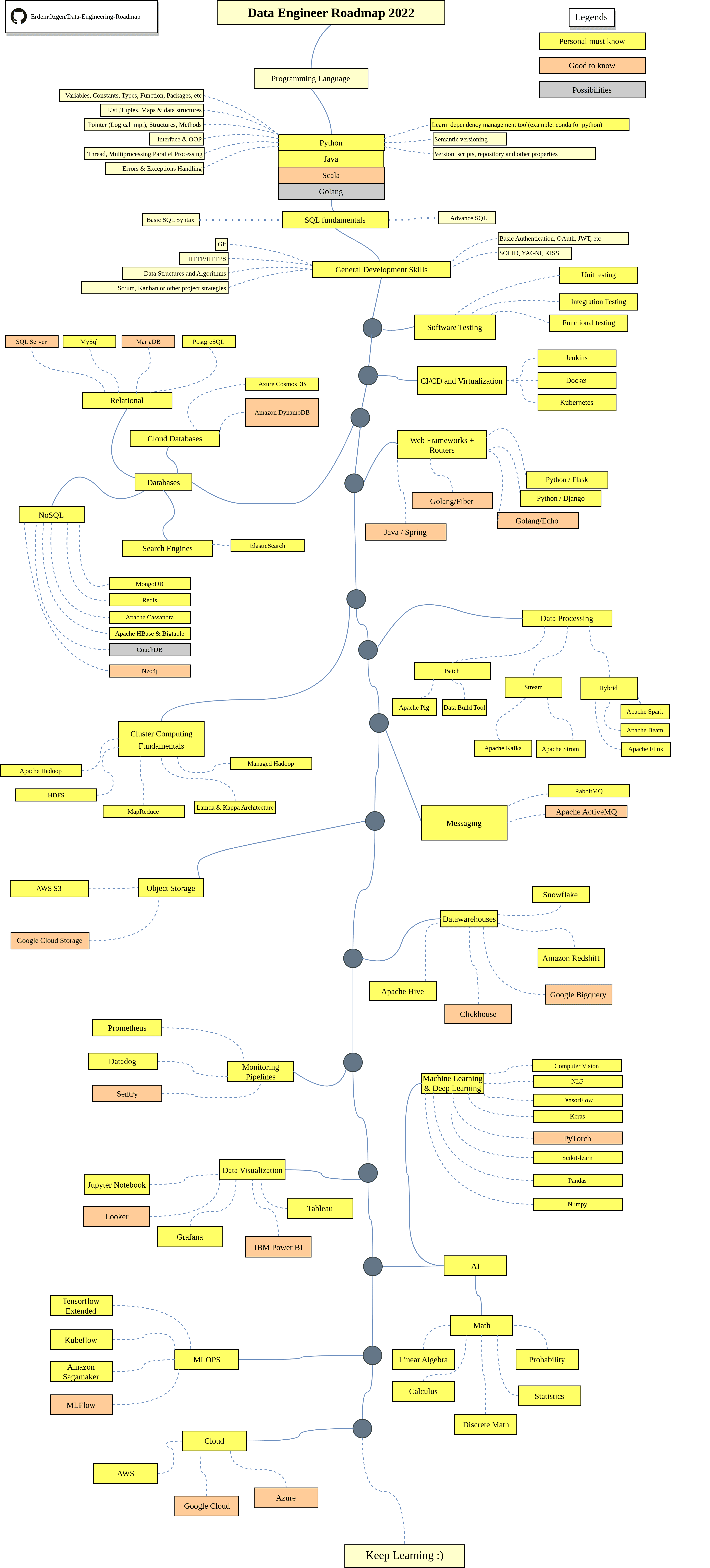
数据工程师是连接数据科学家和软件工程师的桥梁,他们负责构建和维护数据基础设施,确保数据的可用性、一致性和安全性。一个优秀的数据工程师需要掌握广泛的技能,从编程语言到数据库管理,从分布式系统到云计算平台,无不需要精通。
那么,对于有志于成为数据工程师的人来说,应该如何规划自己的学习路径呢?本文将为您详细解析2024年数据工程师的技能图谱,助您在这个充满机遇的领域中脱颖而出。
编程语言:数据工程的基石
作为数据工程师,扎实的编程功底是必不可少的。以下是几种在数据工程领域广泛使用的编程语言:
Python:数据处理的瑞士军刀
Python无疑是数据工程领域最受欢迎的编程语言之一。它简洁易学,拥有丰富的数据处理库(如Pandas、NumPy),以及强大的机器学习框架(如TensorFlow、PyTorch)。对于数据工程师来说,熟练掌握Python是基本要求。
推荐学习资源:
Java:企业级数据处理的首选
Java在企业级数据处理中占据重要地位,特别是在大数据生态系统(如Hadoop、Spark)中。它的强类型特性和优秀的性能使其成为构建稳定、可扩展的数据管道的理想选择。
推荐学习资源:
Scala:函数式编程的魅力
Scala结合了面向对象和函数式编程的特性,在大数据处理框架Apache Spark中广泛使用。它的简洁性和强大的表达能力使其成为处理复杂数据转换的有力工具。
推荐学习资源:
Go:高性能数据处理的新秀
Go语言以其简洁的语法和卓越的并发处理能力,在数据工程领域日益受到青睐。它特别适合构建高性能的数据服务和微服务架构。
推荐学习资源:
数据库:数据存储的核心
作为数据工程师,深入理解各类数据库系统是必不可少的。不同类型的数据库适用于不同的场景,掌握它们的特点和使用方法将使你能够为每个项目选择最合适的存储解决方案。
关系型数据库
关系型数据库是最传统和广泛使用的数据库类型,适用于结构化数据的存储和查询。
- MySQL: 开源、高性能、易用性强
- PostgreSQL: 功能强大,支持复杂查询和地理信息系统(GIS)
- MariaDB: MySQL的开源分支,兼容性好
- Amazon Aurora: AWS提供的高性能关系型数据库服务
非关系型数据库(NoSQL)
随着大数据时代的到来,NoSQL数据库因其灵活性和扩展性而备受青睐。
文档型数据库
- MongoDB: 灵活的schema,适合存储半结构化数据
- Elasticsearch: 全文搜索引擎,也可用作文档数据库
- Apache CouchDB: 支持多版本并发控制(MVCC)的文档数据库
- Azure CosmosDB: 微软提供的全球分布式多模型数据库服务
列式数据库
- Apache Cassandra: 高可用性和可扩展性,适合写入密集型应用
- Apache HBase: 建立在Hadoop之上的分布式列式数据库
- Google Bigtable: Google云平台提供的全管理NoSQL数据库服务
图数据库
- Neo4j: 最流行的图数据库,适合复杂关系数据的存储和查询
- Amazon Neptune: AWS提供的完全托管图数据库服务
键值存储
- Redis: 高性能的内存数据库,常用于缓存和消息队列
- Memcached: 分布式内存对象缓存系统
- Amazon DynamoDB: AWS提供的全托管NoSQL数据库服务
掌握这些数据库系统不仅要了解它们的基本操作,还要深入理解它们的内部原理、性能优化技巧以及在分布式环境下的部署和维护策略。
数据处理:从原始数据到洞察
数据处理是数据工程的核心环节,涉及数据的提取、转换和加载(ETL),以及更复杂的数据分析和机器学习任务。
批处理
- Apache Pig: 构建在Hadoop之上的高级数据流语言和执行框架
- Data Build Tool (dbt): 用于转换数据仓库中数据的现代化ETL工具
流处理
- Apache Kafka: 高吞吐量的分布式流平台
- Apache Storm: 实时计算系统
混合处理
- Apache Spark: 统一的分析引擎,支持批处理和流处理
- Apache Beam: 统一的编程模型,可在多个执行引擎上运行
- Apache Flink: 面向分布式流处理和批处理的开源平台
熟练掌握这些工具,不仅要了解它们的API和使用方法,还要深入理解它们的设计理念和内部原理。这将使你能够根据不同的数据处理需求选择最适合的工具,并能够设计出高效、可靠的数据处理管道。
大数据生态系统:应对海量数据的挑战
在大数据时代,传统的数据处理工具已经无法满足海量数据的处理需求。因此,掌握大数据生态系统中的核心技术变得尤为重要。
Apache Hadoop
Hadoop是大数据处理的基石,它包括以下核心组件:
- HDFS (Hadoop Distributed File System): 分布式文件系统,用于存储海量数据
- MapReduce: 分布式计算框架,用于并行处理大规模数据集
- YARN (Yet Another Resource Negotiator): 集群资源管理系统
Apache Hive
Hive是建立在Hadoop之上的数据仓库工具,它提供了类SQL查询语言HiveQL,使得数据分析人员可以方便地进行复杂的数据查询和分析。
Apache HBase
HBase是一个分布式、面向列的数据库,建立在HDFS之上,适合存储非结构化和半结构化的海量数据。
Apache ZooKeeper
ZooKeeper是一个分布式协调服务,用于管理大型分布式系统。它在Hadoop生态系统中扮演着重要角色,用于配置管理、命名服务等。
云平台上的大数据服务
各大云服务提供商也提供了强大的大数据处理服务:
- Amazon EMR (Elastic MapReduce): AWS上的托管Hadoop框架
- Google Cloud Dataproc: Google Cloud Platform上的全托管Apache Spark和Apache Hadoop服务
- Azure HDInsight: Microsoft Azure上的云中Hadoop和Spark服务
作为数据工程师,你需要深入理解这些技术的工作原理,掌握它们的配置、调优和故障排查技能。同时,还要了解如何在不同的场景下选择合适的技术组合,以构建高效、可扩展的大数据处理系统。
数据仓库和数据湖:数据存储的新范式
随着数据量的爆炸性增长和数据类型的多样化,传统的数据仓库已经无法满足所有的数据存储和分析需求。数据湖应运而生,为企业提供了更灵活、更经济的大规模数据存储解决方案。
数据仓库
数据仓库是面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
- Snowflake: 云原生的数据仓库,支持多云部署
- Amazon Redshift: AWS提供的完全托管的PB级数据仓库服务
- Google BigQuery: Google Cloud Platform上的无服务器、高度可扩展的数据仓库
- Azure Synapse Analytics: Microsoft Azure上的限制性分析服务
数据湖
数据湖是一个集中式存储库,可以存储所有结构化和非结构化数据,不需要预先定义模式。
- Amazon S3: AWS的对象存储服务,常用作数据湖的存储层
- Azure Data Lake Storage: Microsoft Azure提供的可扩展、安全的数据湖解决方案
- Google Cloud Storage: Google Cloud Platform的统一对象存储
数据湖仓
数据湖仓是数据湖和数据仓库的融合,结合了两者的优点。
- Databricks Delta Lake: 开源的存储层,为数据湖带来ACID事务
- Hudi (Hadoop Upserts Deletes and Incrementals): Apache的数据湖平台,支持增量处理
作为数据工程师,你需要深入理解这些存储解决方案的优缺点,并能够根据具体的业务需求和数据特征选择合适的方案。同时,还要掌握数据建模、数据质量控制、元数据管理等相关技能,以确保数据的可用性、一致性和可追溯性。
数据可视化:将数据转化为洞察
数据可视化是数据分析的重要组成部分,它能够将复杂的数据集转化为直观、易懂的图表和仪表盘,帮助决策者快速理解数据并做出决策。作为数据工程师,虽然你可能不直接负责创建最终的可视化产品,但理解和支持数据可视化的需求是非常重要的。
常用的数据可视化工具
-
Tableau: 强大的商业智能和数据可视化工具,支持多种数据源连接和丰富的图表类型。
-
Power BI: 微软推出的商业分析工具,与Office 365和Azure生态系统集成良好。
-
Looker: Google旗下的商业智能平台,提供强大的数据建模和可视化功能。
-
Grafana: 开源的监控和可视化平台,特别适合于时序数据的可视化。
-
Jupyter Notebook: 交互式计算环境,广泛用于数据分析和可视化,支持多种编程语言。
数据工程师在可视化中的角色
作为数据工程师,你的主要职责是确保数据可视化所需的数据是高质量、易获取的。这包括:
-
数据准备: 清洗、转换和聚合数据,使其适合于可视化需求。
-
性能优化: 优化查询和数据模型,确保可视化工具能够快速获取所需数据。
-
数据接口开发: 开发API或其他接口,使可视化工具能够方便地访问数据。
-
数据安全: 实施适当的访问控制和数据脱敏措施,确保数据的安全性和合规性。
-
元数据管理: 维护数据字典和数据目录,帮助分析师和可视化专家理解数据的含义和关系。
通过掌握这些技能,你将能够与数据分析师和可视化专家紧密合作,共同创造出有价值的数据产品。
机器学习和人工智能:数据工程的前沿
虽然机器学习和人工智能通常被认为是数据科学家的领域,但作为数据工程师,了解这些技术并能够支持相关工作流程变得越来越重要。
机器学习基础
- 监督学习: 包括分类和回归问题
- 非监督学习: 如聚类和降维
- 强化学习: 适用于决策问题




















