
解析器简介
解析器(Parser)是自然语言处理(NLP)中的一个重要组件,其主要任务是将自然语言文本转换为结构化的语法表示,通常是抽象语法树(Abstract Syntax Tree, AST)。解析器的工作对于后续的许多NLP任务至关重要,如机器翻译、问答系统、情感分析等。
在计算机科学中,解析器通常是编译器的一部分。它接收输入的源程序指令、交互式在线命令、标记标签或其他定义的接口。解析器将这些输入分解成更小的部分,如名词(对象)、动词(方法)及其属性或选项。这些部分随后由其他程序组件进行管理。解析器还可能会检查以确保提供了所有必要的输入。
解析器的工作原理
解析的过程通常包括以下几个阶段:
-
词法分析(Lexical Analysis): 词法分析器(也称为扫描器)接收预处理器的代码,并将其分解成更小的部分。它将输入代码分组为称为词素(lexemes)的字符序列,每个词素对应一个编译器理解的语法单位(token)。词法分析器还会删除输入中的空白字符、注释和错误。
-
句法分析(Syntactic Analysis): 句法分析阶段检查输入的句法结构,使用称为解析树或推导树的数据结构。语法分析器使用标记来构造解析树,该树结合了编程语言的预定义语法和输入字符串的标记。如果语法不正确,句法分析器会报告语法错误。
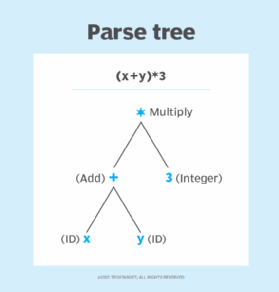
-
语义分析(Semantic Analysis): 语义分析验证解析树是否与符号表语义一致。这个过程也称为上下文敏感分析。它包括数据类型检查、标签检查和流控制检查。
主要类型的解析器
根据解析策略的不同,解析器可以分为以下几种主要类型:
-
自顶向下解析器(Top-down Parsers): 从语法的顶层规则开始,逐步向下推导出句子。常见的自顶向下解析器包括递归下降解析器(Recursive Descent Parser)和LL解析器。
-
自底向上解析器(Bottom-up Parsers): 从句子开始,逐步归约到语法的起始符号。常见的自底向上解析器包括LR解析器和移进-归约解析器(Shift-Reduce Parser)。
-
左递归解析器(LL Parsers): 从左到右读入输入,使用最左推导。
-
右递归解析器(LR Parsers): 从左到右读入输入,使用最右推导。
-
Earley解析器: 可以解析所有上下文无关文法,而不像LL和LR解析器那样受限。
解析器在NLP中的应用
在自然语言处理领域,解析器广泛应用于多种任务中:
-
依存句法分析(Dependency Parsing): 依存句法分析旨在确定句子中词语之间的依存关系。目前最先进的依存句法分析模型包括双仿射(Biaffine)模型和基于条件随机场(CRF)的模型。
-
成分句法分析(Constituency Parsing): 成分句法分析的目标是构建句子的层次结构,通常表示为树形结构。现代的成分句法分析模型大多基于神经网络,如CRF模型和AttachJuxtapose模型。
-
语义依存分析(Semantic Dependency Parsing): 语义依存分析关注词语之间的语义关系,而不仅仅是语法关系。双仿射模型和基于变分推断(VI)的模型在这一任务上表现出色。
解析器的性能评估
解析器的性能通常通过以下指标进行评估:
- 依存句法分析:使用无标记依存准确率(UAS)和标记依存准确率(LAS)
- 成分句法分析:使用精确率(P)、召回率(R)和F1分数
- 语义依存分析:同样使用精确率、召回率和F1分数
此外,解析速度(通常以句子/秒为单位)也是一个重要的评估指标。
解析器的未来发展
随着深度学习技术的进步,基于神经网络的解析器已经在多个任务上达到了state-of-the-art的性能。未来,解析器的发展趋势可能包括:
- 多语言和跨语言解析:开发能够同时处理多种语言或在不同语言间迁移的解析模型。
- 结合预训练语言模型:进一步探索如何有效地将BERT、RoBERTa等预训练模型与解析任务结合。
- 端到端解析:开发能够直接从原始文本输入生成解析结果的端到端模型,减少中间步骤。
- 解析器的可解释性:提高解析模型的可解释性,使我们能够更好地理解模型的决策过程。
- 解析效率的提升:在保持高精度的同时,进一步提高解析速度,以满足实时处理的需求。
结语
解析器作为自然语言处理的基础组件,在理解和处理人类语言方面扮演着至关重要的角色。随着技术的不断进步,我们可以期待看到更加强大、高效和多功能的解析器出现,为更广泛的NLP应用提供支持。研究人员和工程师们正在不断探索新的方法来改进解析器,使其能够更好地捕捉语言的复杂性和多样性。未来,解析器很可能会继续推动自然语言处理领域的发展,为人工智能和人机交互带来新的突破。









