
DeepSeek-LLM:开源大规模语言模型的新巅峰
在人工智能领域,大规模语言模型一直是研究的热点。近期,DeepSeek AI团队推出的DeepSeek-LLM项目引起了广泛关注。这个项目不仅在技术上取得了突破,还秉持开源精神,为整个AI社区带来了宝贵的资源。让我们一起来深入了解这个令人兴奋的项目。
模型概览:强大而多元的语言能力
DeepSeek-LLM是一个拥有670亿参数的大规模语言模型,它通过对2万亿英文和中文词元的训练,获得了强大而多元的语言能力。该项目发布了7B和67B两个规模的基础模型(Base)和对话模型(Chat),以满足不同的研究和应用需求。
值得一提的是,DeepSeek-LLM 67B Base模型在推理、编码、数学和中文理解等多个领域的表现都优于Llama2 70B Base。而DeepSeek-LLM 67B Chat模型在编码(HumanEval Pass@1: 73.78)和数学(GSM8K 0-shot: 84.1, Math 0-shot: 32.6)方面表现尤为出色。
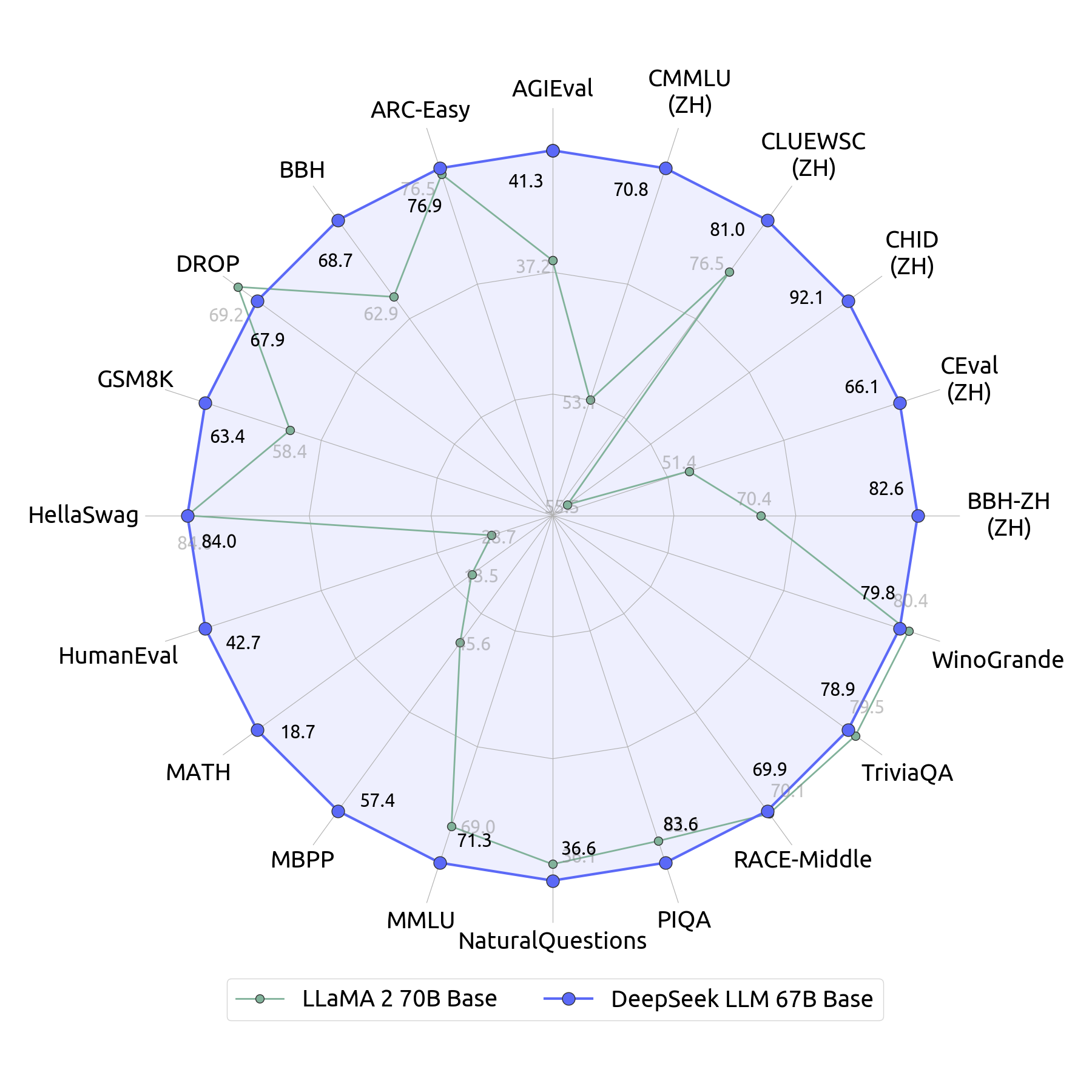
开源精神:推动AI研究的共同进步
DeepSeek AI团队秉持开源精神,不仅公开了模型,还提供了详细的训练过程和中间检查点。这种做法极大地促进了AI研究的透明度和可复现性,为整个社区的发展做出了重要贡献。
模型可以通过Hugging Face平台进行下载和使用:
- DeepSeek LLM 7B Base: 🤗 HuggingFace
- DeepSeek LLM 7B Chat: 🤗 HuggingFace
- DeepSeek LLM 67B Base: 🤗 HuggingFace
- DeepSeek LLM 67B Chat: 🤗 HuggingFace
卓越性能:多项评测中的佼佼者
DeepSeek-LLM在多个标准化测试中展现出了卓越的性能。特别值得一提的是,在匈牙利国家高中考试这个全新的评测基准上,DeepSeek-LLM 67B Chat模型获得了65分的高分,展现了其强大的数学能力和泛化能力。
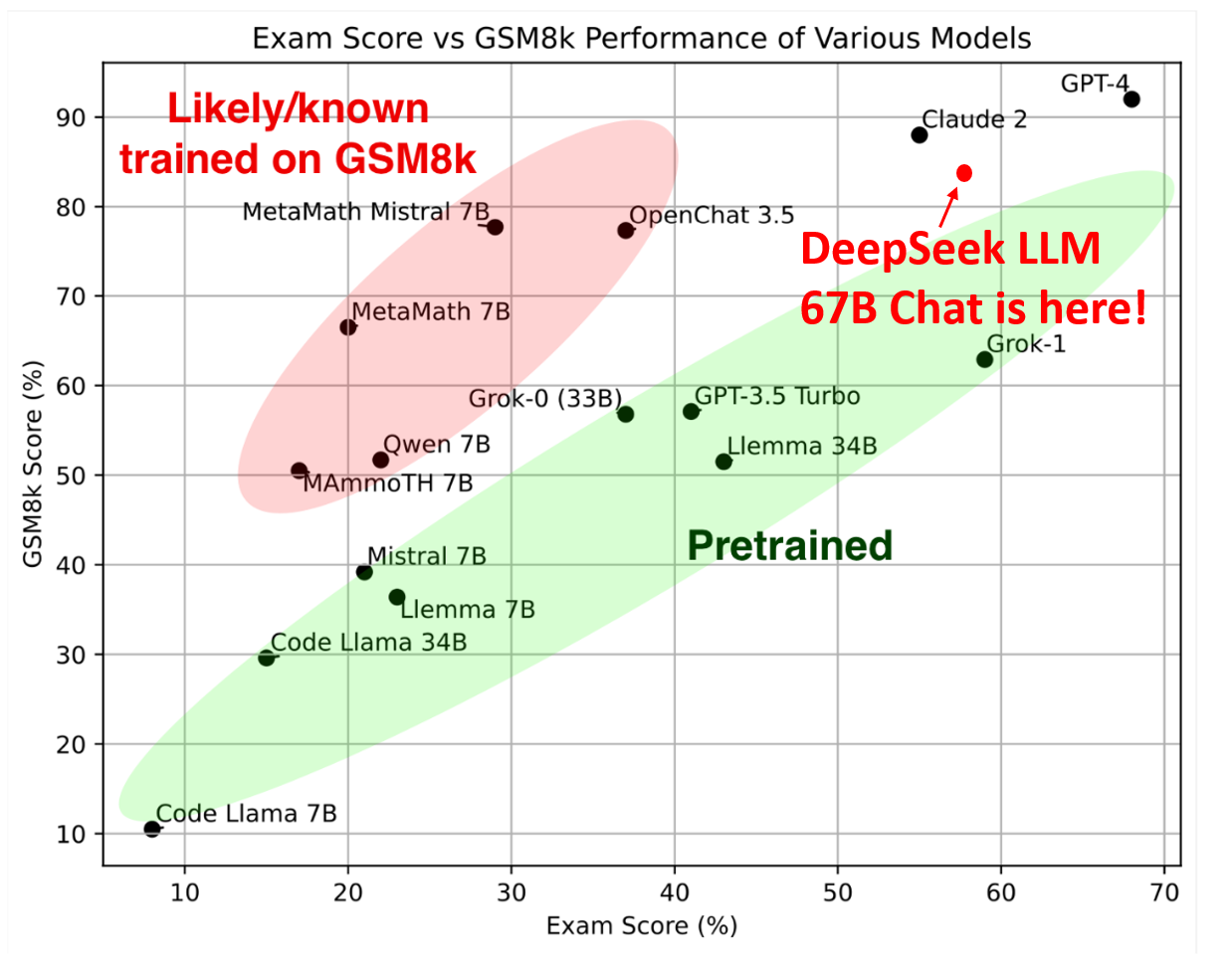
此外,在指令遵循评估(Instruction Following Evaluation)和LeetCode周赛等测试中,DeepSeek-LLM也表现出色,证明了其在理解和执行复杂指令方面的能力。
技术细节:精心设计的训练过程
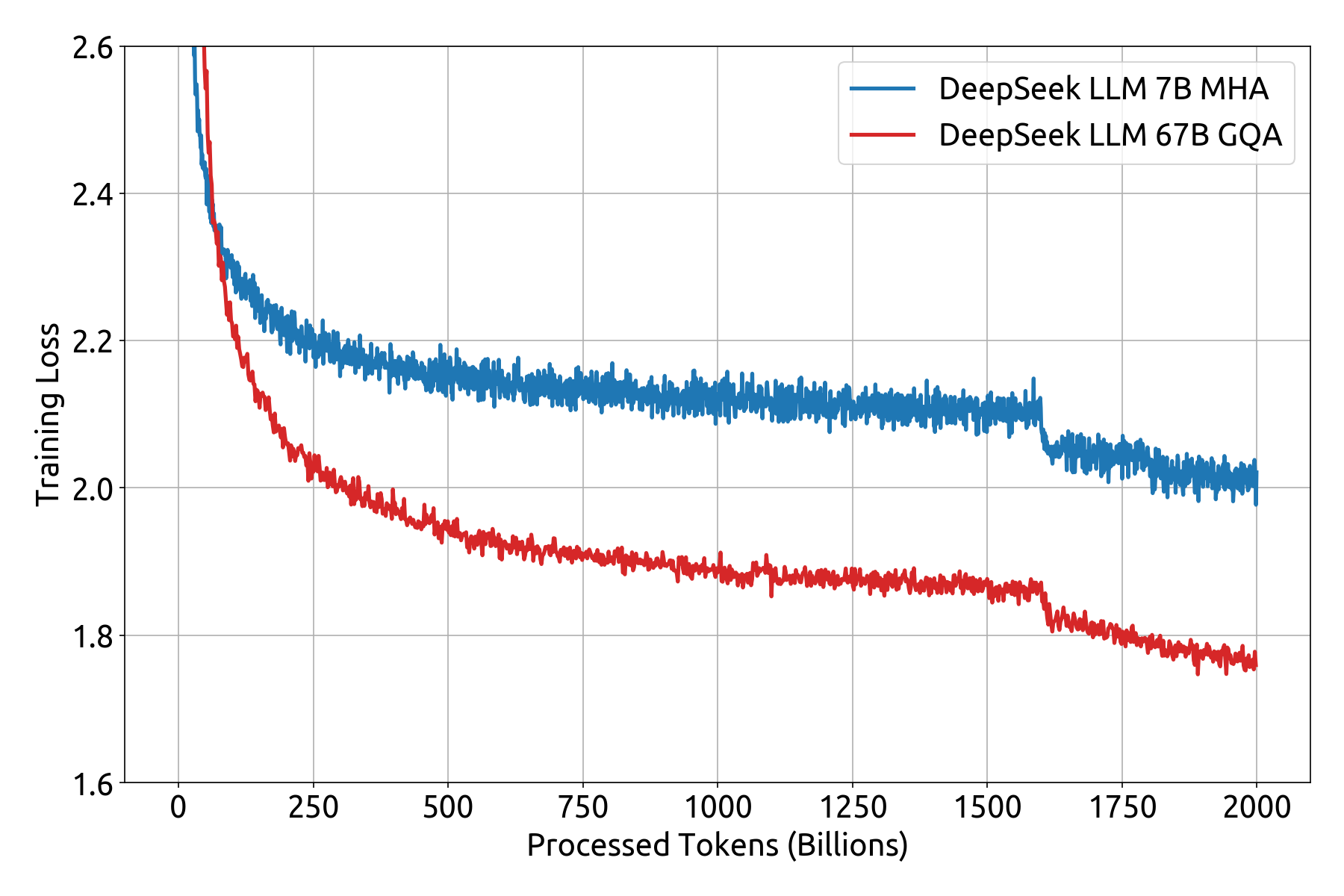
DeepSeek-LLM的成功离不开其精心设计的训练过程。模型采用了与LLaMA相同的自回归Transformer解码器架构,7B模型使用多头注意力(MHA),而67B模型则采用分组查询注意力(GQA)。
训练数据的处理也非常精细,包括多样化的数据组成、严格的数据清洗和去重流程,以及对隐私和版权的尊重。这些措施确保了模型能够学习到高质量、多样化的知识,同时避免了潜在的伦理问题。
训练过程中采用了多步学习率调度策略,通过2000步的预热和在不同训练阶段的学习率调整,有效地提高了模型的性能。
实际应用:便捷的接口和多种部署方式
DeepSeek-LLM提供了便捷的接口,支持多种部署和使用方式。研究者和开发者可以通过Hugging Face的Transformers库或vLLM等工具轻松地使用模型进行推理。
以下是使用Transformers库进行文本生成的示例代码:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/deepseek-llm-67b-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
text = "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
局限性:诚实面对,持续改进
尽管DeepSeek-LLM展现出了令人印象深刻的能力,但开发团队也诚实地指出了模型的一些局限性:
- 对训练数据的过度依赖可能导致偏见或歧视性的回应。
- 可能出现"幻觉"现象,生成看似合理但实际上不正确的内容。
- 在某些情况下可能出现重复性问题,影响输出的多样性和吸引力。
这种诚实和透明的态度值得赞赏,也为未来的改进指明了方向。
结语:开源合作,共创AI未来
DeepSeek-LLM项目的成功不仅仅在于其技术上的突破,更在于其开放和合作的精神。通过开源模型和详细的技术文档,DeepSeek AI团队为整个AI社区提供了宝贵的资源,推动了大规模语言模型研究的进步。
随着越来越多的研究者和开发者加入到这个开放的生态系统中,我们有理由相信,在不久的将来,我们将看到更多基于DeepSeek-LLM的创新应用和突破性研究成果。让我们共同期待AI技术带来的无限可能!
📚 参考资料:
🔗 相关链接:










