
DeepSeek-V2:经济高效的专家混合语言模型
DeepSeek-V2是一款由深度寻找(DeepSeek)公司开发的大型语言模型,它采用了创新的专家混合(Mixture-of-Experts, MoE)架构,在保证强大性能的同时,实现了经济高效的训练和推理。本文将详细介绍DeepSeek-V2的主要特点、创新架构、评测结果以及应用方式。
模型概览
DeepSeek-V2是一个具有2360亿总参数的大型语言模型,但对于每个token,只有210亿参数被激活。与DeepSeek公司之前的67B参数密集模型相比,DeepSeek-V2在性能上取得了显著提升,同时节省了42.5%的训练成本,将KV缓存减少了93.3%,最大生成吞吐量提高了5.76倍。这些改进主要得益于以下两个创新架构:
-
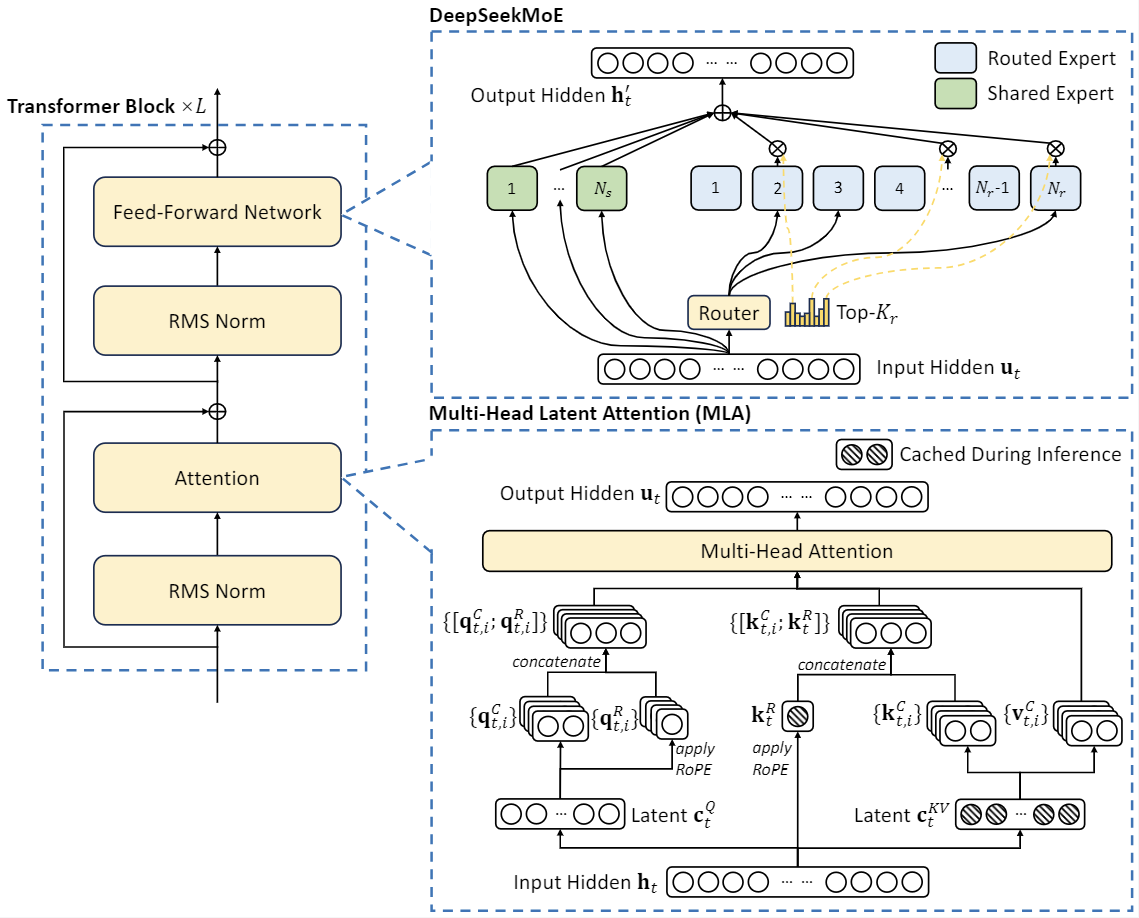
多头潜在注意力(Multi-head Latent Attention, MLA):通过低秩键值联合压缩,消除了推理时键值缓存的瓶颈,从而支持高效推理。
-
DeepSeekMoE:一种高性能的MoE架构,能够以更低的成本训练更强大的模型。
DeepSeek-V2在一个包含8.1万亿token的高质量、多源语料库上进行了预训练。随后,研究人员还对模型进行了监督微调(SFT)和强化学习(RL)处理,以充分发挥其潜力。评测结果表明,即使只激活210亿参数,DeepSeek-V2及其对话版本在开源模型中仍然能够达到顶级性能。
评测结果
基础模型评测
在标准基准测试中,DeepSeek-V2与其他大型语言模型(如LLaMA3 70B和Mixtral 8x22B)进行了比较。以下是部分评测结果:
| 基准测试 | 领域 | LLaMA3 70B | Mixtral 8x22B | DeepSeek-V1 (密集-67B) | DeepSeek-V2 (MoE-236B) |
|---|---|---|---|---|---|
| MMLU | 英语 | 78.9 | 77.6 | 71.3 | 78.5 |
| BBH | 英语 | 81.0 | 78.9 | 68.7 | 78.9 |
| C-Eval | 中文 | 67.5 | 58.6 | 66.1 | 81.7 |
| CMMLU | 中文 | 69.3 | 60.0 | 70.8 | 84.0 |
| HumanEval | 代码 | 48.2 | 53.1 | 45.1 | 48.8 |
| GSM8K | 数学 | 83.0 | 80.3 | 63.4 | 79.2 |
从结果可以看出,DeepSeek-V2在多个领域都表现出色,尤其在中文任务上有明显优势。
对话模型评测
DeepSeek-V2的对话版本也进行了全面评测,包括标准基准测试和开放式生成评估。在英语开放式生成评估中,研究人员使用了AlpacaEval 2.0和MTBench进行测试,结果显示DeepSeek-V2-Chat-RL在英语对话生成方面具有竞争力。
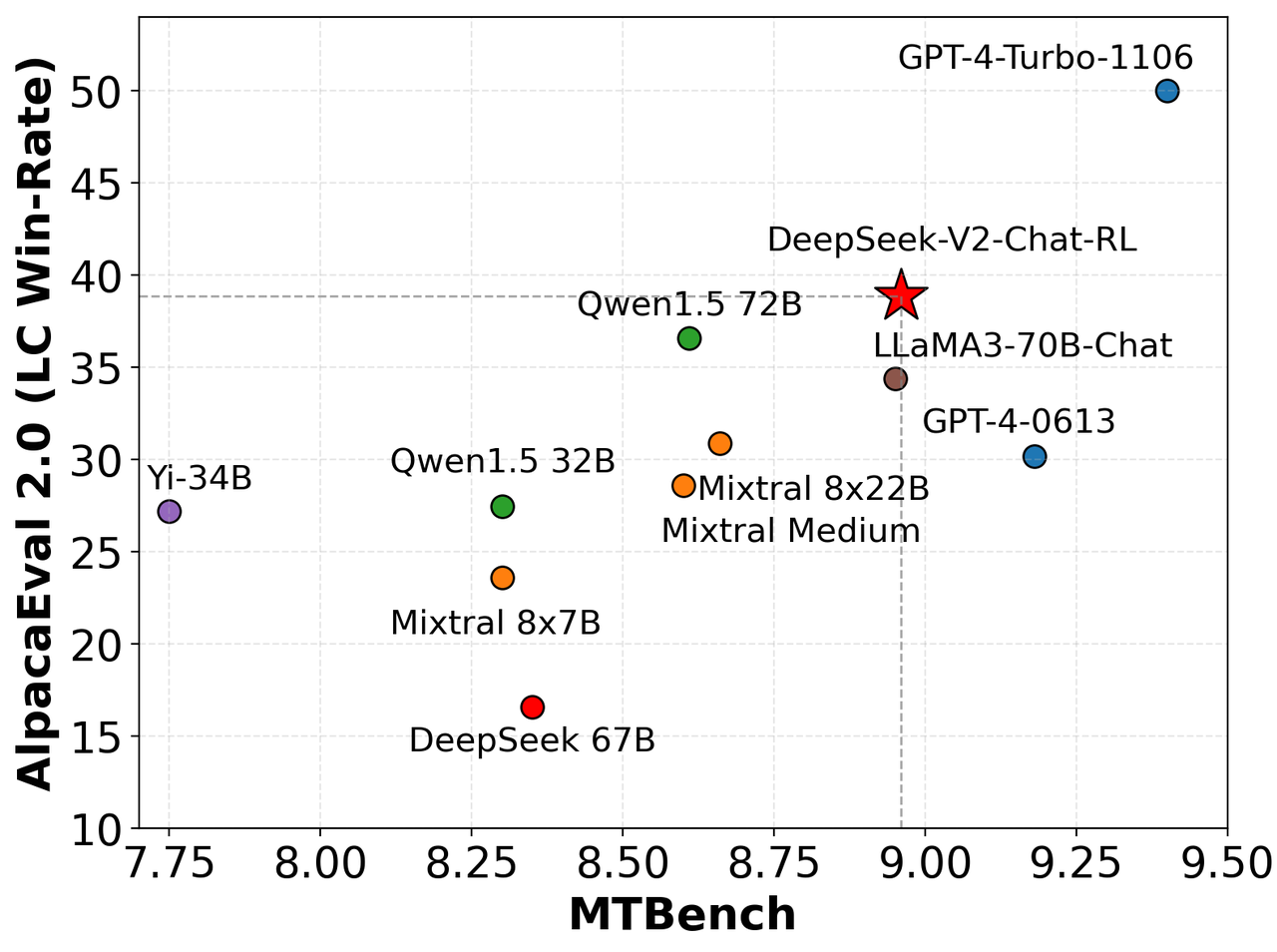
在中文开放式生成评估中,使用了Alignbench基准。DeepSeek-V2 Chat (RL)版本在总分上仅次于GPT-4,超过了多个知名的闭源和开源模型。
创新架构详解
DeepSeek-V2的核心创新在于其采用的多头潜在注意力(MLA)和DeepSeekMoE架构。
-
多头潜在注意力(MLA): MLA通过低秩键值联合压缩技术,大幅减少了推理时的键值缓存需求。这不仅提高了推理效率,还使得模型能够处理更长的上下文序列。DeepSeek-V2支持高达128K token的上下文长度,这在处理长文本任务时具有显著优势。
-
DeepSeekMoE: 这是一种专门设计的MoE架构,能够以更低的成本训练出更强大的模型。在DeepSeekMoE中,只有部分专家网络会被激活,这大大降低了计算复杂度和内存需求,同时保持了模型的强大性能。
这两项创新使得DeepSeek-V2能够在保持高性能的同时,显著降低训练和推理成本。例如,相比于DeepSeek 67B模型,DeepSeek-V2节省了42.5%的训练成本,同时性能更强。
应用与部署
DeepSeek-V2提供了多种应用方式,包括直接使用、API调用和本地部署。
-
在线对话: 用户可以在DeepSeek的官方网站chat.deepseek.com与DeepSeek-V2进行对话交互。
-
API平台: DeepSeek提供了与OpenAI兼容的API,开发者可以在platform.deepseek.com上注册使用。平台提供了大量免费token,并且支持按需付费,价格极具竞争力。
-
本地部署: 对于希望在本地环境运行DeepSeek-V2的用户,模型支持使用Hugging Face的Transformers库或vLLM进行推理。需要注意的是,运行完整的DeepSeek-V2模型需要8个80GB的GPU。
以下是使用Hugging Face Transformers库进行文本补全的示例代码:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/DeepSeek-V2"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
max_memory = {i: "75GB" for i in range(8)}
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map="sequential", torch_dtype=torch.bfloat16, max_memory=max_memory, attn_implementation="eager")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
text = "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
未来展望
DeepSeek-V2的成功为大型语言模型的经济高效开发开辟了新的方向。通过创新的架构设计,DeepSeek-V2证明了可以在不牺牲性能的前提下,显著降低模型的训练和部署成本。这为AI技术的普及和应用带来了新的可能性。
未来,我们可以期待看到更多基于DeepSeek-V2架构的应用和改进。例如:
-
领域特定模型:利用DeepSeek-V2的高效架构,为特定领域(如医疗、法律、金融等)开发专门的语言模型。
-
多模态集成:将DeepSeek-V2的文本处理能力与图像、音频等其他模态的AI模型结合,开发更全面的智能系统。
-
边缘设备部署:随着模型效率的提高,有可能将类似DeepSeek-V2这样强大的语言模型部署到边缘设备上,实现本地化的AI应用。
-
持续学习:探索如何让DeepSeek-V2等大型语言模型能够从与用户的交互中不断学习和改进,实现真正的持续进化。
总的来说,DeepSeek-V2代表了大型语言模型发展的一个重要里程碑。它不仅在性能上达到了顶级水平,更重要的是展示了如何通过创新架构设计来平衡性能和效率。这为未来AI技术的发展和应用提供了新的思路和可能性。随着技术的不断进步,我们有理由相信,像DeepSeek-V2这样的模型将在推动AI技术普及和深入应用方面发挥越来越重要的作用。










