
中文大语言模型的蓬勃发展
近年来,以ChatGPT为代表的大语言模型(Large Language Model, LLM)展现出惊人的类人工智能能力,掀起了自然语言处理领域的新一轮研究热潮。在这股浪潮中,中文大语言模型也迎来了蓬勃发展。Awesome-Chinese-LLM项目作为一个集大成者,收集和梳理了中文LLM相关的开源模型、应用、数据集及教程等资料,为我们提供了一个全面了解中文LLM生态的窗口。
中文LLM模型百花齐放
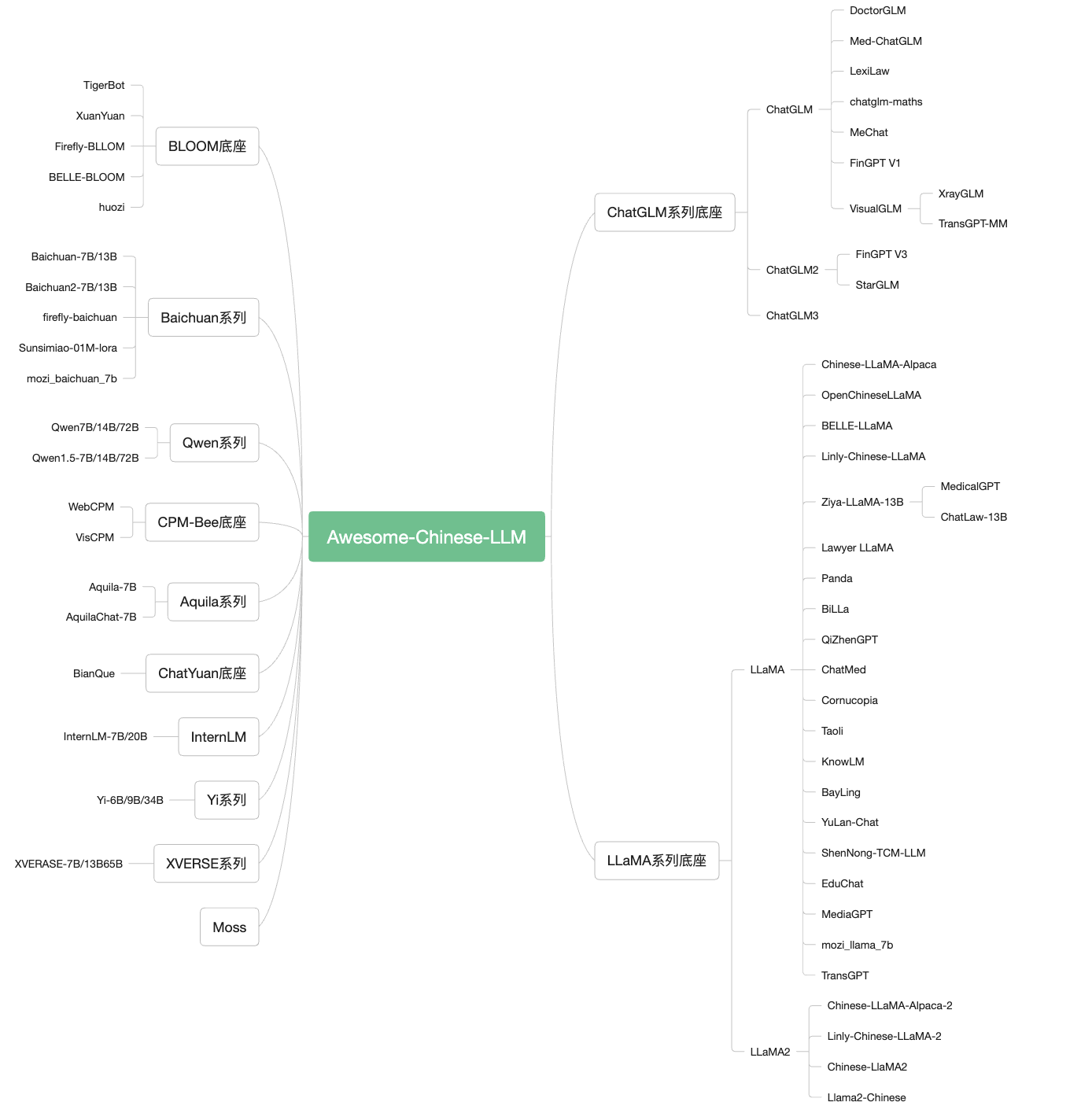
Awesome-Chinese-LLM项目收录了众多优秀的中文LLM模型。其中,ChatGLM系列、百川智能(Baichuan)系列、通义千问(Qwen)系列等模型表现尤为突出。这些模型在参数规模、训练数据量、上下文长度等方面各具特色,为不同应用场景提供了丰富的选择。
以ChatGLM为例,它是由清华大学开源的中英双语对话语言模型,包含6B、130B等不同规模版本。ChatGLM-6B作为其代表作,以仅有6B参数的轻量级设计,实现了较好的中英双语对话能力,在开源社区广受欢迎。而最新的ChatGLM3则进一步扩大了参数规模至130B,并将训练语料扩充至1.4万亿token,大幅提升了模型性能。
百川智能的Baichuan系列同样备受关注。Baichuan-13B在13B参数规模下就达到了接近GPT-3.5的性能,而最新的Baichuan2则进一步提升至千亿参数规模,展现出强大的语言理解与生成能力。
阿里云推出的通义千问(Qwen)系列则以其优秀的中文理解能力和丰富的知识储备脱颖而出。从最初的7B版本到最新的176B版本,Qwen系列不断突破参数规模的限制,在各项评测中都取得了出色的成绩。
除了这些知名模型外,Awesome-Chinese-LLM还收录了诸如Aquila、InternLM、XVERSE等一系列优秀的中文LLM模型。这些模型在参数规模、训练数据、应用场景等方面各有侧重,共同构建了一个丰富多样的中文LLM生态系统。
多模态模型拓展应用边界
除了传统的文本LLM,Awesome-Chinese-LLM项目还收录了一批优秀的多模态LLM模型,进一步拓展了中文LLM的应用边界。这些模型不仅能够理解和生成文本,还能处理图像、语音等多种模态的信息,大大增强了模型的实用性。
其中,清华大学开源的VisualGLM-6B是一个支持图像、中文和英文的多模态对话语言模型。它基于ChatGLM-6B构建,通过训练BLIP2-Qformer实现了视觉模型与语言模型的桥接。依靠高质量的中英文图文对数据集进行预训练,VisualGLM-6B展现出了优秀的多模态理解能力。
CogVLM则是另一个强大的开源视觉语言模型。它拥有100亿视觉参数和70亿语言参数,在多个跨模态基准测试中取得了SOTA性能。CogVLM能够准确描述图像,几乎不会出现幻觉现象,展现出了优秀的视觉理解能力。
阿里云推出的Qwen-VL是一个大规模视觉语言模型,支持图像、文本、检测框作为输入,并能输出文本和检测框。它在多语言对话、多图交错对话、中文开放域定位等方面都有出色表现,是首个开源的448分辨率LVLM模型,在细粒度识别和理解方面具有优势。
此外,还有支持语音-文本多模态对话的LLaSM、支持中英双语的VisCPM等模型,共同构建了一个丰富多样的中文多模态LLM生态。这些模型的出现,大大拓展了中文LLM的应用场景,为未来的智能交互系统奠定了基础。
垂直领域应用百花齐放
在Awesome-Chinese-LLM项目中,我们可以看到中文LLM在各个垂直领域的广泛应用。其中,医疗健康领域的应用尤为突出,涌现出了一批优秀的医疗LLM模型。
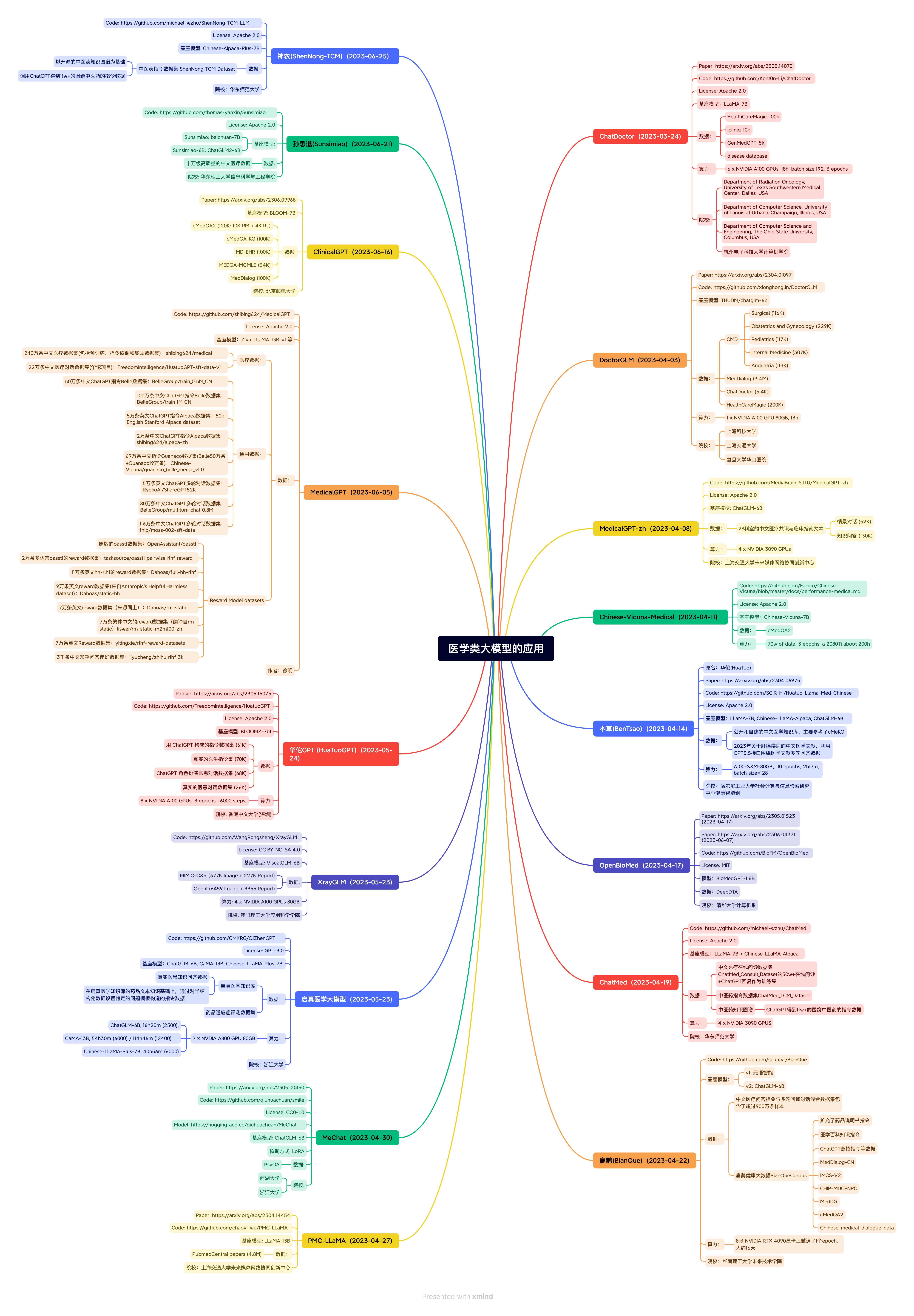
DoctorGLM是基于ChatGLM-6B的中文问诊模型,通过中文医疗对话数据集进行微调,实现了包括lora、p-tuningv2等微调及部署方案。BenTsao则是一个经过中文医学指令精调的LLaMA-7B模型,通过医学知识图谱和GPT3.5 API构建了中文医学指令数据集,提高了LLaMA在医疗领域的问答效果。
HuatuoGPT是一个经过中文医学指令精调的GPT-like模型,而Med-ChatGLM则是基于中文医学知识对ChatGLM进行微调的模型。这些模型在各自的领域都展现出了优秀的性能,为医疗健康领域的智能化提供了有力支持。
除了医疗领域,Awesome-Chinese-LLM还收录了法律、金融、教育、科技、电商等多个垂直领域的LLM应用。这些应用充分展示了中文LLM的versatility,为各行各业的智能化转型提供了可能性。
丰富的数据集与工具支持
为了支持中文LLM的研究与应用,Awesome-Chinese-LLM项目还收录了大量的数据集和工具。这些资源为模型的训练、微调和评估提供了重要支持。
在数据集方面,项目收录了预训练数据集、SFT(Supervised Fine-Tuning)数据集和偏好数据集等多种类型。这些数据集涵盖了广泛的领域和任务类型,为模型的训练和评估提供了丰富的素材。
在工具支持方面,项目收录了多个LLM训练微调框架和推理部署框架。这些工具大大降低了开发者使用和部署LLM的门槛,促进了中文LLM生态的繁荣发展。
此外,项目还收录了多个LLM评测工具和资源,为模型的性能评估提供了标准化的方法和基准。这些评测工具的存在,有助于推动中文LLM性能的不断提升。
教程资源助力学习
为了帮助开发者和研究者更好地理解和使用中文LLM,Awesome-Chinese-LLM项目还收录了大量的教程资源。这些教程涵盖了LLM基础知识、提示工程、LLM应用开发等多个方面,为学习者提供了全面的指导。
从LLM的基本原理到高级应用技巧,这些教程资源为不同层次的学习者提供了适合的学习材料。无论是初学者还是有经验的开发者,都能在这里找到有价值的学习资源。
结语
Awesome-Chinese-LLM项目为我们展示了中文大语言模型生态的蓬勃发展。从基础模型到垂直领域应用,从单模态到多模态,中文LLM正在以惊人的速度evolve,不断拓展其能力边界。
这个项目不仅是一个资源集合,更是中文LLM发展的一个缩影。它展示了开源社区的力量,也反映了学术界和产业界对中文LLM的热切关注。随着更多优秀模型和应用的涌现,中文LLM必将在未来发挥更大的作用,为人工智能的发展做出重要贡献。
对于开发者和研究者而言,Awesome-Chinese-LLM项目提供了一个宝贵的资源库和学习平台。通过这个项目,我们可以更好地了解中文LLM的最新进展,找到适合自己需求的模型和工具,并在此基础上开发出更多创新应用。
未来,我们期待看到更多优秀的中文LLM模型和应用加入到这个项目中来,共同推动中文LLM生态的繁荣发展。同时,我们也希望看到更多的研究者和开发者参与到中文LLM的研究和应用中来,为这个充满活力的领域注入新的创意和动力。










