
深度神经网络剪枝技术概述
深度神经网络在各种人工智能任务中取得了巨大成功,但随之而来的是模型规模和计算复杂度的急剧增长。为了降低模型的存储和计算开销,提高推理效率,神经网络剪枝技术应运而生,并逐渐成为深度学习领域的一个重要研究方向。
剪枝技术的核心思想是去除神经网络中对模型性能贡献较小的冗余参数或结构,从而在保持模型精度的同时显著减小模型规模。近年来,随着深度学习的快速发展,剪枝技术也取得了长足进步,出现了多种不同的剪枝策略和方法。本文将全面介绍深度神经网络剪枝技术的发展历程、主要方法以及最新研究进展。
剪枝技术的主要类型
神经网络剪枝技术主要可以分为以下几类:
-
权重剪枝(Weight Pruning): 直接移除网络中不重要的权重参数,是最基本的剪枝方法。
-
过滤器剪枝(Filter Pruning): 针对卷积神经网络,移除整个卷积过滤器,可以直接减少网络的计算量。
-
结构化剪枝(Structured Pruning): 移除网络中的整个神经元或通道,能够更好地适应硬件加速。
-
动态剪枝(Dynamic Pruning): 在推理过程中动态决定激活哪些神经元,实现自适应计算。
-
彩票假说(Lottery Ticket Hypothesis): 在随机初始化的网络中找到"中奖子网络",通过训练该子网络实现高效稀疏化。
不同类型的剪枝方法各有特点,适用于不同的应用场景。研究人员也在不断探索新的剪枝思路,以进一步提高剪枝的效果和效率。
剪枝技术的发展历程
神经网络剪枝技术的发展可以追溯到上世纪90年代。1990年,LeCun等人提出了Optimal Brain Damage方法,通过计算参数的二阶导数来评估其重要性并进行剪枝。这开创了基于重要性的剪枝方法的先河。
随后,研究人员提出了多种剪枝策略,如基于幅值的剪枝、基于能量的剪枝等。2015年,Han等人提出了迭代式剪枝方法Deep Compression,通过迭代剪枝、量化和霍夫曼编码大幅压缩模型,引起了学术界的广泛关注。
2018年,Frankle和Carbin提出了彩票假说(Lottery Ticket Hypothesis),认为在随机初始化的大型网络中存在稀疏的"中奖子网络",可以在保持精度的同时大幅减少参数量。这一假说激发了大量后续研究,成为近年来神经网络剪枝领域的重要研究方向之一。
近年来,随着神经网络结构的不断发展,针对Transformer等新型网络结构的剪枝方法也不断涌现。同时,结合神经架构搜索(NAS)、量化等技术的复合压缩方法也成为研究热点。
剪枝技术的主要方法
基于重要性的剪枝
基于重要性的剪枝方法是最常用的剪枝策略之一。其核心思想是评估网络中每个参数或结构的重要性,然后移除不重要的部分。常见的重要性度量包括:
- 参数幅值: 直接使用参数的绝对值大小作为重要性指标。
- 梯度幅值: 使用参数梯度的大小来衡量其重要性。
- 泰勒展开: 基于泰勒展开近似损失函数,评估参数对损失的影响。
- Fisher信息: 使用Fisher信息矩阵来度量参数的重要性。
基于重要性的方法实现简单,但可能会忽略参数之间的相互依赖关系。
基于优化的剪枝
基于优化的剪枝方法将剪枝问题formulate为一个优化问题,通过求解优化问题来得到稀疏的网络结构。常见的方法包括:
- L0正则化: 直接对网络参数的L0范数进行优化,得到稀疏解。
- 组稀疏正则化: 引入组稀疏约束,实现结构化剪枝。
- 交替方向乘子法(ADMM): 将剪枝问题转化为约束优化问题,通过ADMM算法求解。
基于优化的方法能够更好地考虑全局信息,但优化过程可能比较耗时。
基于重要性重构的剪枝
这类方法通过重构重要性来指导剪枝过程,代表性工作包括:
- ThiNet: 通过最小化下一层特征重构误差来选择重要的通道。
- Channel Pruning: 使用LASSO回归重构下一层特征,保留重要的通道。
- Slimming: 引入缩放因子,并对其进行稀疏正则化,实现通道剪枝。
这类方法能够更好地保持网络的表达能力,但计算开销较大。
基于神经架构搜索的剪枝
近年来,研究人员开始将神经架构搜索(NAS)技术应用于网络剪枝,通过搜索最优的稀疏结构来实现高效压缩。代表性工作包括:
- AMC: 使用强化学习来自动搜索最优的压缩策略。
- MetaPruning: 学习生成剪枝网络的超网络,实现快速剪枝。
- AutoSlim: 通过训练可调宽度的网络,自动搜索最优通道数。
基于NAS的方法能够更好地适应不同的硬件平台和性能约束,但搜索过程计算开销较大。
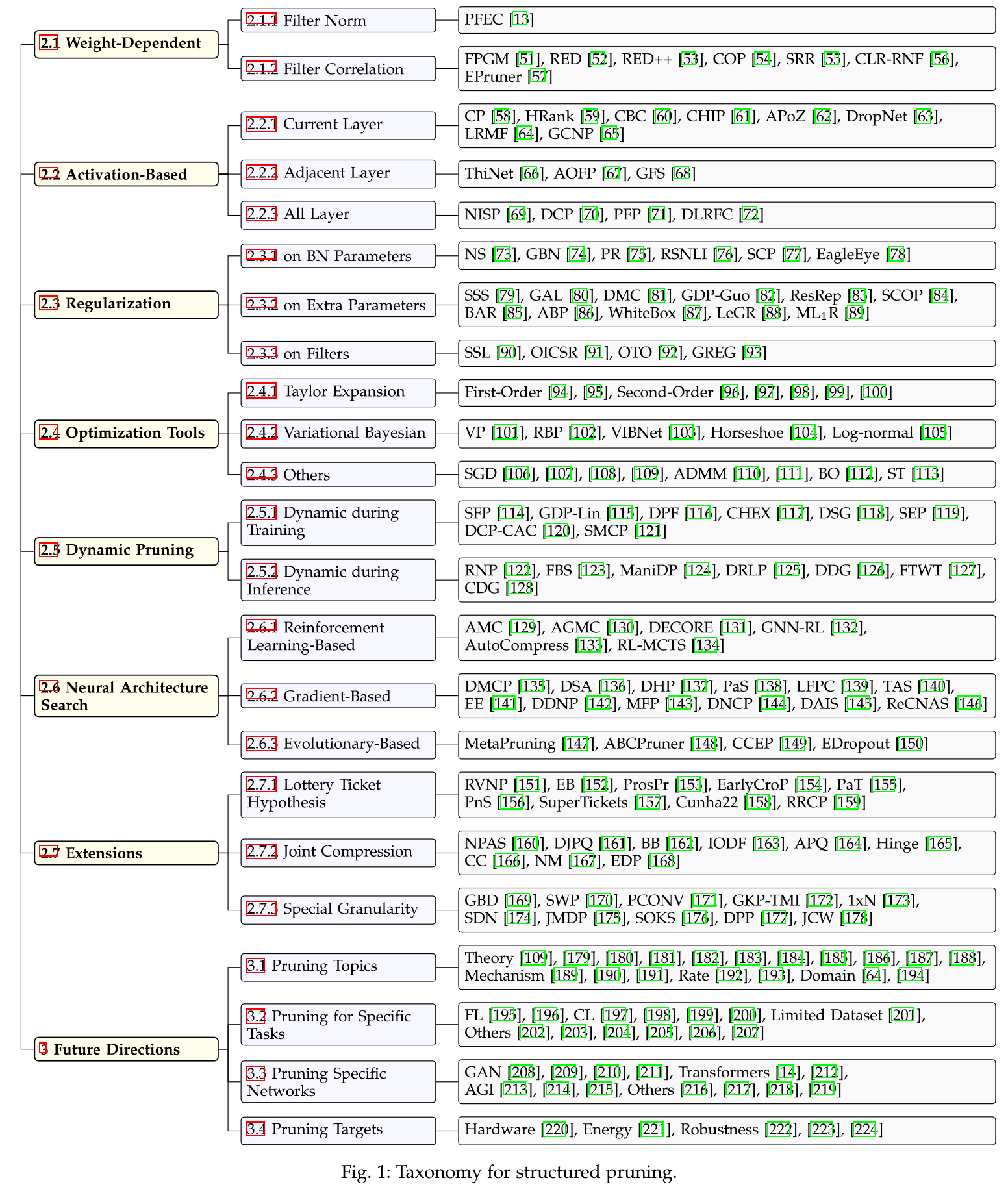
剪枝技术的最新进展
近年来,神经网络剪枝技术仍在快速发展,涌现出许多新的思路和方法。以下介绍几个重要的研究方向:
彩票假说及其扩展
彩票假说提出后引发了大量后续研究,研究人员对其进行了多方面的验证和扩展:
- 验证彩票假说在不同任务和网络结构上的适用性。
- 探索更高效的中奖票(winning ticket)搜索方法。
- 研究中奖票的可迁移性和泛化能力。
- 将彩票假说与其他压缩技术(如量化)结合。
例如,2022年ICLR的一项工作"Dual Lottery Ticket Hypothesis"进一步拓展了彩票假说的概念,探索了权重和结构两个层面的中奖票。
动态剪枝
传统的剪枝方法通常是静态的,即一旦剪枝完成,网络结构就固定不变。而动态剪枝则允许网络结构在推理过程中动态变化,从而实现更灵活的计算资源分配。近期的一些代表性工作包括:
- Runtime Neural Pruning: 在推理时动态决定激活哪些神经元。
- Dynamic Channel Pruning: 根据输入自适应地选择通道数量。
- Instance-wise Dynamic Pruning: 针对不同输入实例动态调整网络结构。
动态剪枝能够更好地适应不同输入的复杂度,在提高效率的同时保持模型的表达能力。
无需微调的剪枝
传统剪枝方法通常需要对剪枝后的网络进行微调,以恢复性能。然而,微调过程可能耗时较长,且存在过拟合风险。因此,近年来出现了一些无需微调的剪枝方法:
- SNIP: 在训练开始前通过单次前向传播确定重要性并剪枝。
- GraSP: 利用梯度信号保留对训练最重要的连接。
- SynFlow: 通过理论分析提出的剪枝准则,无需训练数据。
这些方法大大提高了剪枝的效率,但如何在不微调的情况下获得最佳性能仍是一个挑战。
鲁棒性与剪枝
随着深度学习在安全敏感领域的应用,模型的鲁棒性越来越受到关注。研究人员发现,剪枝过程可能会影响模型的鲁棒性,因此出现了一些旨在提高剪枝模型鲁棒性的工作:
- 对抗训练与剪枝的结合,提高模型抵抗对抗攻击的能力。
- 考虑不确定性的剪枝方法,提高模型在分布偏移下的泛化能力。
- 针对特定类型噪声(如高斯噪声)的鲁棒剪枝方法。
例如,2022年CVPR的工作"Masking Adversarial Damage: Finding Adversarial Saliency for Robust and Sparse Network"就探讨了如何在剪枝过程中保持模型的对抗鲁棒性。
剪枝技术的应用与挑战
神经网络剪枝技术在多个领域都有广泛应用:
- 移动端部署: 剪枝可以大幅减小模型大小,使其适合在资源受限的移动设备上运行。
- 边缘计算: 剪枝后的轻量级模型更适合在边缘设备上进行实时推理。
- 云端加速: 对大规模服务器端模型进行剪枝可以提高推理吞吐量,降低能耗。
- 联邦学习: 剪枝可以减少设备间的通信开销,提高联邦学习的效率。
尽管剪枝技术取得了显著进展,但仍面临一些挑战:
- 通用性: 如何设计适用于不同任务和网络结构的通用剪枝方法。
- 理论分析: 深入理解剪枝的工作机制,为剪枝方法的设计提供理论指导。
- 硬件适配: 如何更好地将剪枝与硬件加速结合,发挥剪枝的实际效果。
- 可解释性: 研究剪枝对模型决策过程的影响,提高模型的可解释性。
结论与展望
神经网络剪枝技术作为一种重要的模型压缩方法,在提高深度学习模型效率方面发挥着越来越重要的作用。从最初的简单权重剪枝到现在的各种复杂策略,剪枝技术已经取得了长足的进步。未来,随着硬件技术的发展和新型网络结构的出现,剪枝技术还将继续演进。
我们可以期待在以下几个方面看到更多创新:
- 结合神经架构搜索、量化等技术的端到端模型压缩框架。
- 针对Transformer等新型网络结构的高效剪枝方法。
- 可迁移、可复用的通用剪枝策略。
- 与硬件协同设计的剪枝技术。
- 考虑公平性、隐私等因素的负责任剪枝方法。
总的来说,随着人工智能技术向更高效、更可靠的方向发展,神经网络剪枝技术必将在其中扮演重要角色,为构建高效智能系统做出重要贡献。











