
引言
可微分神经计算机(Differentiable Neural Computer, DNC)是一种强大的神经网络架构,它结合了神经网络的学习能力和计算机的存储能力。本文将详细介绍一个基于PyTorch实现的DNC及其变体,包括稀疏访问存储器(Sparse Access Memory, SAM)和稀疏可微分神经计算机(Sparse Differentiable Neural Computer, SDNC)。这个实现提供了灵活的接口和丰富的功能,使研究人员和开发者能够轻松地在各种任务中应用这些先进的神经网络模型。
DNC及其变体简介
可微分神经计算机(DNC)
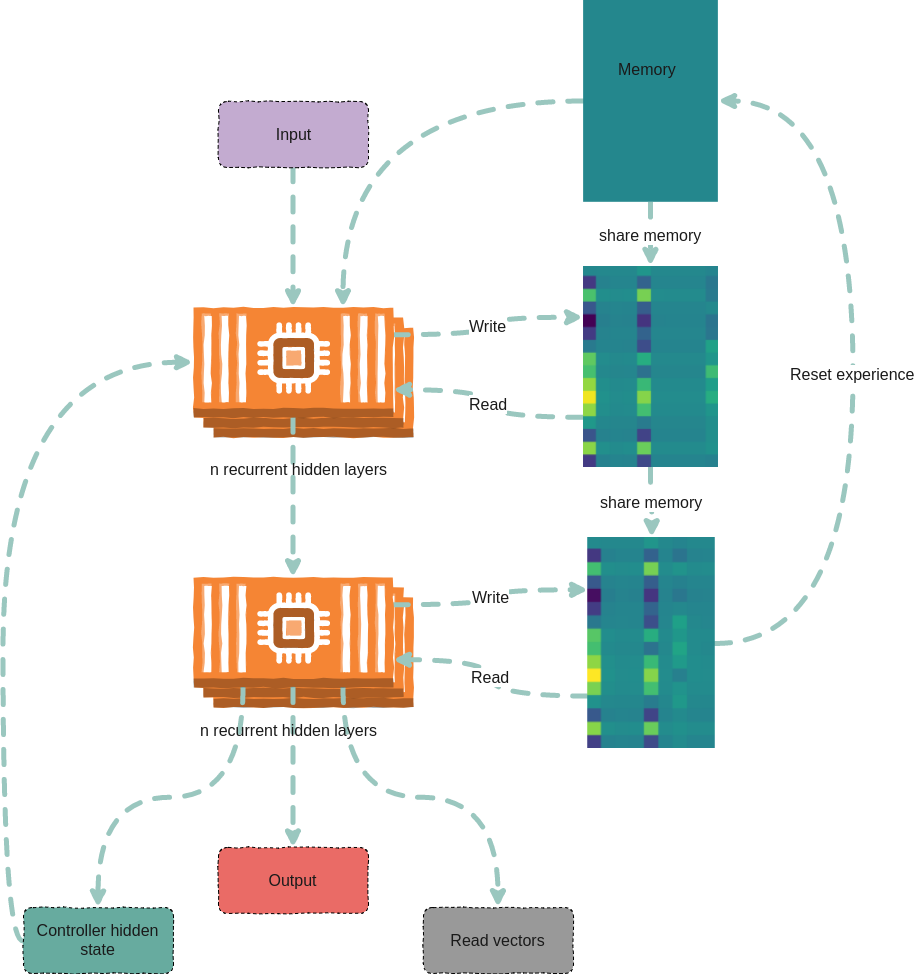
DNC是由DeepMind团队提出的一种新型神经网络架构,它通过引入外部存储器来增强神经网络的能力。DNC由一个控制器神经网络和一个可读写的存储器组成。控制器可以根据输入和当前状态来决定如何读写存储器,从而实现复杂的推理和记忆任务。
稀疏访问存储器(SAM)
SAM是DNC的一个变体,它通过引入稀疏读写操作来提高模型在大规模存储器上的效率。SAM使用近似最近邻搜索来实现快速的存储器访问,这使得它能够处理更大规模的存储器,同时保持较低的计算复杂度。
稀疏可微分神经计算机(SDNC)
SDNC结合了DNC和SAM的优点,它不仅使用稀疏读写操作,还引入了时间链接矩阵来捕捉序列信息。这使得SDNC在处理长序列和需要长期依赖的任务时表现更加出色。
实现架构
这个PyTorch实现的DNC及其变体采用了模块化的设计,主要包含以下几个核心组件:
- 控制器(Controller): 负责处理输入并生成读写操作的指令。
- 存储器(Memory): 存储和管理外部信息。
- 读写头(Read/Write Heads): 执行实际的存储器读写操作。
整个系统的工作流程如下:
- 控制器接收输入并生成接口向量。
- 接口向量被解析为读写操作的参数。
- 读写头根据这些参数对存储器进行操作。
- 读取的信息与控制器的输出结合,生成最终的网络输出。
使用方法
安装
可以通过以下命令从源代码安装:
git clone https://github.com/ixaxaar/pytorch-dnc
cd pytorch-dnc
pip install -r ./requirements.txt
pip install -e .
对于SDNC和SAM,还需要安装FAISS:
conda install faiss-gpu -c pytorch
DNC的基本用法
以下是使用DNC的一个简单例子:
from dnc import DNC
rnn = DNC(
input_size=64,
hidden_size=128,
rnn_type='lstm',
num_layers=4,
nr_cells=100,
cell_size=32,
read_heads=4,
batch_first=True,
gpu_id=0
)
(controller_hidden, memory, read_vectors) = (None, None, None)
output, (controller_hidden, memory, read_vectors) = \
rnn(torch.randn(10, 4, 64), (controller_hidden, memory, read_vectors), reset_experience=True)
SDNC的使用
SDNC的使用方式与DNC类似,但需要额外指定稀疏读取的参数:
from dnc import SDNC
rnn = SDNC(
input_size=64,
hidden_size=128,
rnn_type='lstm',
num_layers=4,
nr_cells=100,
cell_size=32,
read_heads=4,
sparse_reads=4,
temporal_reads=4,
batch_first=True,
gpu_id=0
)
SAM的使用
SAM的使用方式与SDNC类似,但不需要指定temporal_reads参数:
from dnc import SAM
rnn = SAM(
input_size=64,
hidden_size=128,
rnn_type='lstm',
num_layers=4,
nr_cells=100,
cell_size=32,
read_heads=4,
sparse_reads=4,
batch_first=True,
gpu_id=0
)
应用任务
这个实现包含了几个示例任务,用于展示DNC及其变体的能力:
复制任务
复制任务要求网络记住并重复输入的序列。这个任务可以测试网络的短期记忆能力。
python ./tasks/copy_task.py -cuda 0 -lr 0.001 -rnn_type lstm -nlayer 1 -nhlayer 2 -dropout 0 -mem_slot 32 -batch_size 1000 -optim adam -sequence_max_length 8
泛化加法任务
这个任务要求网络学习对输入的数字序列进行加法运算,并且能够泛化到更长的序列。
python ./tasks/adding_task.py -cuda 0 -lr 0.0001 -rnn_type lstm -memory_type sam -nlayer 1 -nhlayer 1 -nhid 100 -dropout 0 -mem_slot 1000 -mem_size 32 -read_heads 1 -sparse_reads 4 -batch_size 20 -optim rmsprop -input_size 3 -sequence_max_length 100
泛化Argmax任务
这个任务要求网络在最后一个时间步输出输入序列中的最大值的索引。
python ./tasks/argmax_task.py -cuda 0 -lr 0.0001 -rnn_type lstm -memory_type dnc -nlayer 1 -nhlayer 1 -nhid 100 -dropout 0 -mem_slot 100 -mem_size 10 -read_heads 2 -batch_size 1 -optim rmsprop -sequence_max_length 15 -input_size 10 -iterations 10000
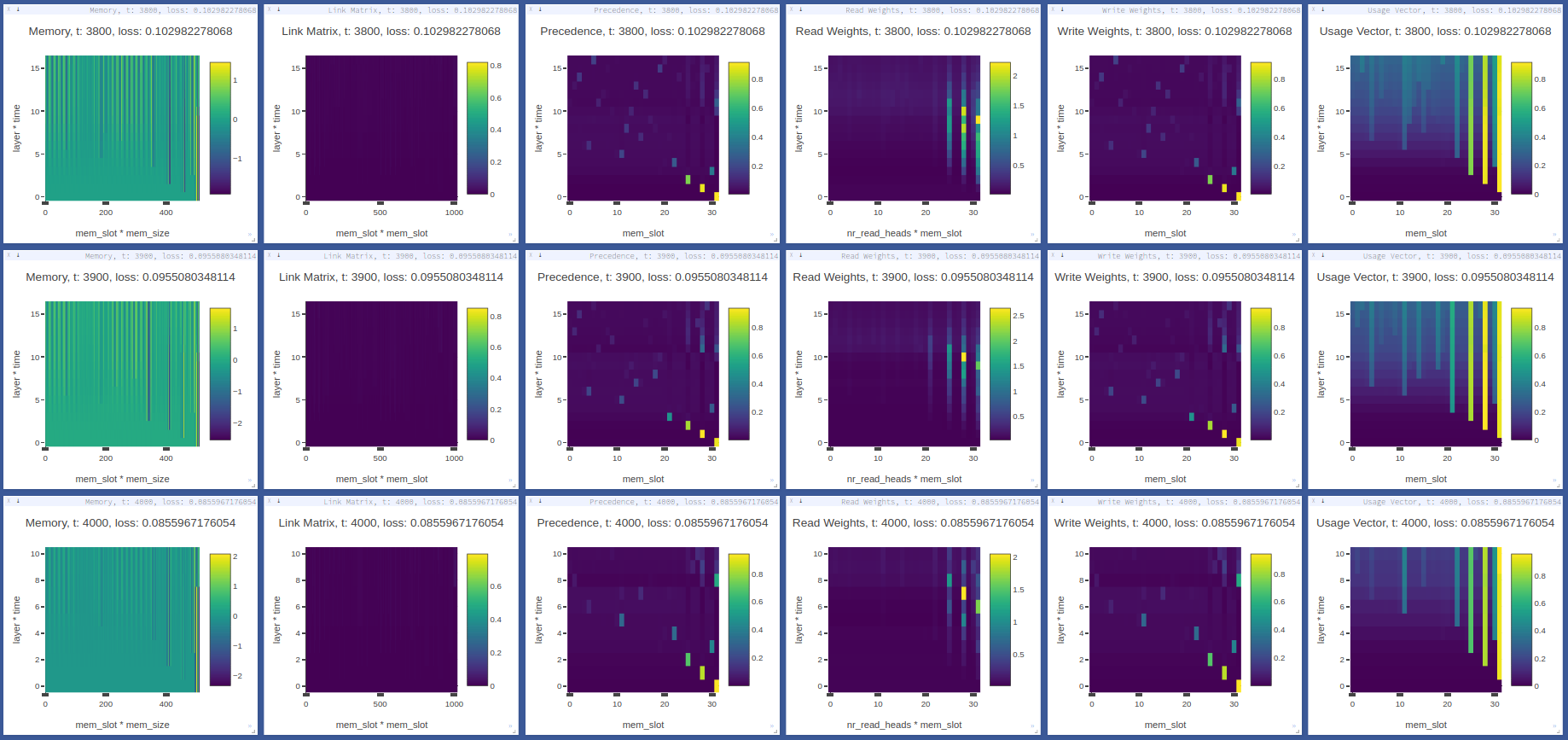
调试和可视化
这个实现提供了丰富的调试选项,可以帮助研究人员更好地理解模型的内部工作机制。通过设置debug=True,可以获取模型在每个前向传播步骤中的内部状态。
例如,对于DNC:
rnn = DNC(
input_size=64,
hidden_size=128,
rnn_type='lstm',
num_layers=4,
nr_cells=100,
cell_size=32,
read_heads=4,
batch_first=True,
gpu_id=0,
debug=True
)
output, (controller_hidden, memory, read_vectors), debug_memory = \
rnn(torch.randn(10, 4, 64), (controller_hidden, memory, read_vectors), reset_experience=True)
此外,还可以使用Visdom进行实时可视化:
pip install visdom
python -m visdom.server
然后运行任务脚本:
python ./tasks/copy_task.py -cuda 0
这将在 http://localhost:8097/ 上显示一个仪表板,展示内存使用情况的热图。
结论
PyTorch实现的DNC及其变体为研究人员和开发者提供了一个强大而灵活的工具,用于探索和应用这些先进的神经网络架构。通过提供多种模型变体、丰富的示例任务和详细的调试选项,这个实现不仅方便了模型的使用,还有助于深入理解模型的内部工作机制。
随着深度学习技术的不断发展,像DNC这样结合了神经网络和外部存储的模型有望在更多复杂任务中发挥重要作用。这个实现为进一步的研究和应用提供了坚实的基础,我们期待看到更多基于这些模型的创新应用出现。
参考资源
通过深入研究和应用这些模型,我们可以继续推动人工智能领域的发展,为更复杂的认知任务找到解决方案。🚀🧠💡









