
修图已经成为日常生活中不可或缺的功能,但AI时代必然要用点AI的方法来解决!
那么通过AI怎么能够简化我们的修图工作呢?🤔
今天小编给大家介绍一个新 T2I 模型—— Diffree!
厦门大学联合上海AI实验室与香港大学的研究团队。
Diffree 能够通过 文本描述 来无缝地添加对象到图像中,无需预先定义的遮罩。

扫码加入AI交流群
获得更多技术支持和交流

项目简介
现有的大部分文本引导的图像修复方法无法保持背景一致性,或者需要繁琐的人为干预来指定边界框或用户随意绘制的蒙版。
Diffree是一种文本转图像模型,仅使用文本控制即可实现文本引导的对象添加,可以说是一个 基于文本引导 的 无形状对象修复 与扩散模型。
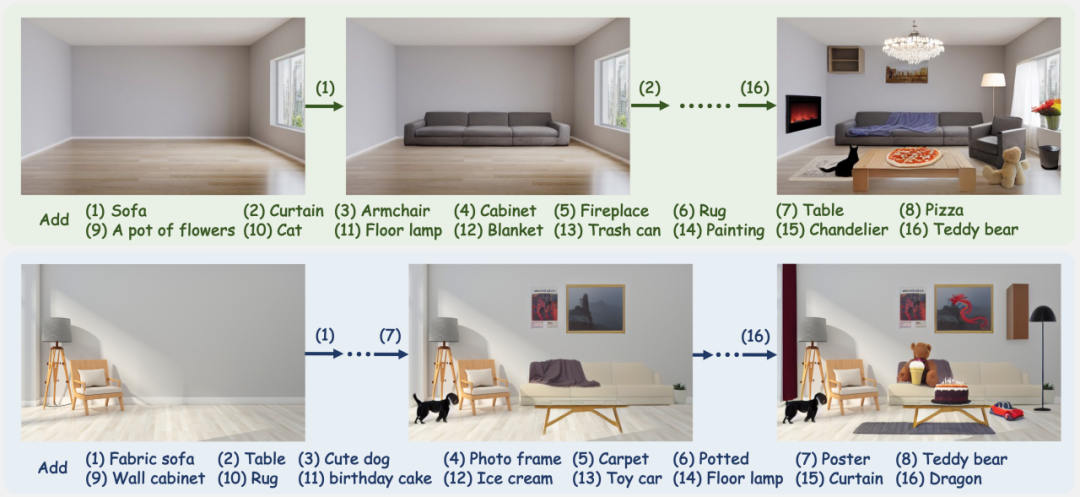
Demo


下面小编试用了一下官方放在hugging face上的demo演示,效果如下。
sunglasses


dark green pleated skirt


stop sign


技术原理
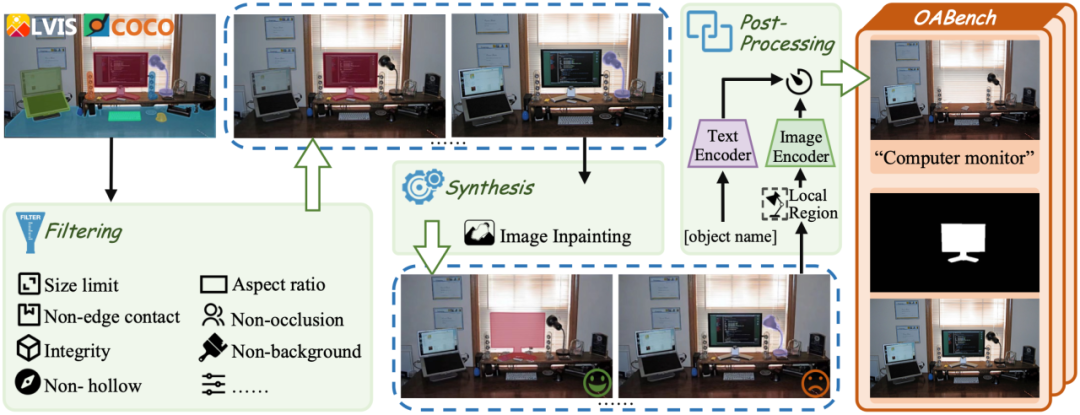
Diffree通过使用先进的图像修复技术移除对象,整理出了一个精致的合成数据集“对象添加基准”—— OABench。
OABench 包含原始图像、移除对象的修复图像、对象蒙版和对象描述的 74K 个真实世界元组。
下面的流程图概述了OABench的构建过程。
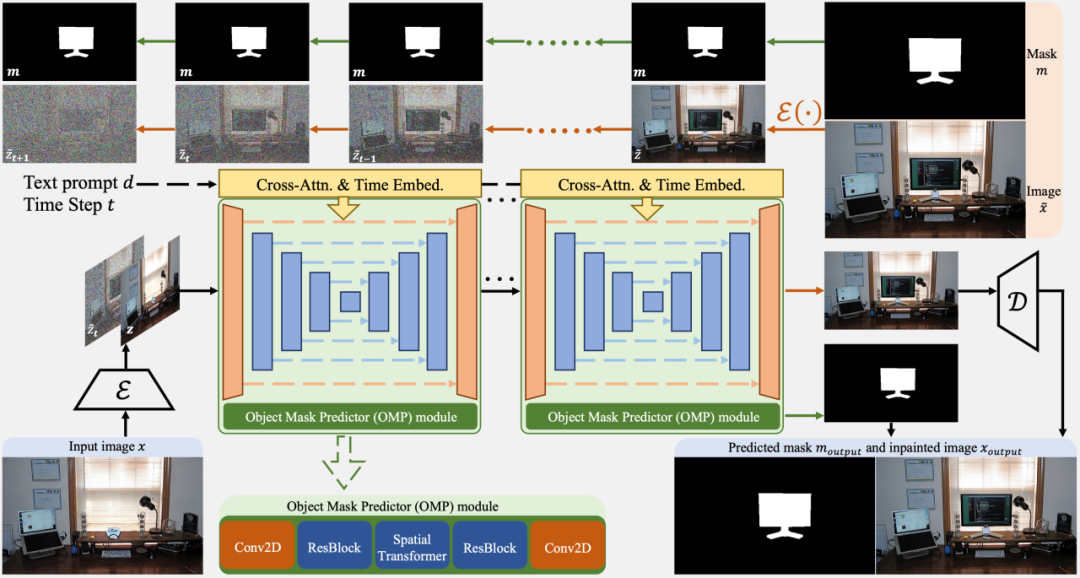
Diffree使用带有附加蒙版预测模块的稳定扩散模型在 OABench 上进行训练。
Diffree 可以唯一地预测新对象的位置,并 仅使用文本指导 即可实现对象添加,同时很好地匹配 视觉上下文。
此外,Diffree 可以使用生成的掩码迭代地将对象插入单个图像中,同时保持 背景一致性。
Diffree 还能够与其他的应用程序进行结合使用,比如与 anydoor 结合添加特定对象或者使用 GPT4V 规划应该添加的内容等。

Diffree的推出展示了AI如何在创意和设计领域中发挥越来越重要的作用。
通过强大的AI技术,越来越多的繁杂人工操作在未来都能够更加简便地实现!
🔗 项目链接:
https://opengvlab.github.io/Diffree
关注「向量光年」公众号
加速全行业向AI的改变
关注「开源AI项目落地」公众号
与AI时代更靠近一点
关注「AGI光年」公众号
获取每日最新资讯











