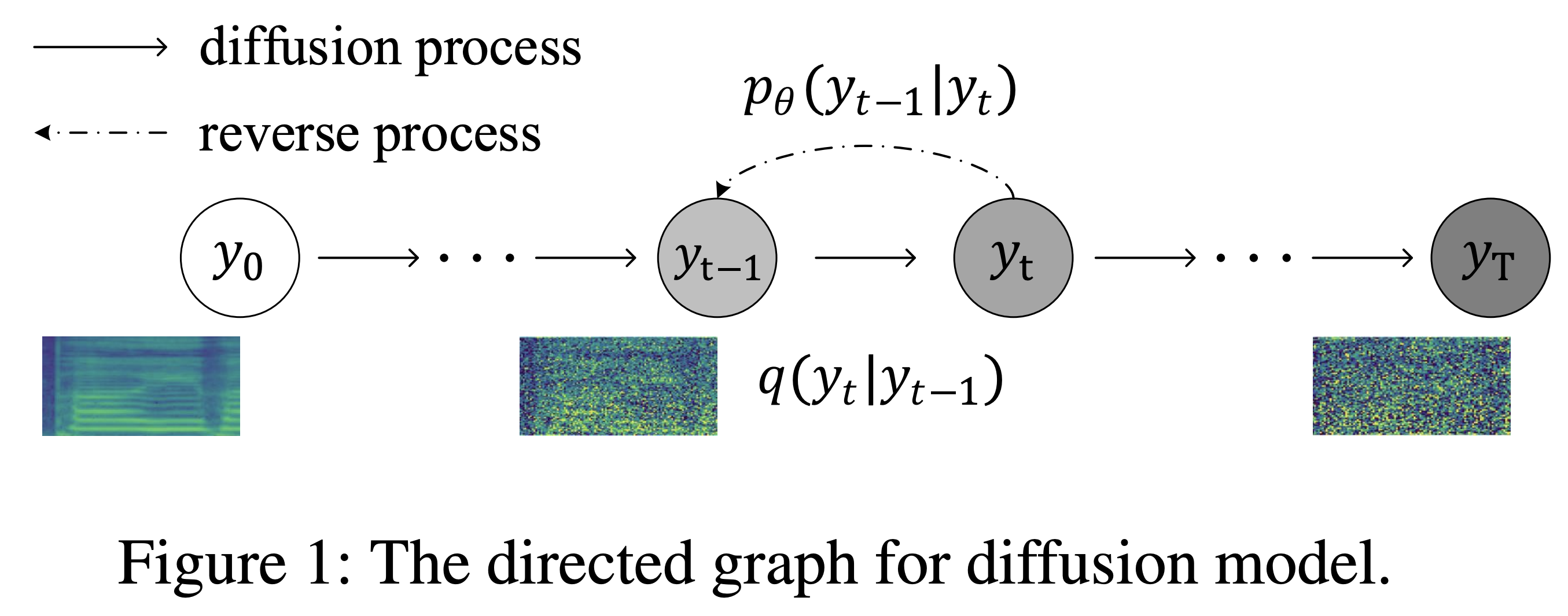
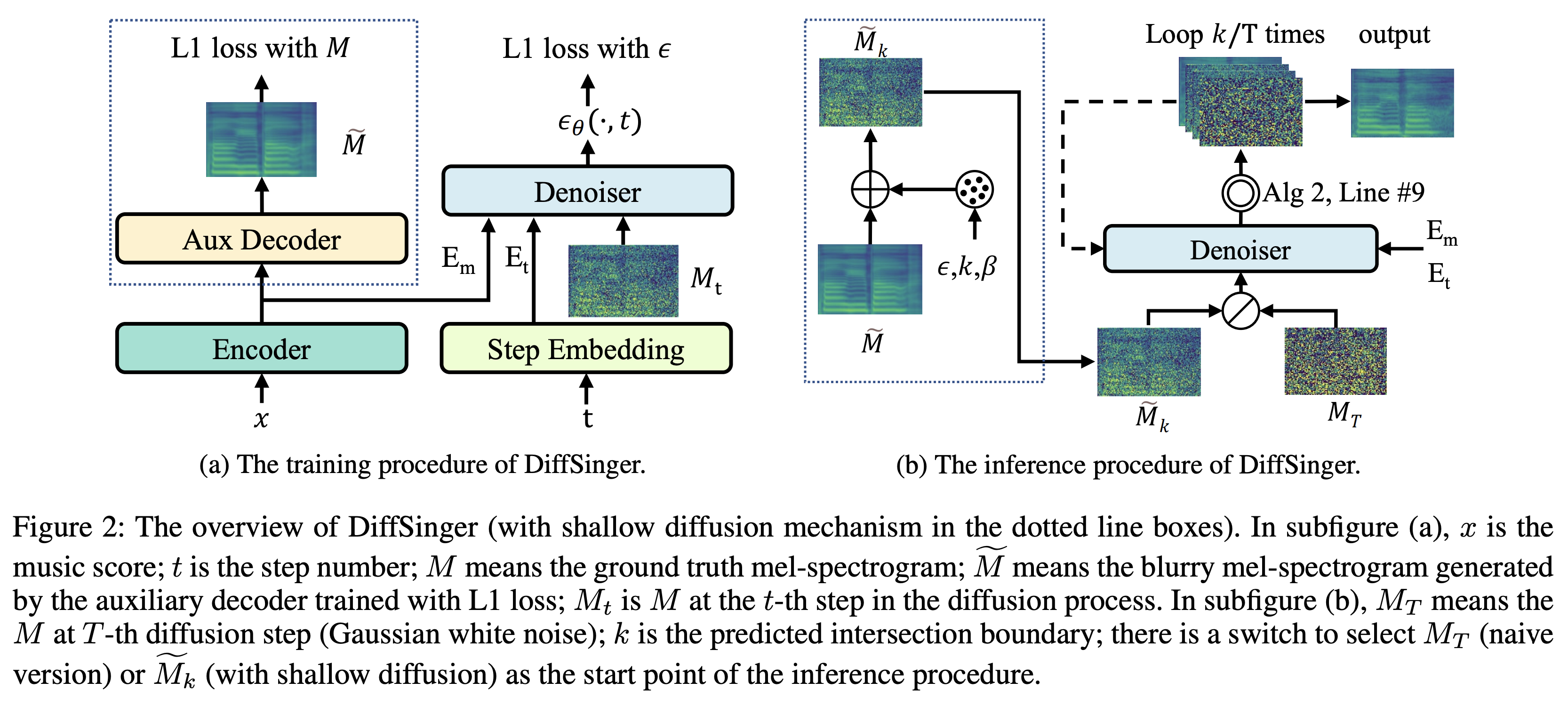
DiffSinger简介
DiffSinger是一个基于浅层扩散机制的歌声合成模型,由刘景麟等人在AAAI 2022会议上提出。该模型可以用于歌声合成(SVS)和语音合成(TTS)任务。
DiffSinger的主要特点包括:
- 使用浅层扩散机制,相比传统扩散模型可以加快生成速度
- 支持歌声合成和语音合成两种任务
- 生成质量高,可以合成自然流畅的语音和歌声
项目资源
DiffSinger的官方代码仓库: https://github.com/MoonInTheRiver/DiffSinger
该仓库包含了模型的PyTorch实现代码,以及预训练模型等资源。
学习资料
- 在线演示:
- 相关数据集:
入门指南
- 克隆项目代码:
git clone https://github.com/MoonInTheRiver/DiffSinger.git
cd DiffSinger
- 安装依赖:
pip install -r requirements.txt
-
下载预训练模型并放置到指定目录
-
运行推理脚本生成语音或歌声样本
-
按照文档说明训练自己的模型
相关项目
总结
DiffSinger作为一个新的歌声合成模型,在性能和生成质量上都达到了很高的水平。本文整理的学习资料可以帮助读者快速入门,掌握DiffSinger的使用方法。随着该模型的不断发展,相信会在语音合成领域发挥越来越重要的作用。