
Distributed Llama简介
Distributed Llama是一个开源项目,旨在通过张量并行化技术在多台设备上分布式运行大型语言模型(LLM)。它可以在普通的CPU设备上运行LLM,通过分布工作负载来提高推理速度,并将RAM使用量分散到多个节点上。这个项目证明了可以将LLM的工作负载分割到多个设备上,并实现显著的加速。
主要特点:
- 可以在家用设备上运行大型LLM模型
- 使用TCP套接字同步状态
- 可以使用家用路由器轻松配置AI集群
- 支持Llama、Mixtral、Grok等模型架构

快速开始
- 安装Python 3和C++编译器
- 使用以下命令下载模型和分词器:
python launch.py llama3_8b_instruct_q40
- 运行根节点:
./dllama chat --model dllama_model_llama3.1_instruct_q40.m --tokenizer dllama_tokenizer_llama_3_1.t --buffer-float-type q80 --nthreads 4
- 在其他设备上运行工作节点:
./dllama worker --port 9998 --nthreads 4
- 添加工作节点地址到根节点命令:
./dllama chat ... --workers 192.168.0.1:9998 192.168.0.2:9998
详细文档
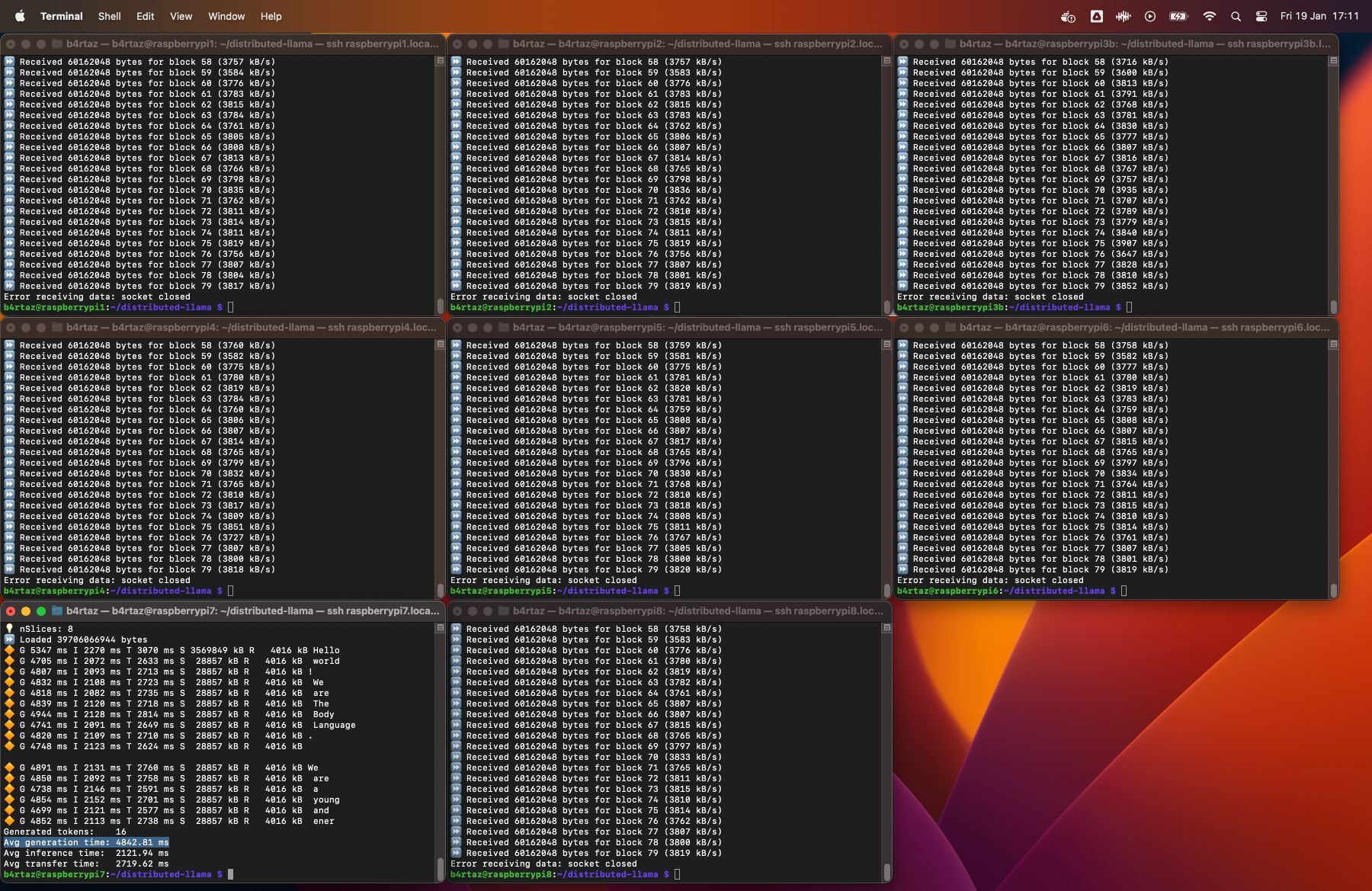
性能测试
项目提供了详细的性能测试数据,包括:
- 不同设备(Raspberry Pi、云服务器等)上的平均令牌生成时间
- 多设备并行时的加速比
- 网络传输开销
项目链接
总结
Distributed Llama为在普通硬件上运行大型语言模型提供了一种创新的解决方案。通过分布式推理,它使得在家用设备上部署先进AI模型成为可能。无论是个人学习还是小型团队开发,这个项目都值得一试。
欢迎有兴趣的读者进一步探索该项目,为开源AI社区做出贡献!










