
DoWhy:让因果推断变得简单而强大
在当今数据驱动的世界里,理解事物之间的因果关系变得越来越重要。然而,传统的统计方法往往只能揭示相关性,而无法确定真正的因果关系。为了解决这一问题,微软研究院开发了DoWhy——一个强大而易用的Python库,旨在简化和标准化因果推断过程。
DoWhy的核心理念
DoWhy的设计理念是让因果推断变得像机器学习预测一样简单。就像scikit-learn等库为预测任务提供了标准化接口一样,DoWhy为因果推断提供了一个统一的框架。这个框架结合了两个主要的因果推断方法:因果图模型和潜在结果框架。
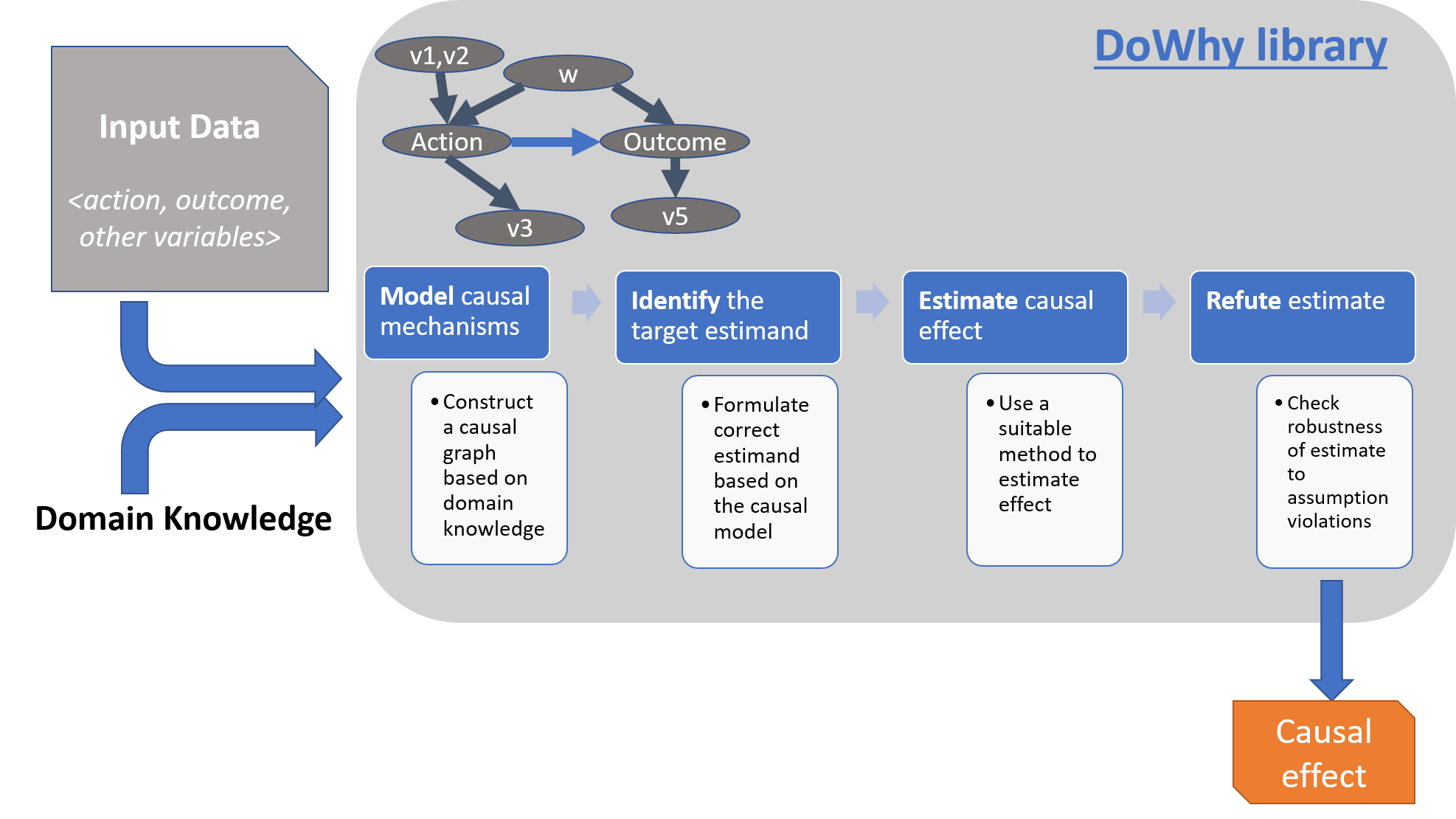
DoWhy的四步因果分析流程
DoWhy提供了一个原则性的四步接口来进行因果推断:
- 建模:使用因果图明确表示数据生成过程中的假设。
- 识别:确定给定假设下是否可以估计因果效应。
- 估计:使用各种统计方法估计因果效应。
- 验证:进行稳健性检查和敏感性分析,测试估计的可靠性。
这种结构化的方法确保了分析的每个步骤都是明确的,并且可以被独立评估。
DoWhy的主要特性
-
明确的因果假设建模:DoWhy使用因果图来表示分析中的假设,使这些假设变得透明和可测试。
-
统一的估计方法接口:支持多种因果效应估计方法,包括后门调整、工具变量、前门准则等。
-
自动化的反事实验证:提供了一套强大的验证工具,可以自动测试估计的稳健性。
-
与其他库的集成:DoWhy可以与EconML和CausalML等库无缝集成,用于条件平均处理效应(CATE)的估计。
使用DoWhy进行因果分析
以下是使用DoWhy进行基本因果分析的示例代码:
from dowhy import CausalModel
import dowhy.datasets
# 加载示例数据
data = dowhy.datasets.linear_dataset(
beta=10,
num_common_causes=5,
num_instruments=2,
num_samples=10000,
treatment_is_binary=True)
# 1. 建模:创建因果模型
model = CausalModel(
data=data["df"],
treatment=data["treatment_name"],
outcome=data["outcome_name"],
graph=data["gml_graph"])
# 2. 识别:确定因果效应是否可识别
identified_estimand = model.identify_effect()
# 3. 估计:使用统计方法估计因果效应
estimate = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_matching")
# 4. 验证:对估计进行多重稳健性检查
refute_results = model.refute_estimate(identified_estimand, estimate,
method_name="random_common_cause")
这个例子展示了DoWhy的四个主要步骤:建模、识别、估计和验证。每一步都清晰可见,使得分析过程更加透明和可重复。
DoWhy的应用场景
DoWhy可以应用于各种需要因果推断的领域,例如:
- 经济学:评估政策干预的效果
- 医学研究:分析治疗对患者结果的影响
- 市场营销:测量广告活动对销售的因果影响
- 社会科学:研究教育政策对学生成绩的影响
结论
DoWhy为因果推断提供了一个强大而灵活的框架,使得复杂的因果分析变得更加accessible和标准化。通过明确的假设建模、统一的接口和自动化的验证工具,DoWhy帮助研究人员和数据科学家更加自信地进行因果推断,从而做出更好的决策。
随着因果推断在数据科学和机器学习领域的重要性日益增加,DoWhy无疑将成为这一领域的重要工具。无论你是研究人员、数据科学家还是决策者,DoWhy都能帮助你更好地理解和利用数据中的因果关系。









