
DriveLM:基于图视觉问答的自动驾驶模型
DriveLM是一个创新的自动驾驶项目,它通过图视觉问答(GVQA)技术将语言理解和推理能力引入自动驾驶领域。本文将为您介绍DriveLM的核心概念、主要特点以及相关学习资源,帮助您快速了解这一前沿技术。
项目概述
DriveLM由OpenDriveLab团队开发,是一个基于图视觉问答的端到端自动驾驶系统。该项目的主要创新点包括:
- 提出了DriveLM-Data数据集,基于nuScenes和CARLA构建
- 设计了Graph VQA任务,将感知、预测、规划等驾驶子任务通过问答形式联系起来
- 提出了DriveLM-Agent基线模型,可同时执行Graph VQA和端到端驾驶
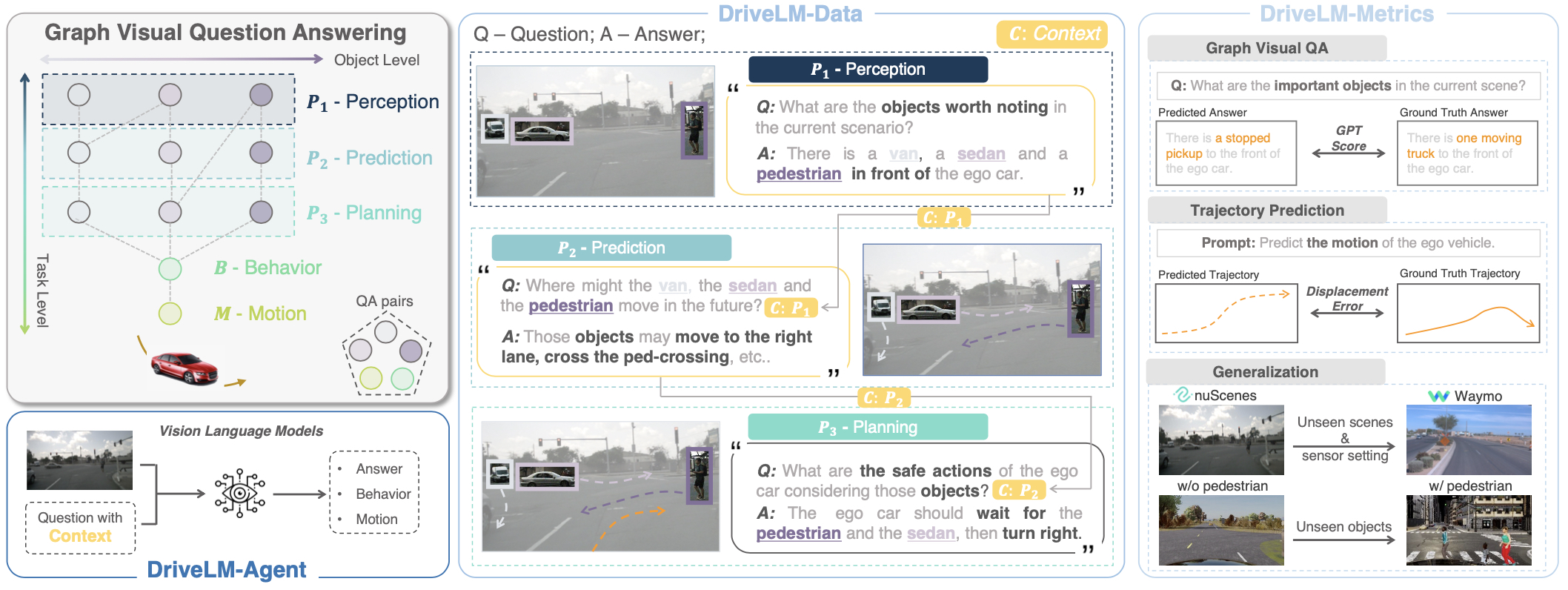
核心特性
-
DriveLM-Data数据集: 首个支持全栈驾驶任务的语言-驾驶数据集,具有图结构化的逻辑依赖关系。
-
Graph VQA任务: 通过图结构化的问答对来模拟人类驾驶推理过程。
-
DriveLM-Agent: 基于视觉-语言模型(VLM)的基线方法,可联合执行Graph VQA和端到端驾驶。
-
CVPR 2024自动驾驶挑战赛主赛道: DriveLM作为CVPR 2024自动驾驶挑战赛的主赛道之一。
快速入门
-
准备数据集:
-
挑战赛开发套件:
-
论文阅读:
-
在线演示:
项目资源
- GitHub仓库: OpenDriveLab/DriveLM
- 项目主页: DriveLM Project Page
- 挑战赛主页: Autonomous Driving Challenge 2024
相关工作
DriveLM是自动驾驶与大语言模型结合的前沿探索之一。以下是一些相关的开源项目,可供进一步学习:
总结
DriveLM项目为自动驾驶领域引入了语言理解和推理能力,为解决数据缺乏、模型具身化和闭环规划等挑战提供了新的思路。通过本文介绍的学习资源,相信读者可以快速入门DriveLM技术,并在此基础上进行更深入的研究与应用。
随着项目的不断更新,更多相关资源将陆续发布。欢迎关注OpenDriveLab的Twitter账号以获取最新动态。









