
dtwclust:强大的时间序列聚类R包
dtwclust是一个专门用于时间序列聚类的R包,它提供了丰富的聚类策略以及针对动态时间规整(Dynamic Time Warping, DTW)距离及其相应下界的一系列优化。这个包不仅实现了传统的聚类算法,还包括了一些最新的聚类方法,如k-Shape和TADPole聚类。更重要的是,dtwclust的功能可以通过自定义距离度量和质心定义轻松扩展,为研究人员和数据分析师提供了极大的灵活性。
主要特性
dtwclust包含了多种聚类算法和相关技术:
-
多种聚类方法:
- 划分聚类
- 层次聚类
- 模糊聚类
- k-Shape聚类
- TADPole聚类
-
DTW相关优化:
- 优化版本的DTW算法
- Keogh和Lemire的DTW下界
-
其他距离度量:
- 全局对齐核(Global Alignment Kernel, GAK)距离
- 基于形状的距离(Shape-based Distance)
-
质心计算方法:
- DTW重心平均(DTW Barycenter Averaging)
- 软DTW(Soft-DTW)距离和质心
-
多变量支持:
- 支持GAK、DTW和软DTW的多变量时间序列
-
聚类有效性指标:
- 提供清晰和模糊的内部和外部聚类有效性指标
-
并行计算:
- 大多数函数支持并行化,提高计算效率
安装与使用
dtwclust可以从CRAN直接安装:
install.packages("dtwclust")
如果想要尝试最新的开发版本,可以从GitHub安装:
# 首先安装remotes包
install.packages("remotes")
# 然后从GitHub安装dtwclust
remotes::install_github("asardaes/dtwclust")
基本用法示例
以下是使用dtwclust进行基本聚类分析的一些示例:
- 划分聚类
library(dtwclust)
data("uciCT")
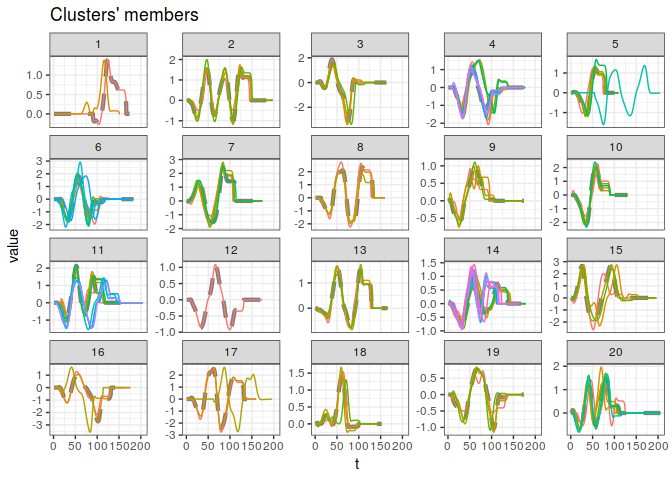
pc <- tsclust(CharTraj, type = "partitional", k = 20L,
distance = "dtw_basic", centroid = "pam",
seed = 3247L, trace = TRUE,
args = tsclust_args(dist = list(window.size = 20L)))
plot(pc)
- 层次聚类
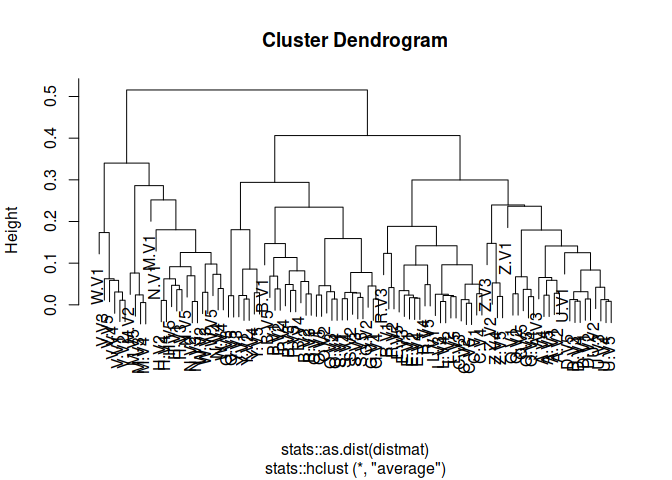
hc <- tsclust(CharTraj, type = "hierarchical", k = 20L,
distance = "sbd", trace = TRUE,
control = hierarchical_control(method = "average"))
plot(hc)
- 模糊聚类
acf_fun <- function(series, ...) {
lapply(series, function(x) {
as.numeric(acf(x, lag.max = 50L, plot = FALSE)$acf)
})
}
fc <- tsclust(CharTraj[1L:25L], type = "fuzzy", k = 5L,
preproc = acf_fun, distance = "L2",
seed = 123L)
print(fc)
- 多变量时间序列聚类
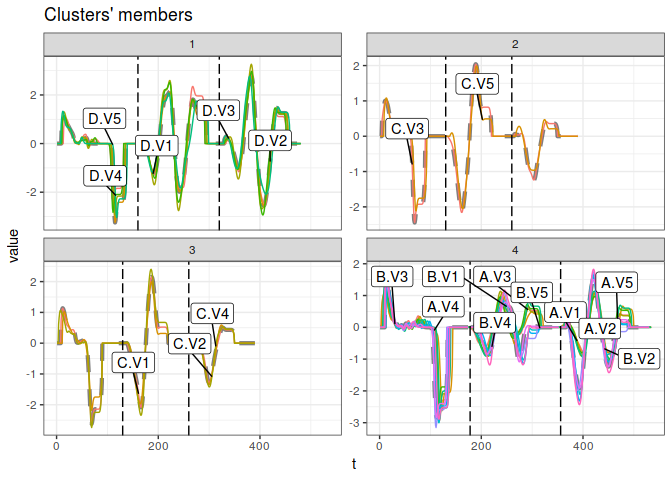
mvc <- tsclust(CharTrajMV[1L:20L], k = 4L, distance = "gak", seed = 390L)
plot(mvc, labels = list(nudge_x = -10, nudge_y = 1))
高级特性
-
自定义距离度量: dtwclust允许用户注册自定义的距离函数,这些函数可以通过proxy包与现有的聚类算法无缝集成。
-
并行计算: 对于计算密集型任务,dtwclust支持并行计算,可以显著提高处理大规模数据集的效率。
-
聚类结果评估: 包提供了多种聚类有效性指标,帮助用户评估和比较不同的聚类结果。
-
可视化: dtwclust集成了强大的可视化功能,可以直观地展示聚类结果和时间序列数据。
应用场景
dtwclust在多个领域都有广泛的应用,包括但不限于:
- 金融市场分析:识别相似的股票价格模式
- 气象学:分析气候模式和天气预报
- 生物信息学:基因表达数据的聚类分析
- 工业监控:识别机器运行状态的异常模式
- 人体运动分析:识别和分类不同的运动模式
结论
dtwclust为R用户提供了一个强大而灵活的时间序列聚类工具。它不仅实现了多种先进的聚类算法,还提供了针对DTW距离的优化,使得大规模时间序列数据的处理变得更加高效。无论是在学术研究还是实际应用中,dtwclust都是一个值得考虑的优秀工具。
对于那些需要深入分析时间序列数据,寻找隐藏模式,或者进行预测建模的研究者和数据科学家来说,dtwclust无疑是一个不可或缺的R包。通过其丰富的功能和灵活的接口,用户可以轻松地探索复杂的时间序列数据集,发现有意义的群集,并从中获得洞察。
随着时间序列数据在各个领域的重要性不断提升,dtwclust这样的工具将在数据分析和机器学习领域扮演越来越重要的角色。无论您是刚开始接触时间序列分析,还是寻求更高级的聚类技术,dtwclust都能满足您的需求,帮助您更好地理解和利用时间序列数据。









