
DVC简介:数据科学的版本控制利器
在当今数据驱动的时代,数据科学和机器学习项目变得越来越复杂。如何有效地管理数据、跟踪实验、协作开发成为了一大挑战。DVC(Data Version Control)应运而生,它是一款专为数据科学和机器学习项目设计的开源版本控制工具,为数据科学家和机器学习工程师提供了类似Git的使用体验,帮助他们更好地组织数据、模型和实验。
DVC的核心功能包括:
- 数据和模型的版本控制:将数据和模型存储在云存储中,同时在Git仓库中保留版本信息。
- 轻量级管道:通过定义数据处理流程,在修改时只需重新运行受影响的步骤。
- 本地实验跟踪:在本地Git仓库中跟踪实验,无需额外服务器。
- 实验对比:可以比较任何数据、代码、参数、模型或性能图表。
- 实验共享:轻松分享实验并自动复现他人的实验结果。
通过这些功能,DVC极大地提高了数据科学项目的可重复性、可追溯性和协作效率。
DVC的工作原理
DVC的工作原理可以概括为以下几个方面:
-
Git集成: DVC与Git紧密集成,使用Git来存储和版本控制代码(包括DVC元文件)。这保留了开发人员熟悉的Git工作流程。
-
数据存储: DVC将大型数据文件和模型文件存储在Git仓库之外的缓存中,同时在Git中保留这些文件的占位符。这种方式避免了将大文件直接存入Git仓库,同时保持了版本控制的能力。
-
远程存储: DVC支持多种远程存储平台,包括各种云存储服务(如S3、Azure、Google Cloud等)和本地网络存储(如SSH)。这使得团队可以方便地共享和备份数据缓存。
-
管道定义: DVC使用类似Makefile的方式来定义数据处理管道。这些管道描述了如何从其他数据和代码构建数据或模型。
-
实验管理: DVC提供了本地实验管理功能,允许用户在自己的机器上进行实验跟踪,并使用现有的Git托管服务(如Github、Gitlab)进行协作。
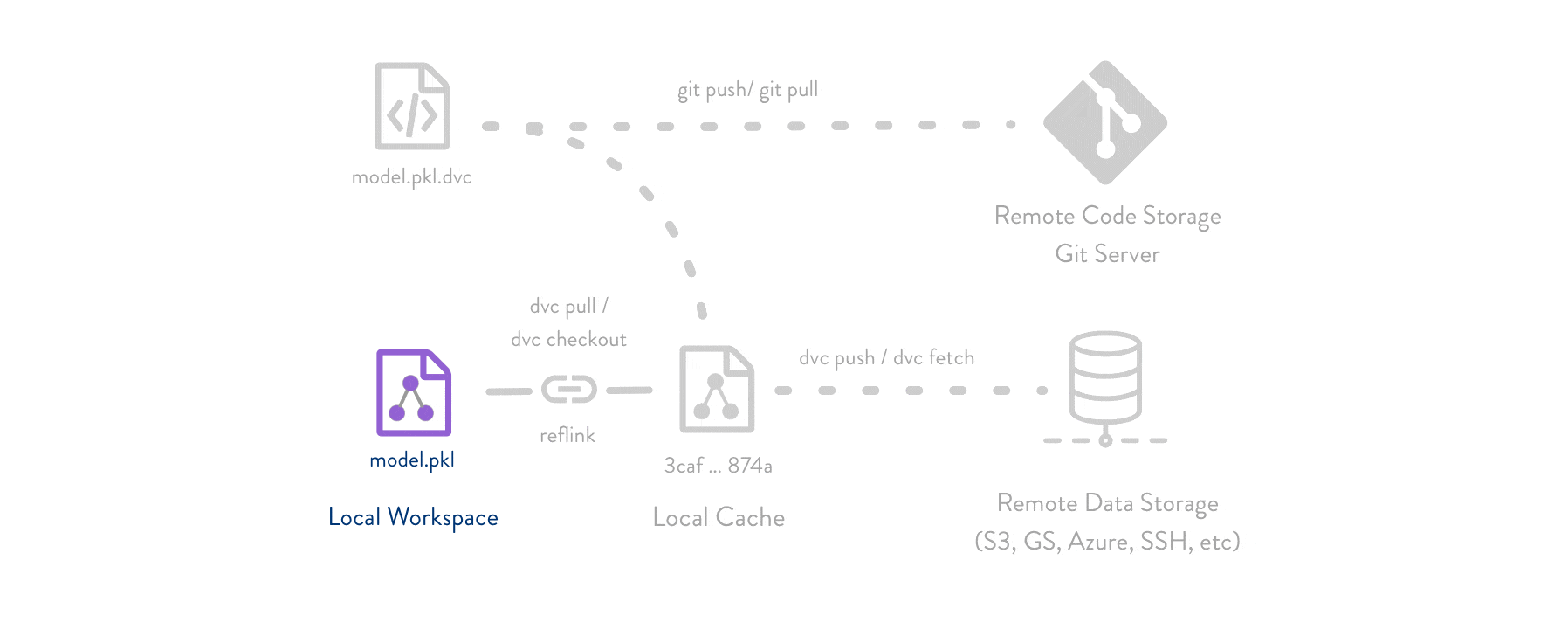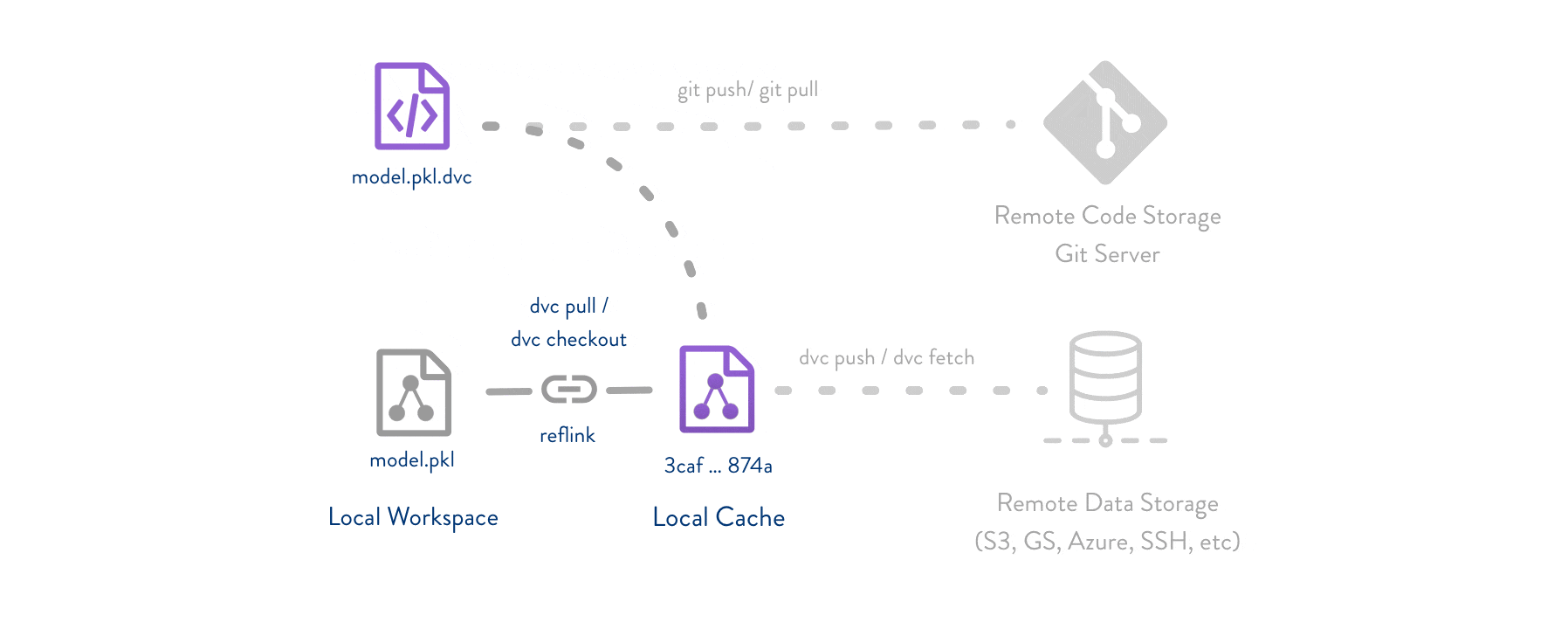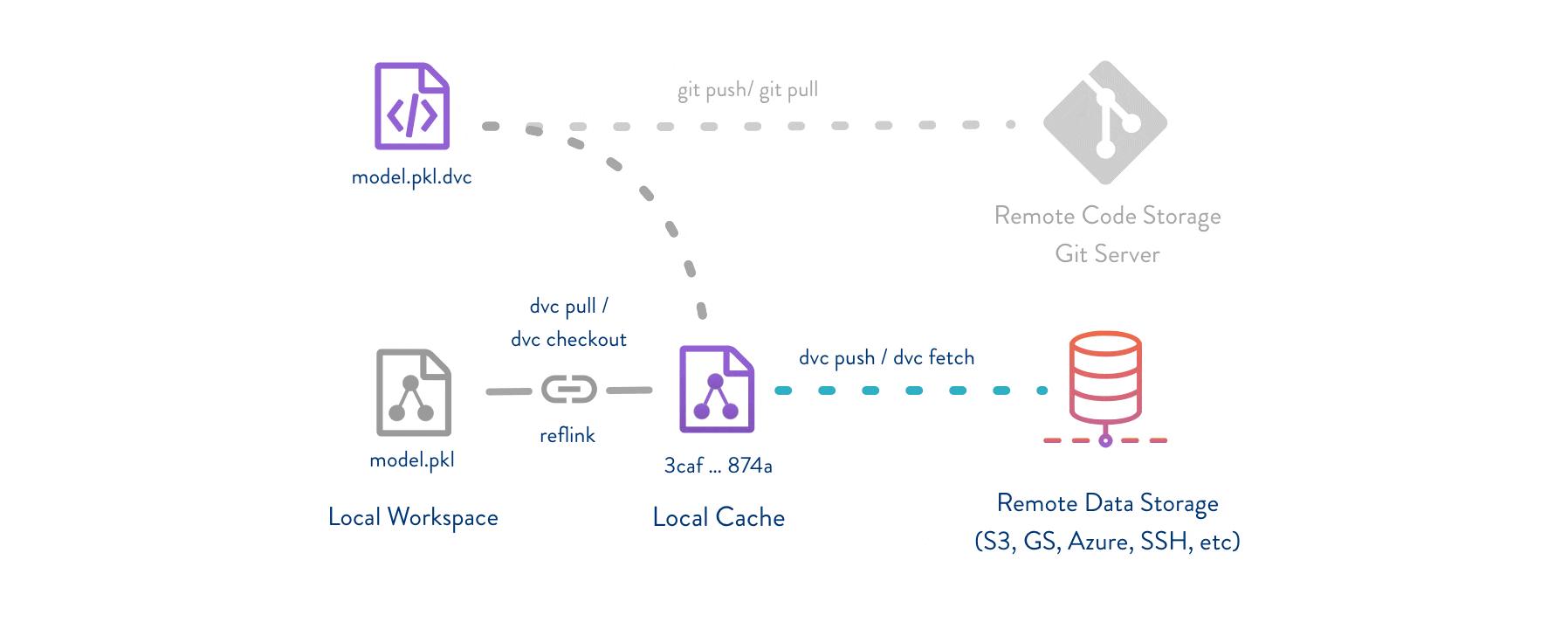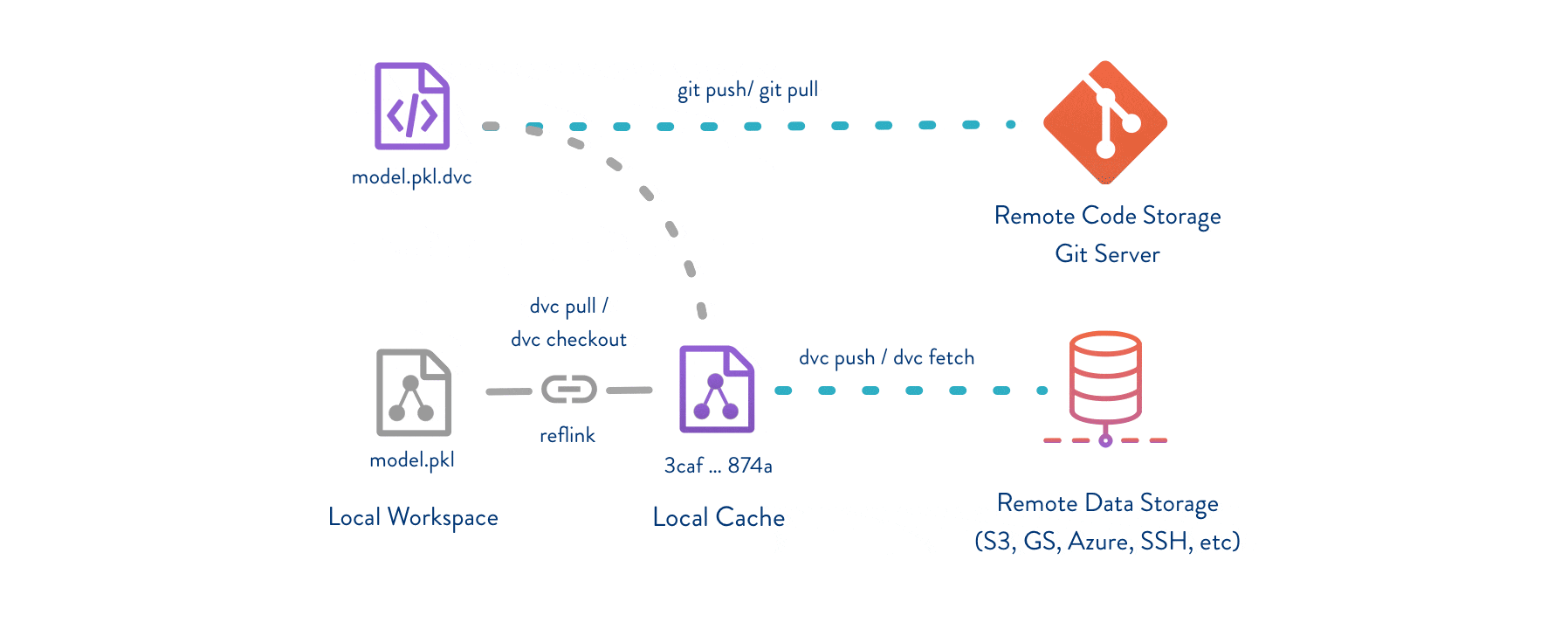
上图展示了DVC的基本工作流程,清晰地说明了代码、数据和模型之间的关系,以及DVC如何与Git和远程存储协同工作。
DVC的核心功能详解
1. 数据和模型版本控制
DVC为数据科学项目带来了类似Git的版本控制体验。它允许用户:
- 跟踪大型数据集和模型文件的变化
- 在不同版本的数据和模型之间切换
- 将数据和模型与代码版本关联
这种方法解决了传统Git在处理大文件时的限制,同时保持了版本控制的优势。
2. 可重复的数据管道
DVC引入了管道的概念,用于定义数据处理和模型训练的步骤:
- 使用简单的YAML格式定义管道
- 自动检测变更并只重新运行受影响的步骤
- 确保实验的可重复性
这种方法大大提高了数据科学工作流的效率和可靠性。
3. 实验跟踪和比较
DVC提供了强大的实验管理功能:
- 在本地Git仓库中跟踪实验
- 比较不同实验的参数、指标和结果
- 可视化实验结果
这使得数据科学家可以更容易地管理和分析大量实验。
4. 协作和共享
DVC支持团队协作:
- 使用现有的Git托管服务分享代码
- 通过远程存储共享数据和模型
- 轻松复现他人的实验
这大大提高了团队协作的效率和项目的可重复性。
DVC的实际应用
让我们通过一个简单的工作流程来了解DVC在实际项目中的应用:
-
跟踪数据:
$ git add train.py params.yaml $ dvc add images/这将数据文件添加到DVC的版本控制中。
-
定义数据处理管道:
$ dvc stage add -n featurize -d images/ -o features/ python featurize.py $ dvc stage add -n train -d features/ -d train.py -o model.p -M metrics.json python train.py这定义了特征提取和模型训练的管道。
-
运行实验:
$ dvc exp run -n exp-baseline $ vi train.py $ dvc exp run -n exp-code-change这运行了基线实验和修改后的实验。
-
比较实验结果:
$ dvc exp show $ dvc exp apply exp-baseline这显示了实验结果的比较,并应用了选定的实验。
-
共享代码和数据:
$ git add . $ git commit -m 'The baseline model' $ git push $ dvc remote add myremote -d s3://mybucket/image_cnn $ dvc push这将代码推送到Git仓库,并将数据推送到远程存储。
通过这个工作流程,我们可以看到DVC如何无缝地集成到数据科学项目中,提供版本控制、实验管理和协作功能。
DVC的优势和特点
-
开源和灵活: DVC是一个开源项目,可以根据特定需求进行定制和扩展。
-
与现有工具集成: DVC可以与Git、各种云存储服务以及常用的数据科学工具无缝集成。
-
语言无关: 虽然DVC是用Python编写的,但它可以用于任何编程语言的项目。
-
轻量级: DVC不需要复杂的服务器设置,可以在本地机器上运行。
-
可扩展性: 从个人项目到大型团队协作,DVC都能很好地适应。
-
促进最佳实践: DVC鼓励使用可重复的工作流程和版本控制,这有助于提高项目质量。
DVC的安装和使用
DVC提供了多种安装方式,适应不同的操作系统和用户偏好:
-
对于Linux用户,可以使用Snapcraft:
snap install dvc --classic -
Windows用户可以使用Chocolatey:
choco install dvc -
macOS用户可以使用Homebrew:
brew install dvc -
对于Python用户,可以使用pip:
pip install dvc
安装完成后,就可以开始使用DVC了。DVC的基本命令与Git类似,使得学习曲线相对平缓。
DVC的未来发展
作为一个活跃的开源项目,DVC正在不断发展和改进。未来的发展方向可能包括:
- 更强大的可视化工具
- 更深入的云集成
- 更多的自动化功能
- 对大规模分布式系统的更好支持
随着数据科学和机器学习领域的不断发展,DVC也将继续演进,以满足不断变化的需求。
结论
DVC为数据科学和机器学习项目带来了革命性的变化。通过提供强大的版本控制、实验管理和协作工具,DVC帮助数据科学家和机器学习工程师更有效地管理他们的工作流程。无论是个人项目还是大型团队协作,DVC都能提供所需的功能和灵活性。
随着数据驱动决策在各个行业变得越来越重要,像DVC这样的工具将在确保数据科学项目的可重复性、可追溯性和协作效率方面发挥关键作用。对于任何严肃的数据科学团队来说,探索和采用DVC都是一个值得考虑的选择。
通过使用DVC,数据科学家可以专注于他们的核心工作 - 从数据中获取洞察力和构建模型,而不必担心版本控制和协作的复杂性。这不仅提高了工作效率,还提升了整个数据科学过程的质量和可靠性。
在数据科学和机器学习继续改变世界的过程中,DVC无疑将成为这一革命中的重要工具之一。🚀🔬📊












