
EAGLE: 大语言模型推理速度的突破性进展
在人工智能和自然语言处理领域,大语言模型(LLM)的发展日新月异。然而,这些模型的规模越来越大,推理速度成为一个亟待解决的问题。近期,SafeAI实验室推出的EAGLE (Extrapolation Algorithm for Greater Language-model Efficiency)技术为这一问题提供了一个创新的解决方案。EAGLE不仅大幅提升了LLM的推理效率,还保证了生成文本分布的一致性,为大语言模型的实际应用开辟了新的可能。
EAGLE的核心理念与技术创新
EAGLE的核心思想是通过外推大语言模型的第二顶层上下文特征向量来加速解码过程。这种方法不仅在理论上保证了与原始模型生成文本分布的一致性,还在实践中取得了显著的性能提升。
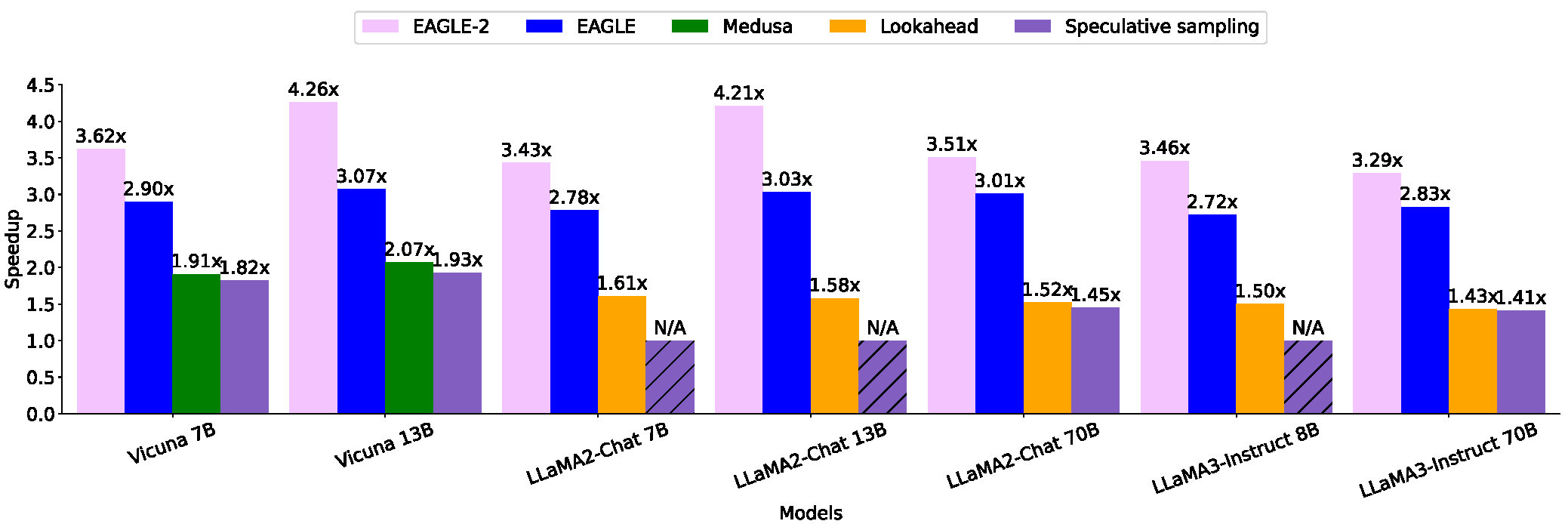
根据第三方评估,EAGLE被认证为目前最快的推测方法。它在13B参数规模的模型上能够实现比普通解码快3倍的速度,比Lookahead方法快2倍,比Medusa方法快1.6倍。这些数据充分展示了EAGLE在大语言模型推理加速方面的卓越表现。
EAGLE的另一个显著优势是其广泛的适用性。它可以与其他并行技术如vLLM、DeepSpeed、Mamba、FlashAttention、量化和硬件优化等结合使用,进一步提升性能。这种灵活性使得EAGLE能够适应不同的应用场景和硬件环境。
EAGLE-2: 更进一步的性能提升
在EAGLE的基础上,研究团队又推出了EAGLE-2。这个升级版本利用草稿模型的置信度分数来近似接受率,动态调整草稿树结构,从而进一步提高了性能。EAGLE-2在13B参数规模的模型上比普通解码快4倍,比EAGLE-1快1.4倍。

值得注意的是,使用EAGLE-2,在2个RTX 3060 GPU上的推理速度甚至可以超过在A100 GPU上的普通自回归解码速度。这一成果对于希望在有限计算资源条件下部署大语言模型的研究者和开发者来说无疑是一个好消息。
EAGLE的实际应用与使用
EAGLE提供了多种使用方式,以满足不同用户的需求。对于希望快速体验EAGLE的用户,可以使用提供的Web界面。只需运行以下命令:
python -m eagle.application.webui --ea-model-path [path of EAGLE weight] \
--base-model-path [path of the original model] \
--model-type [vicuna\llama2\llama3] \
--total-token [int]
对于希望在自己的代码中集成EAGLE的开发者,可以使用"eagenerate"函数来加速生成过程。以下是一个简单的示例:
from eagle.model.ea_model import EaModel
from fastchat.model import get_conversation_template
model = EaModel.from_pretrained(
base_model_path=base_model_path,
ea_model_path=EAGLE_model_path,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto",
total_token=-1
)
model.eval()
your_message="Hello"
conv = get_conversation_template("vicuna")
conv.append_message(conv.roles[0], your_message)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids=model.tokenizer([prompt]).input_ids
input_ids = torch.as_tensor(input_ids).cuda()
output_ids=model.eagenerate(input_ids,temperature=0.5,max_new_tokens=512)
output=model.tokenizer.decode(output_ids[0])
EAGLE的训练与自定义
对于希望在自己的数据上训练EAGLE的研究者,EAGLE提供了完整的训练流程。首先生成训练数据:
python -m eagle.ge_data.allocation --outdir [path of data]
然后训练自回归头:
accelerate launch -m --mixed_precision=bf16 eagle.train.main --tmpdir [path of data] \
--cpdir [path of checkpoints] --configpath [path of config file]
EAGLE还支持使用DeepSpeed进行训练,以进一步提高训练效率。
EAGLE的评估与性能测试
为了方便用户评估EAGLE的性能,项目提供了在MT-bench上测试EAGLE速度的命令:
python -m eagle.evaluation.gen_ea_answer_vicuna(or gen_ea_answer_vicuna_llama2chat) \
--ea-model-path [path of EAGLE weight] \
--base-model-path [path of the original model] \
通过比较EAGLE和普通自回归的速度,用户可以得到具体的加速比。
EAGLE的未来发展
EAGLE团队正在积极开发新的功能和改进。未来的计划包括:
- 支持非贪婪推理(保证文本分布一致性)
- 支持更多LLM,如Mixtral 8x7B
- 支持LLaMA-3
- 支持Qwen-2
这些计划显示了EAGLE团队对技术持续优化和拓展应用范围的承诺。
结语
EAGLE和EAGLE-2的出现无疑为大语言模型的高效推理提供了一个强有力的解决方案。它不仅显著提高了推理速度,还保证了生成质量,为大语言模型在实际应用中的部署提供了新的可能。随着技术的不断优化和应用范围的扩大,我们有理由相信EAGLE将在大语言模型推理加速领域发挥越来越重要的作用,推动自然语言处理技术向前发展。
对于有兴趣深入了解EAGLE技术细节和完整实验结果的读者,可以参考EAGLE的论文和EAGLE-2的论文。EAGLE项目欢迎来自社区的贡献,无论是代码贡献、问题反馈还是新的想法,都将推动这项技术的进一步发展。让我们共同期待EAGLE在大语言模型推理加速领域带来的更多突破和创新。









