Marker: 将PDF快速转换为Markdown的利器
在当今数字化时代,PDF (Portable Document Format) 作为一种通用的文档格式被广泛使用。然而,PDF文件往往难以编辑和转换,特别是当我们需要将其内容转换为更易于处理的格式时。这就是Marker项目诞生的背景。Marker是一个强大的开源工具,旨在快速、准确地将PDF文档转换为Markdown格式。
Marker的主要特点
Marker具有以下几个突出的特点:
-
广泛的文档支持: Marker针对各种类型的文档进行了优化,特别是书籍和科学论文。无论是复杂的学术文献还是图文并茂的教科书,Marker都能够出色地处理。
-
多语言支持: 作为一个真正的国际化工具,Marker支持所有语言的文档转换,没有语言障碍。
-
智能清理: Marker能够自动移除页眉、页脚和其他干扰元素,确保输出的Markdown文本整洁有序。
-
格式保留: 对于表格和代码块等特殊格式,Marker能够很好地进行识别和转换,保持原文档的结构。
-
图像提取: Marker不仅转换文本,还能提取并保存文档中的图像,使转换后的Markdown更加完整。
-
公式转换: 对于包含数学公式的文档,Marker能将大部分公式转换为LaTeX格式,便于在Markdown中呈现。
-
灵活的硬件支持: Marker可以在GPU、CPU或MPS (Mac专用图形处理器) 上运行,适应不同的硬件环境。
Marker的工作原理
Marker采用了一系列深度学习模型构建的管道来实现PDF到Markdown的转换:
-
文本提取与OCR: 首先,Marker会尝试直接从PDF中提取文本。如果需要,它会使用OCR (光学字符识别) 技术来识别图像中的文字。这一步骤主要依赖heuristics方法、surya项目和tesseract OCR引擎。
-
页面布局检测: 使用surya项目来分析页面布局并确定阅读顺序,这对于处理多列布局的文档尤为重要。
-
文本块清理与格式化: 对每个识别出的文本块进行清理和格式化,这一步骤结合了heuristics方法和texify项目的能力。
-
文本组合与后处理: 最后,将所有处理过的文本块组合起来,并使用heuristics方法和pdf_postprocessor模型进行全文后处理。
Marker的设计理念是只在必要时使用复杂的模型,这种方法不仅提高了处理速度,还提升了转换的准确性。
使用Marker
要开始使用Marker,首先需要安装Python 3.9+和PyTorch。安装过程相对简单:
pip install marker-pdf
Marker提供了几种使用方式:
-
交互式应用: 通过运行
marker_gui命令,可以启动一个基于Streamlit的交互式应用,让用户可以直观地尝试Marker的功能。 -
单文件转换: 使用
marker_single命令可以转换单个PDF文件:
marker_single /path/to/file.pdf /path/to/output/folder --batch_multiplier 2 --max_pages 10
- 批量转换: 使用
marker命令可以批量转换多个PDF文件:
marker /path/to/input/folder /path/to/output/folder --workers 4 --max 10 --min_length 10000
- 多GPU并行处理: 对于拥有多个GPU的用户,Marker提供了
marker_chunk_convert脚本,可以充分利用多GPU资源进行高效转换。
Marker的性能表现
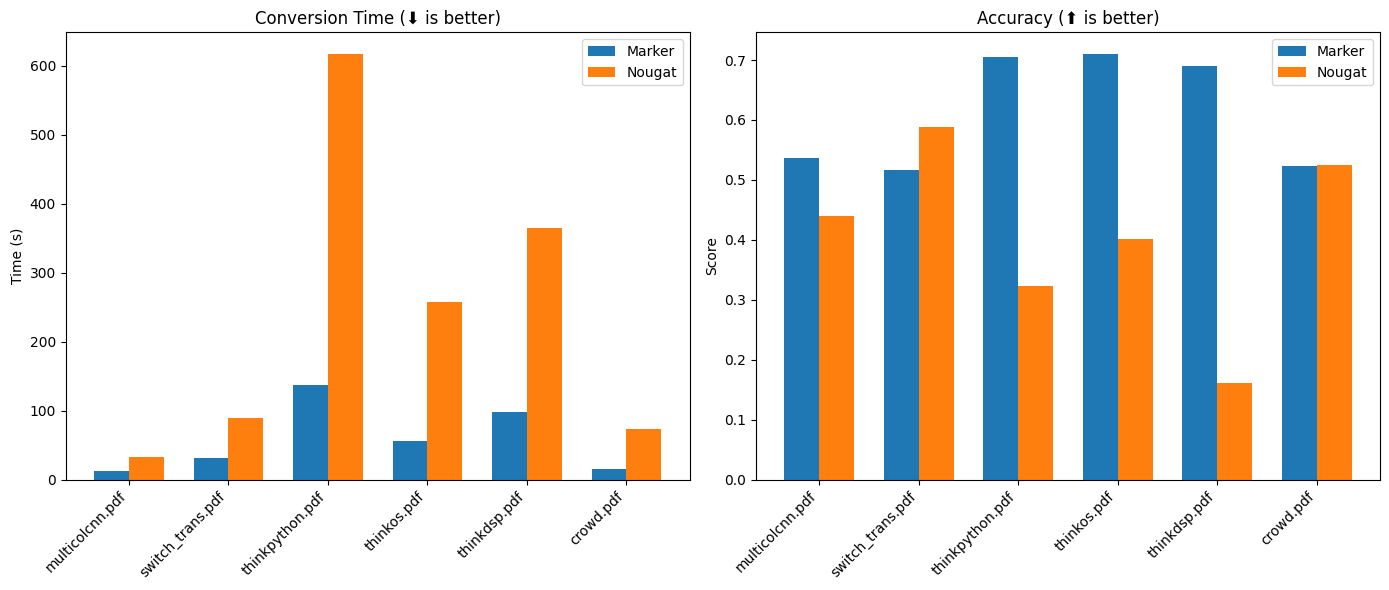
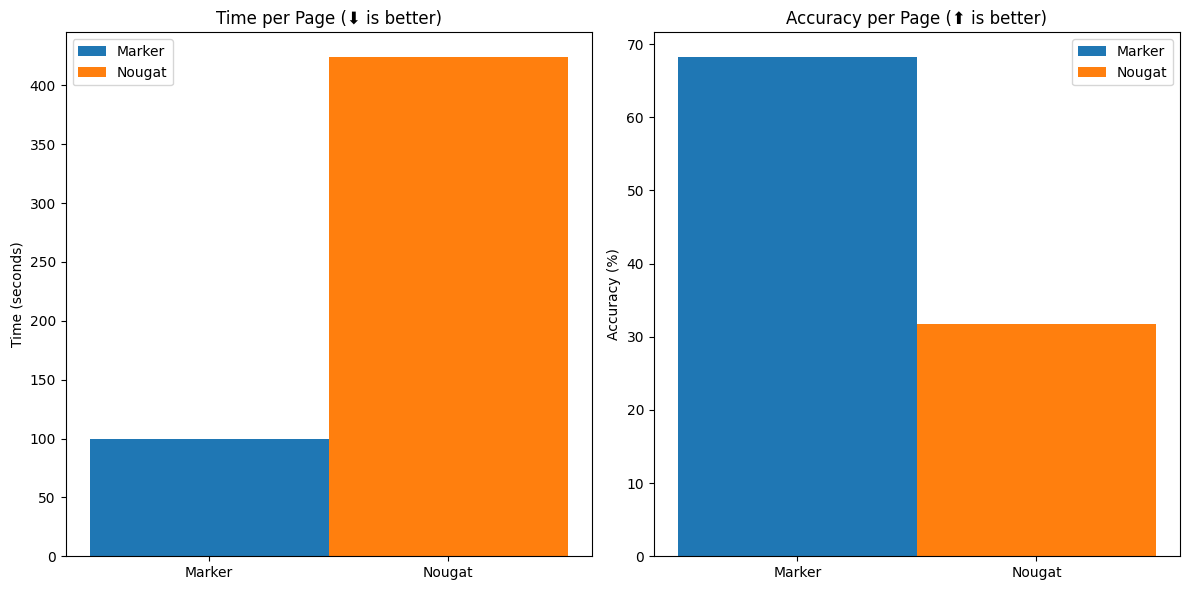
Marker在速度和准确性方面都表现出色。根据基准测试结果,Marker比类似工具Nougat快4倍,并且在非arXiv数据集上的准确性更高。
- 速度: Marker平均每页处理时间为0.63秒,而Nougat需要2.59秒。
- 准确性: 在多种类型的文档测试中,Marker的平均得分为0.61,而Nougat为0.41。
- 内存使用: Marker在处理过程中的峰值GPU内存使用约为4.1GB,与Nougat的4.2GB相当。
这些数据显示,Marker不仅能够快速处理文档,还能保持较高的转换质量,特别是在处理复杂布局和多语言文档时。
Marker的应用场景
Marker的优秀性能和丰富功能使其在多个领域都有广泛的应用前景:
-
学术研究: 研究人员可以使用Marker快速将PDF格式的论文转换为Markdown,便于进行文本分析、引用提取等工作。
-
内容管理: 出版社和内容创作者可以利用Marker将大量PDF文档批量转换为易于编辑和发布的Markdown格式。
-
数据挖掘: 数据科学家可以使用Marker从大量PDF文档中提取结构化数据,为后续的数据分析做准备。
-
知识管理: 企业可以使用Marker将PDF格式的文档库转换为Markdown,便于在知识管理系统中进行索引和检索。
-
教育领域: 教师和学生可以使用Marker将PDF教材转换为Markdown,便于制作笔记、提取重点内容等。
Marker的限制与未来发展
尽管Marker表现优秀,但开发者也坦承它仍有一些限制:
- 并非100%的数学公式都能被正确转换为LaTeX格式。
- 表格的格式转换有时可能不够精确,文本可能出现在错误的列中。
- 空白和缩进可能无法完全保留。
- 某些行或跨度可能无法正确连接。
- 对于需要大量OCR的扫描PDF文档,处理效果可能不如数字化PDF理想。
这些限制正是Marker项目未来的发展方向。开发团队计划进一步提高公式识别和转换的准确率,优化表格处理算法,改进空白和缩进的保留,以及增强OCR能力。
结语
Marker作为一个开源项目,不仅为用户提供了强大的PDF转Markdown工具,还为整个开源社区贡献了宝贵的技术。它的成功离不开众多优秀的开源模型和数据集,如Surya、Texify、Pypdfium2/pdfium、IBM的DocLayNet和Google的ByT5等。
对于那些需要经常处理PDF文档的个人和组织来说,Marker无疑是一个值得尝试的工具。它不仅可以节省大量的时间和精力,还能保持较高的转换质量。随着项目的不断发展和社区的持续贡献,我们有理由相信Marker将在PDF转Markdown领域扮演越来越重要的角色。
如果你对Marker感兴趣,可以访问其GitHub仓库了解更多信息,或者加入其Discord社区参与讨论。无论你是开发者、研究人员还是普通用户,Marker都欢迎你的参与和贡献,共同推动这个优秀工具的发展。