
引言
在当今数字化时代,语音转写技术已成为信息处理的重要工具。faster-whisper-GUI 作为一款基于 PySide6 开发的图形用户界面软件,为 faster-whisper 和 whisperX 这两个强大的语音识别模型提供了一个直观、易用的操作平台。本文将深入探讨 faster-whisper-GUI 的特性、功能和使用方法,帮助用户充分发挥其在语音转写领域的潜力。
faster-whisper-GUI 概述
faster-whisper-GUI 是一个开源项目,旨在为用户提供一个便捷的图形界面来使用 faster-whisper 和 whisperX 模型进行语音转写。该软件集成了多项先进功能,包括音频和视频文件的转写、VAD(语音活动检测)模型和 whisper 模型的参数调整、批量处理、Demucs 音频分离等。
主要特性
1. 多语言支持和主题定制
faster-whisper-GUI 提供了多语言界面,支持中英文切换,方便不同地区的用户使用。同时,软件还支持主题颜色的自定义,让用户可以根据个人喜好调整界面风格。
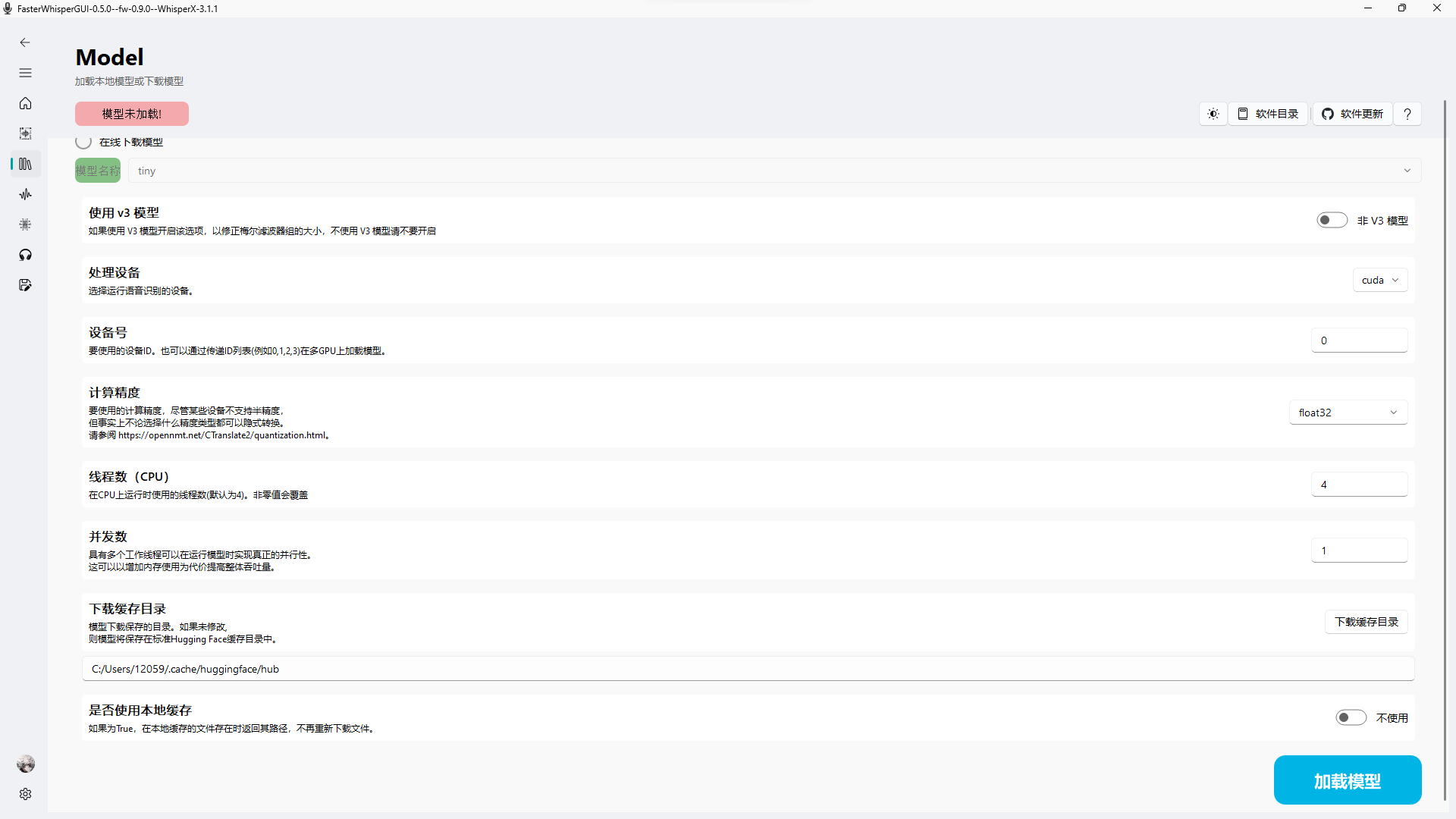
2. 模型管理
用户可以方便地加载、下载和转换模型。软件支持从 Hugging Face 下载模型,也可以加载本地模型。特别值得一提的是,faster-whisper-GUI 支持最新的 Whisper large-v3 模型,为用户提供更高精度的转写结果。
3. 音频处理功能
集成了 Demucs 音频分离功能,可以将人声与背景音乐分离,提高转写的准确性。这对于处理包含背景音乐的音频文件特别有用。
4. 批量处理
软件支持批量处理功能,用户可以一次性添加多个文件进行转写,大大提高了工作效率。
5. 文件管理系统
内置了文件列表和文件过滤功能,方便用户管理和选择需要处理的文件。
6. WhisperX 集成
除了 faster-whisper,软件还集成了 WhisperX 功能,为用户提供更多选择。
7. 参数调整
提供了丰富的参数设置选项,包括 faster-whisper 模型参数和 Silero VAD 参数,让专业用户能够根据具体需求fine-tune转写过程。
8. 结果展示和编辑
转写完成后,软件提供了结果展示界面,用户可以查看和编辑时间戳,确保输出的准确性。
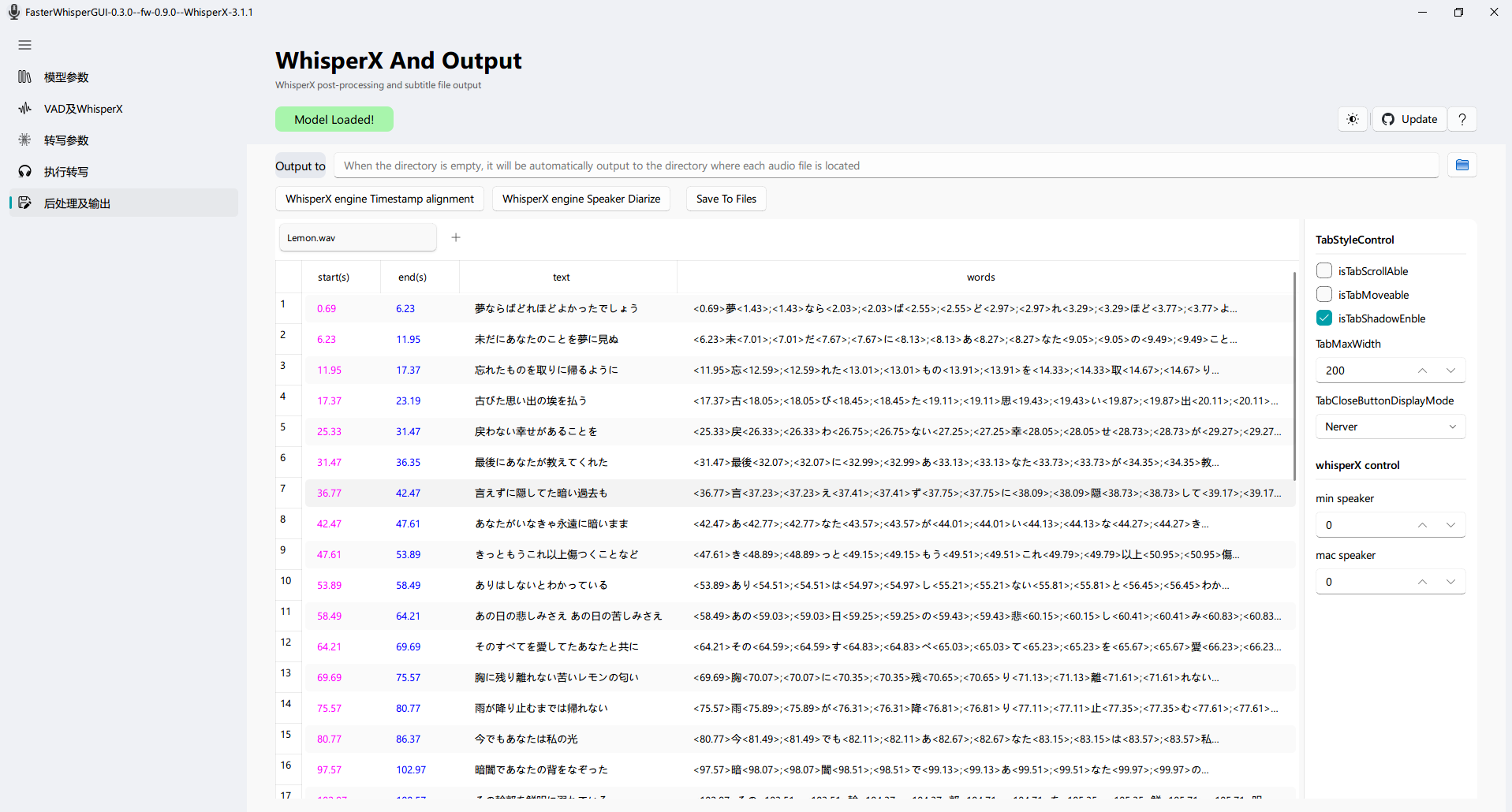
9. 多种输出格式
支持将转写结果输出为 SRT、TXT、SMI、VTT、LRC 等多种格式,满足不同场景的需求。特别是对于 VTT、LRC 和 SMI 格式,软件还支持词级时间戳,可用于制作卡拉OK字幕。
使用指南
安装和配置
- 从 GitHub 仓库下载 faster-whisper-GUI。
- 安装所需依赖,可以通过
pip install -r requirements.txt完成。 - 下载所需的模型文件,可以使用软件内置的下载功能或手动下载。
基本使用流程
- 启动软件,选择要使用的模型。
- 添加需要转写的音频或视频文件。
- 调整转写参数(如需要)。
- 点击开始转写。
- 等待转写完成,查看和编辑结果。
- 导出所需格式的转写文件。
高级功能探索
使用 Demucs 进行音频分离
对于包含背景音乐的音频,可以使用 Demucs 功能先进行音频分离,然后再进行转写,以提高准确率。
利用 WhisperX 功能
WhisperX 提供了更精确的时间戳和说话人分离功能,对于多人对话的音频特别有用。
批量处理大量文件
对于需要处理大量文件的用户,可以充分利用批量处理功能,提高工作效率。
自定义转写参数
对于有特殊需求的用户,可以深入研究并调整 faster-whisper 和 VAD 模型的参数,以获得最佳的转写效果。
注意事项
使用 faster-whisper-GUI 时,用户需要注意以下几点:
- 确保遵守相关法律法规,不要用于非法用途。
- 对于大文件或批量处理,请确保计算机有足够的性能和存储空间。
- 定期更新软件和模型,以获得最新的功能和改进。
结语
faster-whisper-GUI 为用户提供了一个强大而易用的语音转写工具。无论是个人用户还是专业团队,都能从这款软件中受益。随着语音识别技术的不断进步,我们可以期待 faster-whisper-GUI 在未来会带来更多创新功能,进一步提升语音转写的效率和准确性。
通过深入了解和熟练使用 faster-whisper-GUI,用户可以大大提高语音转写的效率和质量,为各种需要语音转文字的场景提供有力支持。无论是学术研究、媒体制作还是商业应用,faster-whisper-GUI 都是一个值得尝试的优秀工具。
让我们期待 faster-whisper-GUI 在语音转写领域继续发光发热,为用户带来更多便利和可能性。同时,也鼓励更多开发者参与到这个开源项目中来,共同推动语音识别技术的发展与应用。









