
TTS简介:开源的文本转语音利器
TTS(Text-to-Speech)是由Coqui.ai开发的一个开源深度学习文本转语音工具包。作为一个功能强大且经过实战检验的项目,TTS为研究人员和开发者提供了先进的语音合成能力。自发布以来,TTS在GitHub上已获得超过33,000颗星,成为该领域最受欢迎的开源项目之一。
TTS的目标是为语音合成任务提供高性能的深度学习模型。它不仅包含了多种先进的文本到语音模型,还提供了语音编码器和声码器模型,使得整个语音合成流程得以完整实现。TTS支持多种语言和多说话人的语音合成,并提供了灵活的训练和推理接口,方便用户进行定制化开发。
TTS的主要特性
TTS作为一个综合性的语音合成工具包,具有以下主要特性:
-
多样化的模型实现:TTS实现了多种先进的文本到语谱图模型,如Tacotron、Tacotron2、Glow-TTS、SpeedySpeech等。同时还提供了多种声码器模型,如MelGAN、HiFiGAN、WaveRNN等。
-
高效的训练框架:TTS提供了快速高效的模型训练功能,支持详细的训练日志输出和TensorBoard可视化。
-
多语言多说话人支持:TTS支持多语言和多说话人的语音合成,能够满足不同场景的需求。
-
灵活的API:TTS提供了高效、灵活且轻量级的Trainer API,方便用户进行模型训练和定制。
-
预训练模型:TTS提供了多个已发布的预训练模型,用户可以直接使用这些模型进行语音合成。
-
数据集分析工具:TTS包含了用于分析和整理文本到语音数据集的工具。
-
实用工具:TTS提供了多种实用工具,用于使用和测试模型。
-
模块化设计:TTS采用模块化的代码结构,便于实现新的想法和扩展功能。
TTS支持的模型
TTS实现了多种先进的语音合成模型,主要包括以下几类:
谱图模型
- Tacotron和Tacotron2:这两个模型是序列到序列的语音合成模型,能够直接从文本生成梅尔频谱图。
- Glow-TTS:基于流的生成模型,具有快速并行推理的能力。
- SpeedySpeech:一种非自回归的快速语音合成模型。
- FastPitch:结合了FastSpeech的并行生成能力和Pitch预测的模型。
- FastSpeech和FastSpeech2:非自回归的快速语音合成模型。
端到端模型
- ⓍTTS:Coqui.ai最新发布的多语言语音克隆模型。
- VITS:结合了变分推理和对抗学习的端到端语音合成模型。
- YourTTS:支持零样本跨语言语音克隆的模型。
注意力机制
TTS还实现了多种注意力机制,如引导注意力、前向后向解码、Graves注意力等,以提高模型的对齐能力和合成质量。
语音编码器
TTS提供了GE2E和Angular Loss两种语音编码器,用于提取说话人的特征嵌入。
声码器
TTS实现了多种声码器模型,包括MelGAN、MultiBandMelGAN、HiFiGAN、WaveRNN等,用于将频谱图转换为波形。
使用TTS进行语音合成
TTS提供了简单易用的Python API和命令行工具,方便用户进行语音合成。以下是一些基本的使用示例:
Python API
使用Python API可以轻松地进行语音合成:
from TTS.api import TTS
# 初始化TTS
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2").to("cuda")
# 生成语音
tts.tts_to_file(text="Hello world!", speaker_wav="my/speaker.wav", language="en", file_path="output.wav")
命令行工具
TTS还提供了命令行工具,可以直接在终端中使用:
tts --text "Hello world!" --model_name "tts_models/en/ljspeech/tacotron2-DDC" --out_path output.wav
TTS的安装和部署
TTS支持通过pip安装或从源码安装。对于只需要使用预训练模型进行语音合成的用户,可以直接通过pip安装:
pip install TTS
对于需要进行开发或训练自己模型的用户,建议从源码安装:
git clone https://github.com/coqui-ai/TTS
pip install -e .[all,dev,notebooks]
TTS还提供了Docker镜像,方便用户快速部署和使用:
docker run --rm -it -p 5002:5002 ghcr.io/coqui-ai/tts-cpu
TTS的未来发展
作为一个活跃的开源项目,TTS正在不断发展和改进。最近的一些重要更新包括:
- 发布了ⓍTTSv2,支持16种语言,性能全面提升。
- 开源了ⓍTTS的微调代码。
- ⓍTTS现在可以实现低至200ms延迟的流式合成。
- 集成了Bark模型,支持无约束的语音克隆。
未来,TTS团队计划继续改进模型性能,增加对更多语言的支持,并探索新的语音合成技术。
结语
TTS作为一个功能强大、易于使用的开源文本转语音工具包,为研究人员和开发者提供了丰富的资源和工具。无论是进行学术研究还是开发实际应用,TTS都是一个值得考虑的选择。随着语音技术的不断发展,我们期待看到TTS在未来带来更多创新和突破。
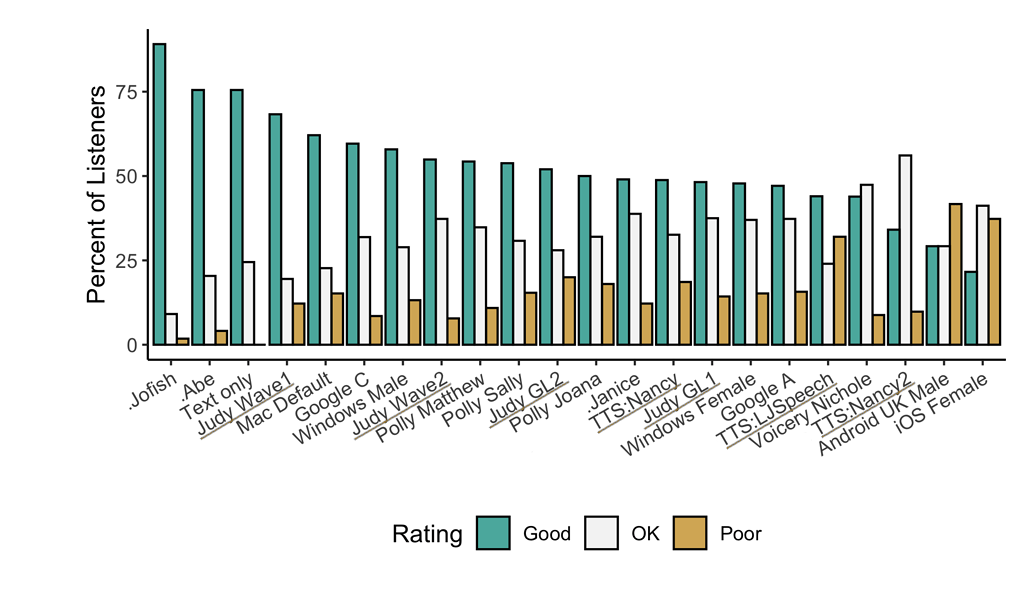
图1:TTS与其他语音合成系统的性能对比
通过持续的开发和社区贡献,TTS正在推动语音合成技术的边界,为创造更自然、更个性化的语音体验铺平道路。无论您是语音技术的研究者、开发者还是爱好者,TTS都为您提供了一个强大的工具和平台,让您能够探索和实现各种创新的语音合成应用。









