
FairScale简介
随着深度学习模型规模的不断扩大,如何高效训练大规模模型已成为人工智能领域的一个重要挑战。为了解决这一问题,Facebook Research团队开发并开源了FairScale库。FairScale是一个基于PyTorch的扩展库,旨在为高性能和大规模模型训练提供先进的分布式训练技术。
FairScale的设计理念包括:
- 易用性 - 提供简单直观的API,降低使用门槛
- 模块化 - 允许灵活组合多种训练技术
- 高性能 - 在扩展性和效率方面追求卓越表现
通过这些设计,FairScale使研究人员能够更轻松地尝试和应用最新的分布式训练方法,从而突破计算资源限制,实现更大规模模型的训练。
核心特性
FairScale提供了多项强大的分布式训练功能:
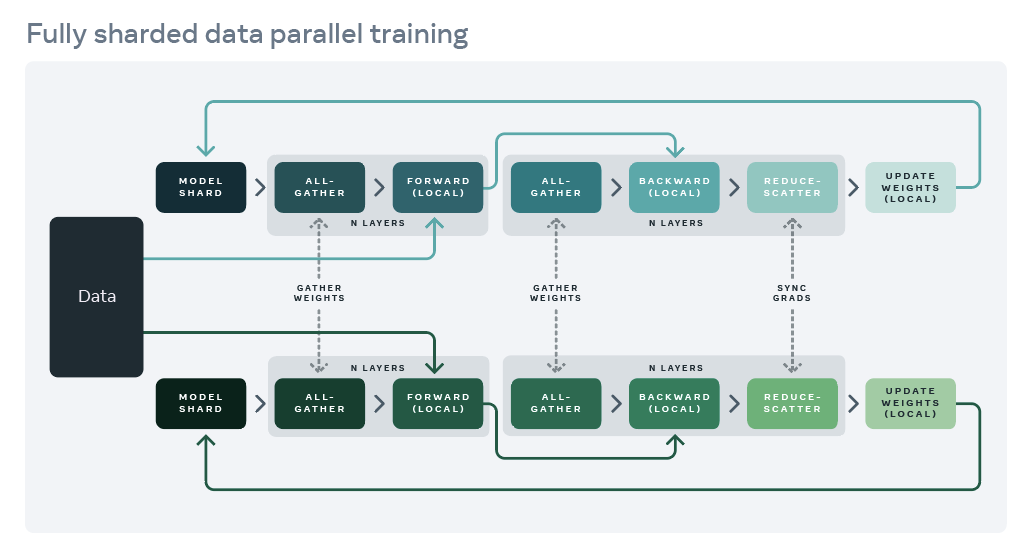
1. 完全分片数据并行(FSDP)
FSDP是FairScale最重要的特性之一。它通过将模型参数分片到多个GPU上,大幅降低了单个设备的内存需求,使得训练超大规模模型成为可能。FSDP的主要优势包括:
- 内存效率:每个GPU只存储部分模型参数,显著降低内存占用
- 通信效率:采用高效的all-gather和reduce-scatter操作
- 计算/通信重叠:在前向和反向传播过程中重叠计算和通信
值得一提的是,FSDP已被整合进PyTorch主框架,这充分说明了其重要性和实用价值。
2. 流水线并行(Pipeline Parallelism)
流水线并行将模型在不同设备间进行垂直切分,形成一个处理流水线。这种方法可以:
- 减少设备间通信开销
- 提高硬件利用率
- 支持超大模型训练
FairScale的流水线并行实现基于torchgpipe,并进行了优化。
3. 模型并行(Model Parallelism)
对于某些超大模型,即使采用FSDP也难以在单个GPU上完整加载。FairScale提供了模型并行功能,可将模型的不同部分分布到多个设备上。这种方法源自Megatron-LM项目,适用于Transformer等大型模型。
4. 优化器状态分片(Optimizer State Sharding)
优化器状态(如Adam的动量)往往占用大量内存。FairScale实现了优化器状态分片,将状态分散到多个设备上,从而节省内存并支持更大批量。
5. 激活检查点(Activation Checkpointing)
通过在前向传播时选择性地保存中间激活,激活检查点技术可以在内存和计算之间进行权衡,为大模型训练提供更多灵活性。
使用方法
FairScale的使用非常简单,只需几行代码即可将现有PyTorch模型转换为分布式训练版本。以下是一个使用FSDP的简单示例:
import torch
from fairscale.nn.data_parallel import FullyShardedDataParallel as FSDP
# 定义模型
model = MyLargeModel()
# 包装模型
sharded_model = FSDP(model)
# 正常训练流程
optimizer = torch.optim.Adam(sharded_model.parameters(), lr=0.001)
for data, target in dataloader:
output = sharded_model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
FairScale还支持更细粒度的控制,如单独对某些层应用FSDP:
from fairscale.nn.wrap import wrap, enable_wrap, auto_wrap
with enable_wrap(wrapper_cls=FSDP):
layer1 = auto_wrap(nn.Linear(100, 1000))
layer2 = auto_wrap(nn.Linear(1000, 10))
model = nn.Sequential(layer1, layer2)
性能评估
FairScale在多项基准测试中展现了优异的性能。以BERT-Large模型为例,使用FSDP可以将训练速度提升2倍以上,同时将GPU内存使用降低75%。这意味着研究人员可以在相同硬件条件下训练更大的模型或使用更大的批量。

结语
FairScale为PyTorch生态系统带来了一系列先进的分布式训练技术,大大拓展了研究人员和工程师探索大规模模型的能力。随着AI模型规模的持续增长,FairScale无疑将在未来的深度学习研究和应用中发挥越来越重要的作用。
作为一个开源项目,FairScale也欢迎社区贡献。无论是提出新想法、报告问题还是提交代码,都可以通过GitHub参与到FairScale的开发中来。让我们共同推动大规模机器学习的发展,为AI领域的突破贡献力量。









